







Paper
Anomaly Detection on Attributed Networks via Contrastive Self-Supervised Learnin
Requirements
python == 3.8
pytorch == 1.8.1+cu111
networkx == 2.5.1
scikit-learn >= 0.24.1
DGL == 0.4.3
DGL不要用超过0.4版本的。注意DGL的安装,服务器上直接使用pip install dgl==0.4.3进行安装,
本地可以安装支持CUDA 的DGL,例如pip install dgl -cu111
import dgl
print(dgl.__version__)
代码实现
异常注入
inject_anomaly.py
inject_anomaly.py注入异常过程,处理原始数据集,并添加结构和属性扰动,注入结构属性异常。
import numpy as np
import scipy.sparse as sp
import random
import scipy.io as sio
import argparse
import pickle as pkl
import networkx as nx
import sys
import os
import os.path as osp
from sklearn import preprocessing
from scipy.spatial.distance import euclidean
def dense_to_sparse(dense_matrix):
shape = dense_matrix.shape
row = []
col = []
data = []
for i, r in enumerate(dense_matrix):
for j in np.where(r > 0)[0]:
row.append(i)
col.append(j)
data.append(dense_matrix[i,j])
sparse_matrix = sp.coo_matrix((data, (row, col)), shape=shape).tocsc()
return sparse_matrix
def parse_index_file(filename):
"""Parse index file."""
index = []
for line in open(filename):
index.append(int(line.strip()))
return index
def load_citation_datadet(dataset_str):
names = ['x', 'y', 'tx', 'ty', 'allx', 'ally', 'graph']
objects = []
for i in range(len(names)):
with open("raw_dataset/{}/ind.{}.{}".format(dataset_str, dataset_str, names[i]), 'rb') as f:
if sys.version_info > (3, 0):
objects.append(pkl.load(f, encoding='latin1'))
else:
objects.append(pkl.load(f))
x, y, tx, ty, allx, ally, graph = tuple(objects)
test_idx_reorder = parse_index_file("raw_dataset/{}/ind.{}.test.index".format(dataset_str, dataset_str))
test_idx_range = np.sort(test_idx_reorder)
if dataset_str == 'citeseer':
# Fix citeseer dataset (there are some isolated nodes in the graph)
# Find isolated nodes, add them as zero-vecs into the right position
test_idx_range_full = range(min(test_idx_reorder), max(test_idx_reorder)+1)
tx_extended = sp.lil_matrix((len(test_idx_range_full), x.shape[1]))
tx_extended[test_idx_range-min(test_idx_range), :] = tx
tx = tx_extended
ty_extended = np.zeros((len(test_idx_range_full), y.shape[1]))
ty_extended[test_idx_range-min(test_idx_range), :] = ty
ty = ty_extended
features = sp.vstack((allx, tx)).tolil()
features[test_idx_reorder, :] = features[test_idx_range, :]
adj = nx.adjacency_matrix(nx.from_dict_of_lists(graph))
labels = np.vstack((ally, ty))
labels[test_idx_reorder, :] = labels[test_idx_range, :]
adj_dense = np.array(adj.todense(), dtype=np.float64)
attribute_dense = np.array(features.todense(), dtype=np.float64)
cat_labels = np.array(np.argmax(labels, axis = 1).reshape(-1,1), dtype=np.uint8)
return attribute_dense, adj_dense, cat_labels
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', type=str, default='cora') #'BlogCatalog' 'Flickr' 'cora' 'citeseer' 'pubmed'
parser.add_argument('--seed', type=int, default=1) #random seed
parser.add_argument('--m', type=int, default=15) #num of fully connected nodes
parser.add_argument('--n', type=int)
parser.add_argument('--k', type=int, default=50) #num of clusters
args = parser.parse_args()
AD_dataset_list = ['BlogCatalog', 'Flickr']
Citation_dataset_list = ['cora', 'citeseer', 'pubmed']
# Set hyperparameters of disturbing
dataset_str = args.dataset #'BlogCatalog' 'Flickr' 'cora' 'citeseer' 'pubmed'
seed = args.seed
m = args.m #num of fully connected nodes #10 15 20 5
k = args.k
if args.n is None:
if dataset_str == 'cora' or dataset_str == 'citeseer':
n = 5
elif dataset_str == 'BlogCatalog':
n = 10
elif dataset_str == 'Flickr':
n = 15
elif dataset_str == 'pubmed':
n = 20
else:
n = args.n
if __name__ == "__main__":
# Set seed
print('Random seed: {:d}. \n'.format(seed))
np.random.seed(seed)
random.seed(seed)
# Load data
print('Loading data: {}...'.format(dataset_str))
if dataset_str in AD_dataset_list:
data = sio.loadmat('./raw_dataset/{}/{}.mat'.format(dataset_str, dataset_str))
attribute_dense = np.array(data['Attributes'].todense())
attribute_dense = preprocessing.normalize(attribute_dense, axis=0)
adj_dense = np.array(data['Network'].todense())
cat_labels = data['Label']
elif dataset_str in Citation_dataset_list:
attribute_dense, adj_dense, cat_labels = load_citation_datadet(dataset_str)
ori_num_edge = np.sum(adj_dense)
num_node = adj_dense.shape[0]
print('Done. \n')
# Random pick anomaly nodes
all_idx = list(range(num_node))
random.shuffle(all_idx)
anomaly_idx = all_idx[:m*n*2]
structure_anomaly_idx = anomaly_idx[:m*n]
attribute_anomaly_idx = anomaly_idx[m*n:]
label = np.zeros((num_node,1),dtype=np.uint8)
label[anomaly_idx,0] = 1
str_anomaly_label = np.zeros((num_node,1),dtype=np.uint8)
str_anomaly_label[structure_anomaly_idx,0] = 1
attr_anomaly_label = np.zeros((num_node,1),dtype=np.uint8)
attr_anomaly_label[attribute_anomaly_idx,0] = 1
# Disturb structure
print('Constructing structured anomaly nodes...')
for n_ in range(n):
current_nodes = structure_anomaly_idx[n_*m:(n_+1)*m]
for i in current_nodes:
for j in current_nodes:
adj_dense[i, j] = 1.
adj_dense[current_nodes,current_nodes] = 0.
num_add_edge = np.sum(adj_dense) - ori_num_edge
print('Done. {:d} structured nodes are constructed. ({:.0f} edges are added) \n'.format(len(structure_anomaly_idx),num_add_edge))
# Disturb attribute
print('Constructing attributed anomaly nodes...')
for i_ in attribute_anomaly_idx:
picked_list = random.sample(all_idx, k)
max_dist = 0
for j_ in picked_list:
cur_dist = euclidean(attribute_dense[i_],attribute_dense[j_])
if cur_dist > max_dist:
max_dist = cur_dist
max_idx = j_
attribute_dense[i_] = attribute_dense[max_idx]
print('Done. {:d} attributed nodes are constructed. \n'.format(len(attribute_anomaly_idx)))
# Pack & save them into .mat
print('Saving mat file...')
attribute = dense_to_sparse(attribute_dense)
adj = dense_to_sparse(adj_dense)
savedir = 'dataset/'
if not os.path.exists(savedir):
os.makedirs(savedir)
sio.savemat('dataset/{}.mat'.format(dataset_str),\
{'Network': adj, 'Label': label, 'Attributes': attribute,\
'Class':cat_labels, 'str_anomaly_label':str_anomaly_label, 'attr_anomaly_label':attr_anomaly_label})
print('Done. The file is save as: dataset/{}.mat \n'.format(dataset_str))
异常检测
utils.py
utils.py中
"""
FileName:
Author:
Version:
Date: 2024/6/1122:25
Description:
"""
import numpy as np
import networkx as nx
import scipy.sparse as sp
import torch
import scipy.io as sio
import random
import dgl
def sparse_to_tuple(sparse_mx, insert_batch=False):
"""
Convert sparse matrix to tuple representation
insert_batch:决定是否插入一个批次的维度
"""
def to_tuple(mx): # 将单个系数矩阵转换为元组表示
if not sp.isspmatrix_coo(mx):
mx = mx.tocoo() # 转为coo格式
# 例如稀疏矩阵data = [0,0,1][2,0,0],[0,3,0]
# coords:稀疏矩阵中非零元素的坐标
# values:对应坐标位置的值
# shape:稀疏矩阵的形状
if insert_batch: # if you want to insert a batch dimension
coords = np.vstack((np.zeros(mx.row.shape[0]), mx.row, mx.col)).transpose()
values = mx.data
shape = (1,) + mx.shape
else:
coords = np.vstack((mx.row, mx.col)).transpose()
values = mx.data
shape = mx.shape
return coords, values, shape
if isinstance(sparse_mx, list): # 如果是存储稀疏矩阵的列表
for i in range(len(sparse_mx)):
sparse_mx[i] = to_tuple(sparse_mx[i])
else:
sparse_mx = to_tuple(sparse_mx)
return sparse_mx # 可以获取.data,.row,.col,.shape
def preprocess_features(features):
"""
Row-normalize feature matrix and convert
归一化特征矩阵
"""
rowsum = np.array(features.sum(1)) # 计算矩阵每一行的和,形成一个列向量
r_inv = np.power(rowsum, -1).flatten() # rowsum取倒数,展平为一维数组
r_inv[np.isinf(r_inv)] = 0. # 无穷大值置为0
r_mat_inv = sp.diags(r_inv) # 创建一个对角阵
features = r_mat_inv.dot(features) # 使用对角阵乘以原矩阵,归一化
return features.todense(), sparse_to_tuple(features)
def normalize_adj(adj):
"""
Symmetrically normalize adjacency matrix.
归一化邻接矩阵
"""
adj = sp.coo_matrix(adj)
rowsum = np.array(adj.sum(1))
d_inv_sqrt = np.power(rowsum, -0.5).flatten()
d_inv_sqrt[np.isinf(d_inv_sqrt)] = 0.
d_mat_inv_sqrt = sp.diags(d_inv_sqrt)
return adj.dot(d_mat_inv_sqrt).transpose().dot(d_mat_inv_sqrt).tocoo()
# 最终实现对称归一化 A= D^-1/2 A D^-1/2
def dense_to_one_hot(labels_dense, num_classes):
"""
Convert class labels from scalars to one-hot vectors
将类别标签,从标量形式转换为独热编码形式
"""
num_labels = labels_dense.shape[0] # 标签数组长度
index_offset = np.arange(num_labels) * num_classes # 计算索引偏移量
labels_one_hot = np.zeros(num_labels, num_classes) # 创建全零矩阵
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1 # 填充独热编码矩阵
return labels_one_hot
def load_mat(dataset, train_rate=0.3, val_rate=0.1):
"""
Load .mat dataset
"""
data = sio.loadmat("../dataset/{}.mat".format(dataset))
label = data['Label'] if ('Label' in data) else data['gnd']
attr = data['Attributes'] if ('Attributes' in data) else data['X']
network = data['Network'] if ('Network' in data) else data['A']
#
adj = sp.csr_matrix(network)
feat = sp.lil_matrix(attr)
labels = np.squeeze(np.array(data['Class'], dtype=np.int64) - 1)
num_classes = np.max(labels) +1
labels = dense_to_one_hot(labels, num_classes) # 返回的lable为独热编码形式
ano_labels = np.squeeze(np.array(label))
if 'str_anomaly_label' in data:
str_ano_labels = np.squeeze(np.array(data['str_anomaly_label']))
attr_ano_labels = np.squeeze(np.array(data['attr_anomaly_label']))
else:
str_ano_labels = None
attr_ano_labels = None
num_node = adj.shape[0]
num_train = int(num_node * train_rate)
num_val = int(num_node * val_rate)
all_idx = list(range(num_node))
random.shuffle(all_idx)
idx_train = all_idx[:num_train]
idx_val = all_idx[num_train:num_train+num_val]
idx_test = all_idx[num_train+num_val:] #
return adj, feat, labels, idx_train, idx_val, idx_test, ano_labels, str_ano_labels, attr_ano_labels
def adj_to_dgl_graph(adj):
"""
Convert adj to dgl format.
"""
nx_graph = nx.from_scipy_sparse_matrix(adj)
dgl_graph = dgl.DGLGraph(nx_graph)
return dgl_graph
def generate_rwr_subgraph(dgl_graph, subgraph_size):
"""
Generate subgraph with RWR algorithm(重启随机游走)
subgraph_size:子图大小
"""
all_idx = list(range(dgl_graph.number_of_nodes())) #获取节点索引列表
reduced_size = subgraph_size - 1
# 生成随机游走路径
traces = dgl.contrib.sampling.random_walk_with_restart(dgl_graph, all_idx, restart_prob=1, max_nodes_per_seed=subgraph_size*3)
subv = []
for i, trace in enumerate(traces): # 遍历每个游走路径
# 将节点的邻居节点存入子图节点集合当中
subv.append(torch.unique(torch.cat(trace), sorted=False).tolist())
retry_time = 0
while len(subv[i]) < reduced_size:# 如果节点数量不满足大小,重新RWR
# 将每条路径的
cur_trace = dgl.contrib.sampling.random_walk_with_restart(dgl_graph, [i], restart_prob=0.9, max_nodes_per_seed=subgraph_size*5)
subv[i] = torch.unique(torch.cat(cur_trace[0]), sorted=False).tolist()
retry_time += 1
if (len(subv[i]) <= 2) and (retry_time > 10):
subv[i] = (subv[i] * reduced_size)
subv[i] = subv[i][:reduced_size]
subv[i].append(i) # 确保每个子图都包含起始节点
return subv # 返回每个子图的节点索引列表
main.py
"""
FileName:
Author:
Version:
Date: 2024/6/1121:30
Description:
"""
import numpy as np
import scipy.sparse as sp
import torch
import torch.nn as nn
import random
import os
import dgl
import argparse
from tqdm import tqdm
from sklearn.metrics import roc_auc_score
from utils import *
from model import *
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # 允许重复加载同样的库
# Set argument
parser = argparse.ArgumentParser(description='CoLA: Self-Supervised Contrastive Learning for Anomaly Detection')
parser.add_argument('--dataset', type=str, default='cora')
parser.add_argument('--lr', type=float)
parser.add_argument('--weight_decay', type=float, default=0.0)
parser.add_argument('--seed', type=int, default=1)
parser.add_argument('--embedding_dim', type=int, default=64) #
parser.add_argument('--num_epoch', type=int)
parser.add_argument('--drop_prob', type=int, default=0.0) #
parser.add_argument('--batch_size', type=int, default=300)
parser.add_argument('--subgraph_size', type=int, default=4)
parser.add_argument('--readout', type=str, default='avg') #
parser.add_argument('--auc_test_rounds', type=int, default=256) #
parser.add_argument('--negsamp_ratio', type=int, default=1) #
args = parser.parse_args()
# 针对不同数据集设置学习率
if args.lr is None:
if args.dataset in ['cora', 'citeseer', 'pubmed', 'Flickr']:
args.lr = 1e-3 # 0.001
elif args.dataset == 'ACM':
args.lr = 5e-4
elif args.dataset == 'BlogCatalog':
args.lr = 3e-3
# 设置num_epoch
if args.num_epoch is None:
if args.dataset in ['cora', 'citeseer', 'pubmed']:
args.num_epoch = 100
elif args.dataset in ['BlogCatalog', 'Flickr', 'ACM']:
args.num_epoch = 400
batch_size = args.batch_size
subgraph_size = args.subgraph_size
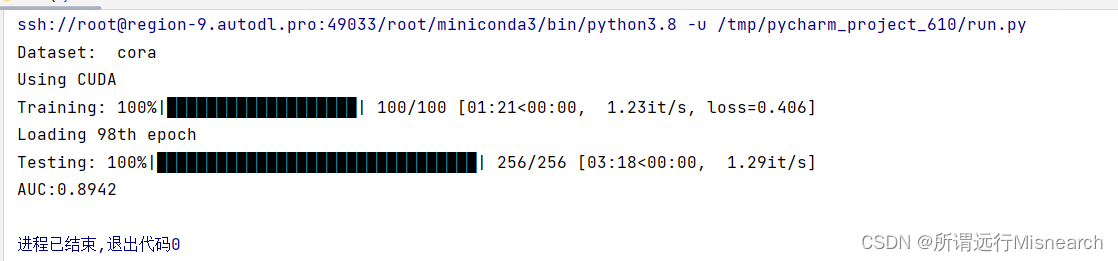
print("Dataset: ", args.dataset)
# Set random seed 设置随机数,使得随机可重复
dgl.random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
random.seed(args.seed)
os.environ['PYTHONHSAHSEED'] = str(args.seed)
os.environ['OMP_NUM_THREADS'] = '1' # 避免多线程并行导致的非确定性行为
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False # 禁用基准模式
# Load and preprocess data
adj, features, labels, idx_train, idx_val, idx_test, ano_label, str_ano_label, attr_ano_label = load_mat(args.dataset)
features, _ = preprocess_features(features) # 归一化
dgl_graph = adj_to_dgl_graph(adj)
nb_nodes = features.shape[0] # 节点数量
ft_size = features.shape[1] # 特征维度
nb_classes = labels.shape[1] # 类别数量
adj = normalize_adj(adj)
adj = (adj + sp.eye(adj.shape[0])).todense() #
# 变换为tensor
features = torch.FloatTensor(features[np.newaxis])
adj = torch.FloatTensor(adj[np.newaxis])
labels = torch.FloatTensor(labels[np.newaxis])
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
# Initialize model and optimiser
model = Model(ft_size, args.embedding_dim, 'prelu', args.negsamp_ratio, args.readout)
optimiser = torch.optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
if torch.cuda.is_available():
print('Using CUDA')
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
if torch.cuda.is_available():
# 二元交叉熵损失函数
b_xent = nn.BCEWithLogitsLoss(reduction='none', pos_weight=torch.tensor([args.negsamp_ratio]).cuda())
else:
b_xent = nn.BCEWithLogitsLoss(reduction='none', pos_weight=torch.tensor([args.negsamp_ratio]))
xent = nn.CrossEntropyLoss()
cnt_wait = 0
best = 1e9
best_t = 0
batch_num = nb_nodes // batch_size + 1
added_adj_zero_row = torch.zeros((nb_nodes, 1, subgraph_size))
added_adj_zero_col = torch.zeros((nb_nodes, subgraph_size + 1, 1))
added_adj_zero_col[:,-1,:] = 1.
added_feat_zero_row = torch.zeros((nb_nodes, 1, ft_size))
if torch.cuda.is_available():
added_adj_zero_row = added_adj_zero_row.cuda()
added_adj_zero_col = added_adj_zero_col.cuda()
added_feat_zero_row = added_feat_zero_row.cuda()
# Train model
with tqdm(total=args.num_epoch) as pbar:
pbar.set_description('Training')
for epoch in range(args.num_epoch):
loss_full_batch = torch.zeros(nb_nodes, 1)
if torch.cuda.is_available():
loss_full_batch = loss_full_batch.cuda()
model.train()
all_idx = list(range(nb_nodes))
random.shuffle(all_idx)
total_loss = 0
# 产生随机采样的子图节点集合
subgraphs = generate_rwr_subgraph(dgl_graph, subgraph_size)
for batch_idx in range(batch_num):
optimiser.zero_grad()
is_final_batch = (batch_idx == (batch_num - 1))
if not is_final_batch:
idx = all_idx[batch_idx * batch_size:(batch_idx+1)*batch_size]
else:
idx = all_idx[batch_idx*batch_size:]
# 当前批次节点大小
cur_batch_size = len(idx)
lbl = torch.unsqueeze(
torch.cat((torch.ones(cur_batch_size), torch.zeros(cur_batch_size * args.negsamp_ratio))), 1)
ba = []
bf = []
added_adj_zero_row = torch.zeros((cur_batch_size, 1, subgraph_size))
added_adj_zero_col = torch.zeros((cur_batch_size, subgraph_size + 1, 1))
added_adj_zero_col[:, -1, :] = 1.
added_feat_zero_row = torch.zeros((cur_batch_size, 1, ft_size))
if torch.cuda.is_available():
lbl = lbl.cuda()
added_adj_zero_row = added_adj_zero_row.cuda()
added_adj_zero_col = added_adj_zero_col.cuda()
added_feat_zero_row = added_feat_zero_row.cuda()
for i in idx:
cur_adj = adj[:, subgraphs[i], :][:, :, subgraphs[i]]
cur_feat = features[:, subgraphs[i], :]
ba.append(cur_adj)
bf.append(cur_feat)
ba = torch.cat(ba)
ba = torch.cat((ba, added_adj_zero_row), dim=1)
ba = torch.cat((ba, added_adj_zero_col), dim=2)
bf = torch.cat(bf)
bf = torch.cat((bf[:, :-1, :], added_feat_zero_row, bf[:, -1:, :]), dim=1)
logits = model(bf, ba)
loss_all = b_xent(logits, lbl)
loss = torch.mean(loss_all)
loss.backward()
optimiser.step()
loss = loss.detach().cpu().numpy()
loss_full_batch[idx] = loss_all[: cur_batch_size].detach()
if not is_final_batch:
total_loss += loss
mean_loss = (total_loss * batch_size + loss * cur_batch_size) / nb_nodes
if mean_loss < best:
best = mean_loss
best_t = epoch
cnt_wait = 0
torch.save(model.state_dict(), 'best_model.pkl')
else:
cnt_wait += 1
pbar.set_postfix(loss=mean_loss)
pbar.update(1)
# Test model
print('Loading {}th epoch'.format(best_t))
model.load_state_dict(torch.load('best_model.pkl'))
multi_round_ano_score = np.zeros((args.auc_test_rounds, nb_nodes))
multi_round_ano_score_p = np.zeros((args.auc_test_rounds, nb_nodes))
multi_round_ano_score_n = np.zeros((args.auc_test_rounds, nb_nodes))
with tqdm(total=args.auc_test_rounds) as pbar_test:
pbar_test.set_description('Testing')
for round in range(args.auc_test_rounds):
all_idx = list(range(nb_nodes))
random.shuffle(all_idx)
subgraphs = generate_rwr_subgraph(dgl_graph, subgraph_size)
for batch_idx in range(batch_num):
optimiser.zero_grad()
is_final_batch = (batch_idx == (batch_num - 1))
if not is_final_batch:
idx = all_idx[batch_idx * batch_size: (batch_idx + 1) * batch_size]
else:
idx = all_idx[batch_idx * batch_size:]
cur_batch_size = len(idx)
ba = []
bf = []
added_adj_zero_row = torch.zeros((cur_batch_size, 1, subgraph_size))
added_adj_zero_col = torch.zeros((cur_batch_size, subgraph_size + 1, 1))
added_adj_zero_col[:, -1, :] = 1.
added_feat_zero_row = torch.zeros((cur_batch_size, 1, ft_size))
if torch.cuda.is_available():
lbl = lbl.cuda()
added_adj_zero_row = added_adj_zero_row.cuda()
added_adj_zero_col = added_adj_zero_col.cuda()
added_feat_zero_row = added_feat_zero_row.cuda()
for i in idx:
cur_adj = adj[:, subgraphs[i], :][:, :, subgraphs[i]]
cur_feat = features[:, subgraphs[i], :]
ba.append(cur_adj)
bf.append(cur_feat)
ba = torch.cat(ba)
ba = torch.cat((ba, added_adj_zero_row), dim=1)
ba = torch.cat((ba, added_adj_zero_col), dim=2)
bf = torch.cat(bf)
bf = torch.cat((bf[:, :-1, :], added_feat_zero_row, bf[:, -1:, :]), dim=1)
with torch.no_grad():
logits = torch.squeeze(model(bf, ba))
logits = torch.sigmoid(logits)
ano_score = - (logits[:cur_batch_size] - logits[cur_batch_size:]).cpu().numpy()
# ano_score_p = - logits[:cur_batch_size].cpu().numpy()
# ano_score_n = logits[cur_batch_size:].cpu().numpy()
multi_round_ano_score[round, idx] = ano_score
# multi_round_ano_score_p[round, idx] = ano_score_p
# multi_round_ano_score_n[round, idx] = ano_score_n
pbar_test.update(1)
ano_score_final = np.mean(multi_round_ano_score, axis=0)
# ano_score_final_p = np.mean(multi_round_ano_score_p, axis=0)
# ano_score_final_n = np.mean(multi_round_ano_score_n, axis=0)
auc = roc_auc_score(ano_label, ano_score_final)
print('AUC:{:.4f}'.format(auc))
结果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









