










1.工具准备
开发环境:Eclipse+Httpclient+Jsoup
jar包:
httpclient下的所有jar包(我不清楚哪些jar包是不需要的,以防万一,把所有jar包加上)
jsoup-1.10.3.jar
2.了解并阅读相关文档
HttpClient 是Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
这里不过多介绍,想要了解的可以自己去官网翻看,我们用httpclient模拟浏览器请求,用jsoup解析httpclient返回的实体的文档对象。
3.开始编写代码
package com.ff.jsoup;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.HashMap;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupHelloWorld {
public Elements getRequestMethod(String url) throws Exception {
CloseableHttpClient client = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
//setConnectTimeout(10000)连接超时时间(单位豪秒)
//setSocketTimeout(10000)读取超时时间(单位豪秒)
RequestConfig config=RequestConfig.custom().setConnectTimeout(10000).setSocketTimeout(10000).build();
httpGet.setConfig(config);
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64)"
+ " AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36");
CloseableHttpResponse response = client.execute(httpGet);
HttpEntity entity = response.getEntity(); //获取返回实体
String html = "";
if(entity!=null) {
html = EntityUtils.toString(entity);
}
response.close(); //关闭流和和释放资源
Document doc = Jsoup.parse(html); //解析网页得到文档对象
/**
* getElementById(String id) 根据id来查询DOM
* getElementsByTag(String tagName) 根据tag名称来查询DOM
* getElementsByClass(String className) 根据样式名称来查询DOM
* getElementsByAttribute(String key) 根据属性名来查询DOM
* getElementsByAttributeValue(String key,String value) 根据属性名和属性值来查询DOM
*/
Elements tags = doc.select("#ip_list > tbody > tr");
// Element element = tags.get(0);
// System.out.println(element.text());
// System.out.println(tags);
return tags;
}
public Map<Integer,String> getElementsByTags(Elements tags) {
Map<Integer,String> ipAddress = new HashMap<Integer,String>();
int count = 0;
//遍历tbody子节点
for (Element element : tags) {
//取得ip地址节点
Elements tdChilds = element.select("tr > td:nth-child(2)");
//取得端口号节点
Elements tcpd = element.select("tr > td:nth-child(3)");
ipAddress.put(++count, tdChilds.text()+"."+tcpd.text());
}
System.out.println(ipAddress);
return ipAddress;
}
public void saveToText(Map<Integer,String> map) {
try {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File("D:\\cc\\IpAddress.txt")),
"UTF-8"));
for (int i = 2; i < map.size(); i++) {
String ipAddess = map.get(i);
// FileUtils.writeStringToFile(new File("D:\\cc\\IpAddress.txt"), ipAddess, "utf-8");
bw.write(ipAddess);
bw.newLine();
}
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("ip地址爬取保存完毕");
}
public static void main(String[] args) {
JsoupHelloWorld ht = new JsoupHelloWorld();
String url = "http://www.xicidaili.com/nn/";
try {
Elements elements = ht.getRequestMethod(url);
Map<Integer, String> elementsByTags = ht.getElementsByTags(elements);
ht.saveToText(elementsByTags);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.流程分析
1.首先通过httpclient请求页面返回实体
2.然后通过jsoup解析得到Document对象
3.分析西刺网站的ip地址和端口号所在位置
4.用select选择器提取要爬取的ip地址和端口号
5.将ip地址和端口号拼接成一个完整的地址,再用Map集合封装地址
6.遍历Map,通过IO流的输出流将Map封装的地址输出到本地文件,每写入一行换行
7.关闭流,控制台输出结束语
5.样图
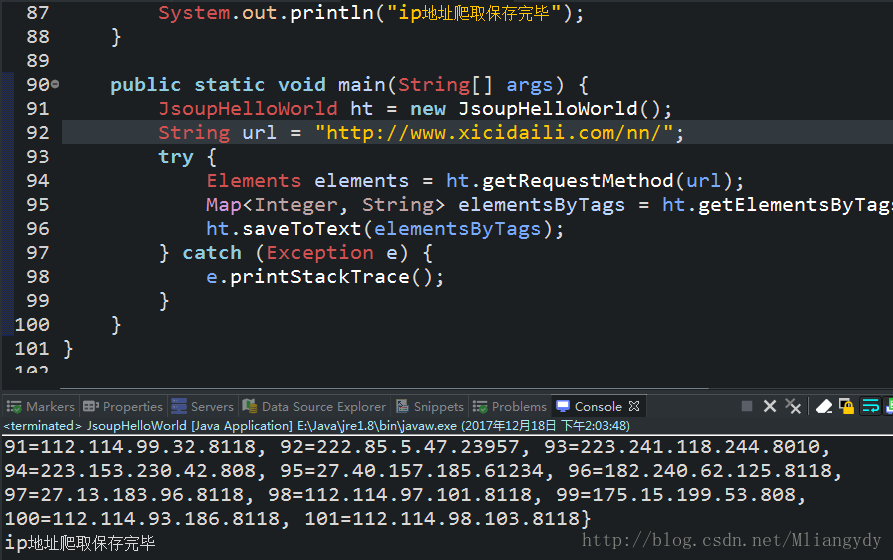

6.总结
昨天才开始学的Java爬虫,并不难,很容易上手,除了httpclient和jsoup架包的操作剩下的就是html、css分析及IO流的操作了。并且tdChilds.text()和tdChilds.toString()区别还是要说一下:前者提取标签内容,后者提取整个标签。初次用Java写出了一个爬虫,也是很有成就感的,哈哈哈
。















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









