







写在前面:
简单了解下就行,目前公司用的还是2.x版本。
进入主题:
1.Erasure Encoding
- 简介
- HDFS默认情况下,Block的备份系数是3,一个原始数据块和其他2个副本。
- 其中2个副本所需要的存储开销各站100%,这样使得200%的存储开销
- 正常操作中很少访问具有低IO活动的冷数据集的副本,但是仍然消耗与原始数据集相同的资源量。
- EC技术
- EC(擦除编码)和HDFS的整合可以保持与提供存储效率相同的容错。
- HDFS:一个副本系数为3,要复制文件的6个块,需要消耗6*3=18个块的磁盘空间
- EC:6个数据块,3个奇偶校验块
- 擦除编码需要在执行远程读取时,对数据重建带来额外的开销,因此他通常用于存储不太频繁访问的数据
- EC(擦除编码)和HDFS的整合可以保持与提供存储效率相同的容错。
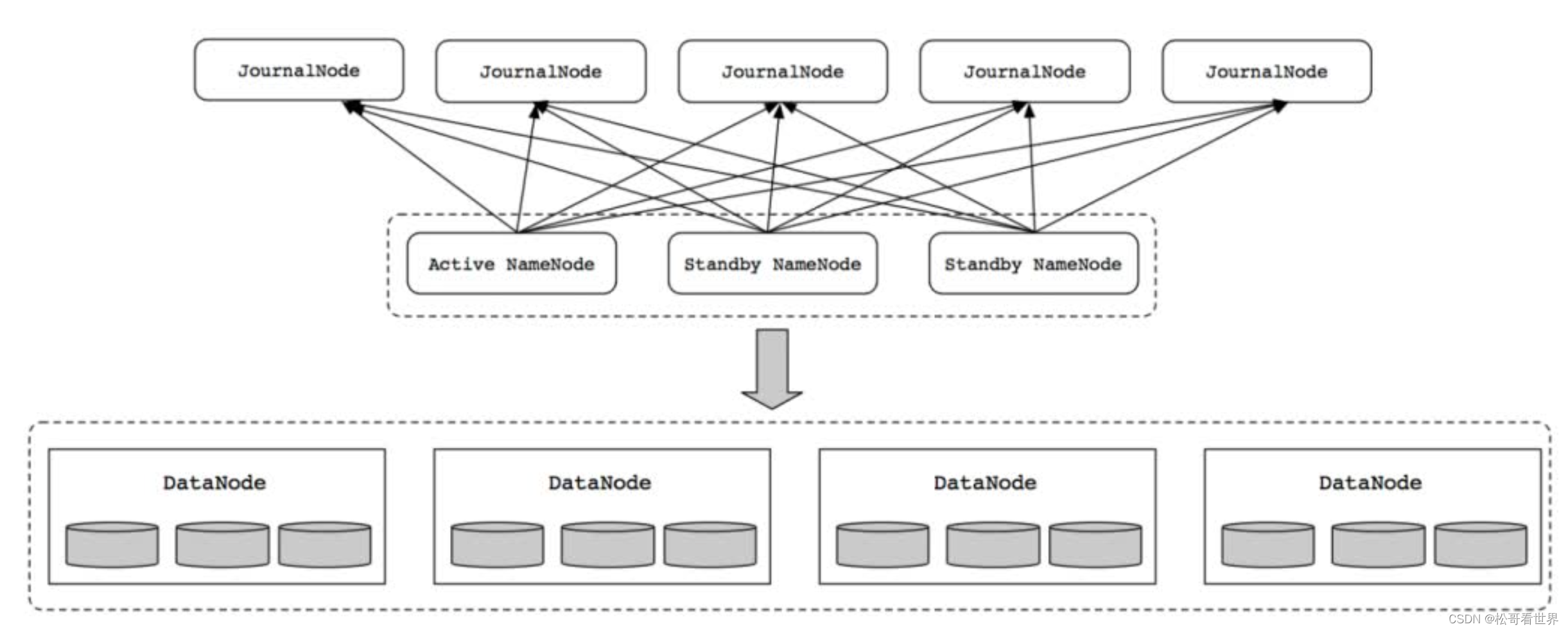
2.NameNode
- 在Hadoop3中允许用户运行多个备用的NameNode。
- 例如,通过配置三个NameNode(1个Active NameNode和2个Standby NameNode)和5个JournalNodes节点
- 集群可以容忍2个NameNode节点故障。
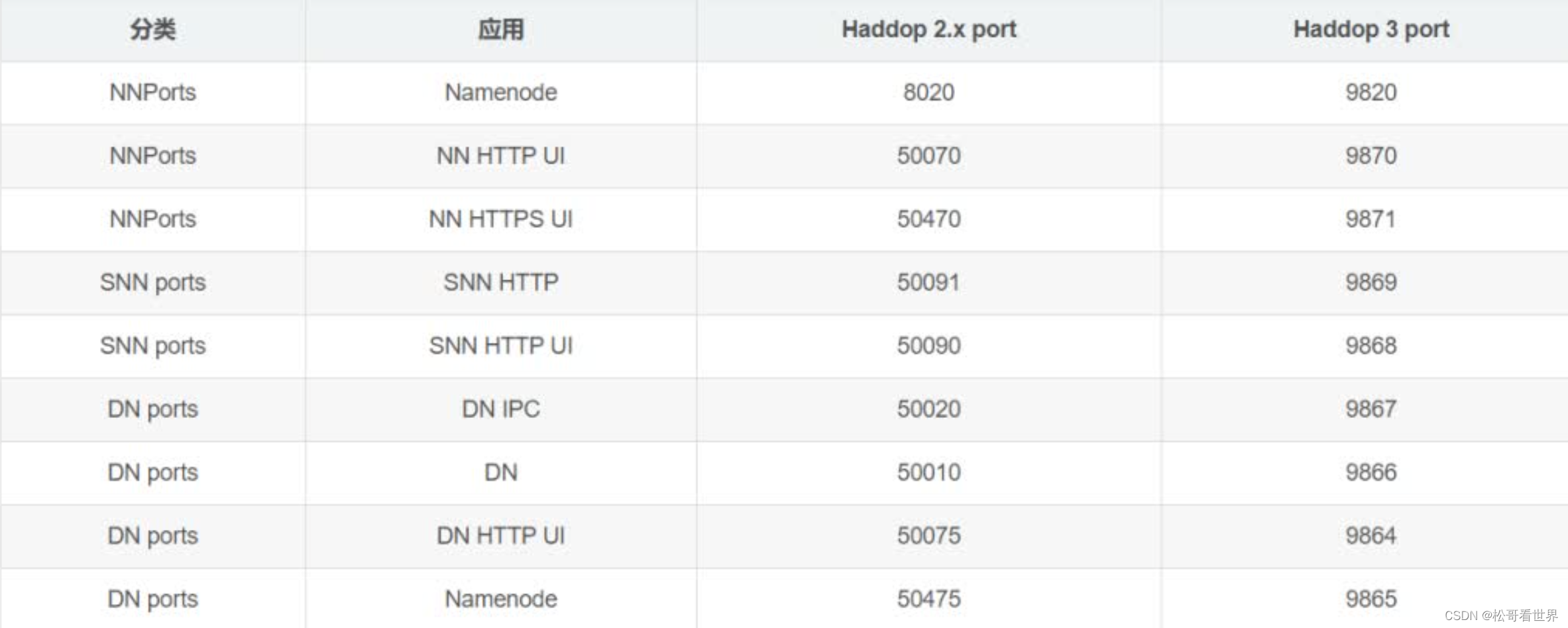
3.服务器端口
- 早些时候,多个Hadoop服务的默认端口位于Linux端口范围以内。
- 因此,具有临时范围冲突端口已经被移除该范围
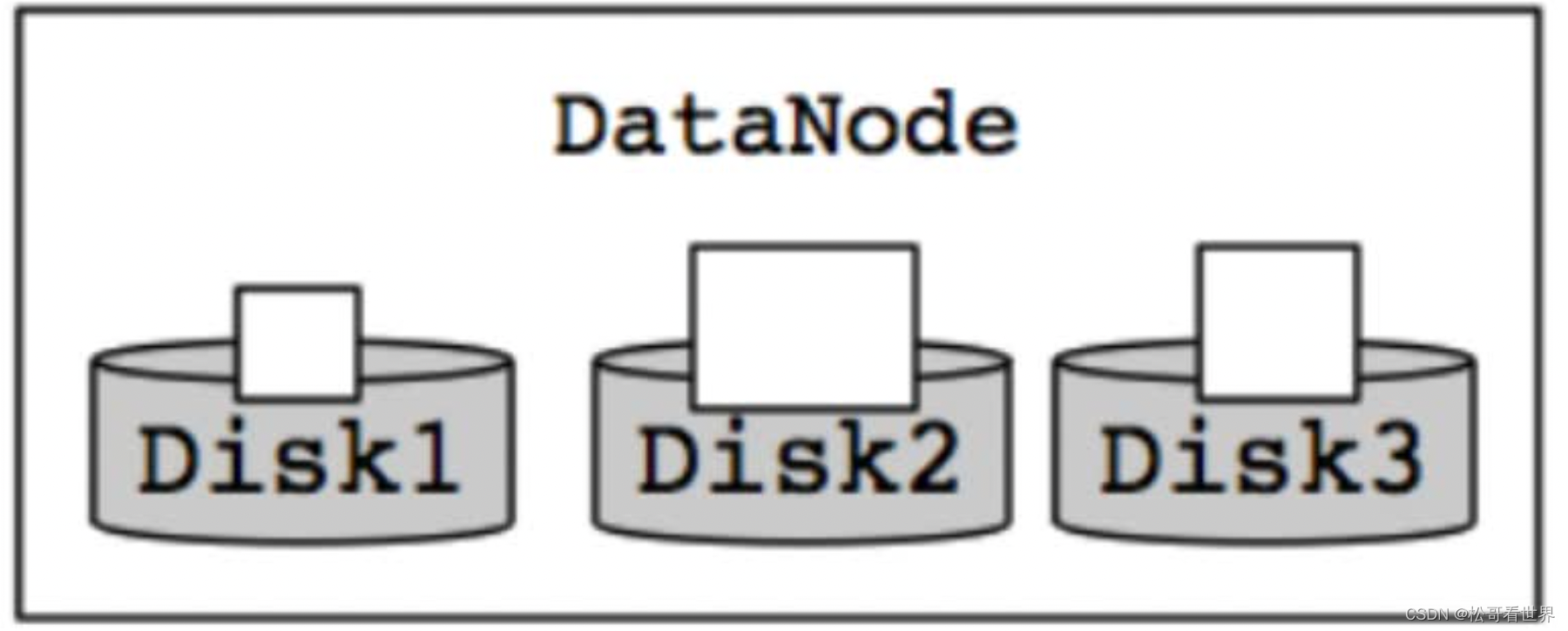
4. DataNode
- 单个数据节点配置多个数据磁盘,在正常写入操作期间,数据被均匀的划分,因此,磁盘被均匀填充。
- 在维护磁盘时,添加或者替换磁盘会导致DataNode节点存储出现偏移
- 这种情况在早期的HDFS文件系统中,是没有被处理的。
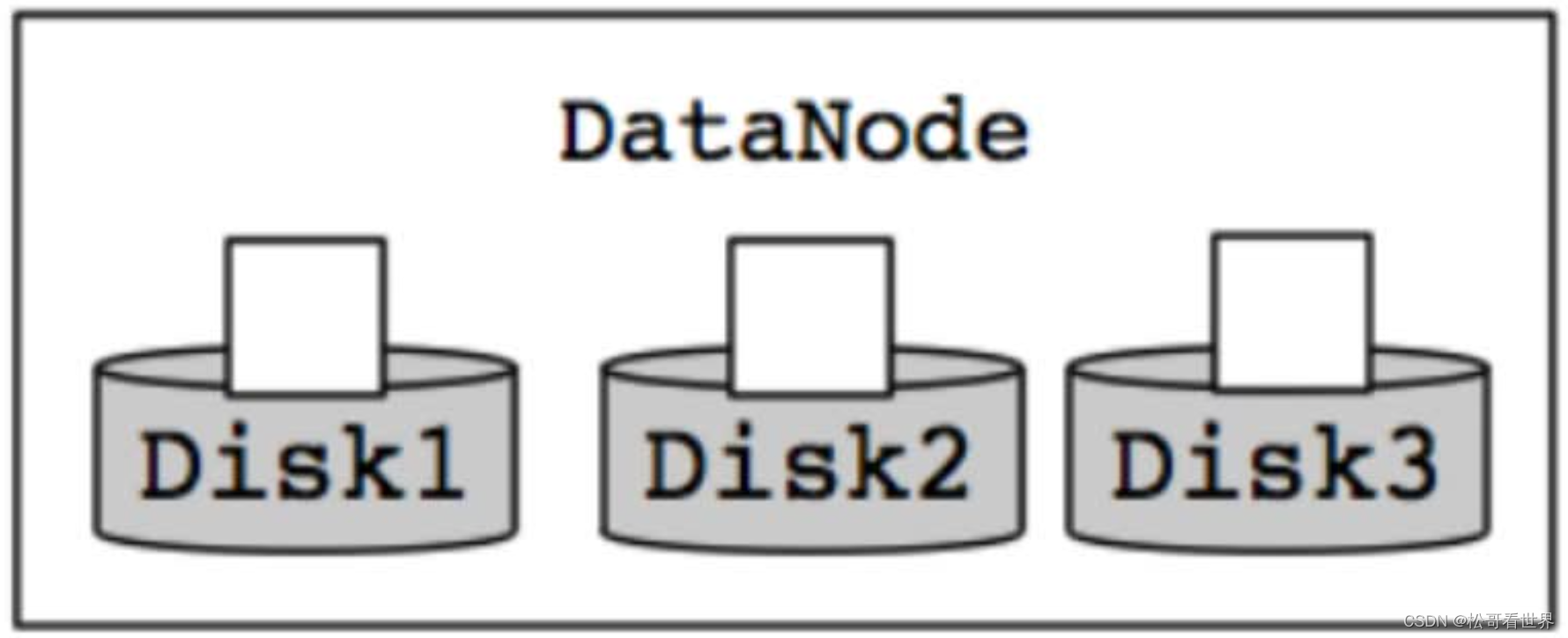
- Hadoop3通过新的内部DataNode平衡功能来处理这种情况,这是通过hdfs diskbalancer CLI来进行调用的。执行之后,DataNode会进行均衡处理
5.蚊子腿
- JDK:
- Hadoop3中,最低版本要求是JDK8,所以低于JDK8的版本需要对JDK进行升级,方可安装使用Hadoop3

- Hadoop3中,最低版本要求是JDK8,所以低于JDK8的版本需要对JDK进行升级,方可安装使用Hadoop3
- Yarn:
- 提供YARN的时间轴服务V.2,以便用户和开发人员可以对其进行测试,并提供反馈意见
- 优化Hadoop Shell脚本
- 重构Hadoop Client Jar包
- 支持随机Container
- MapReduce任务级本地优化
- 支持文件系统连接器
完毕。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









