







绳牵引并联机器人在受限空间中如何躲避动态障碍物,是个有挑战的课题。
来自哈尔滨工业大学(深圳)的熊昊老师团队,开展了一项有趣的研究,论文《Dynamic Obstacle Avoidance for Cable-Driven Parallel Robots With Mobile Bases via Sim-to-Real Reinforcement Learning》发表在SCI&EI收录期刊IEEE Robotics and Automation Letters上。
熊昊老师团队将在2024年ICRA大会上展示相关研究成果。
研究背景
绳牵引并联机器人(Cable-Driven Parallel Robot,CDPR)是一种使用绳索来代替刚性连杆控制末端执行器位姿的新型并联机器人。
这类机器人结构简单、惯性小、运动空间大、且动态性能良好。非常适用于装备制造、医疗康复、航空航天等领域。由于它可以改变几何结构,非常适用于约束环境下的操作任务。

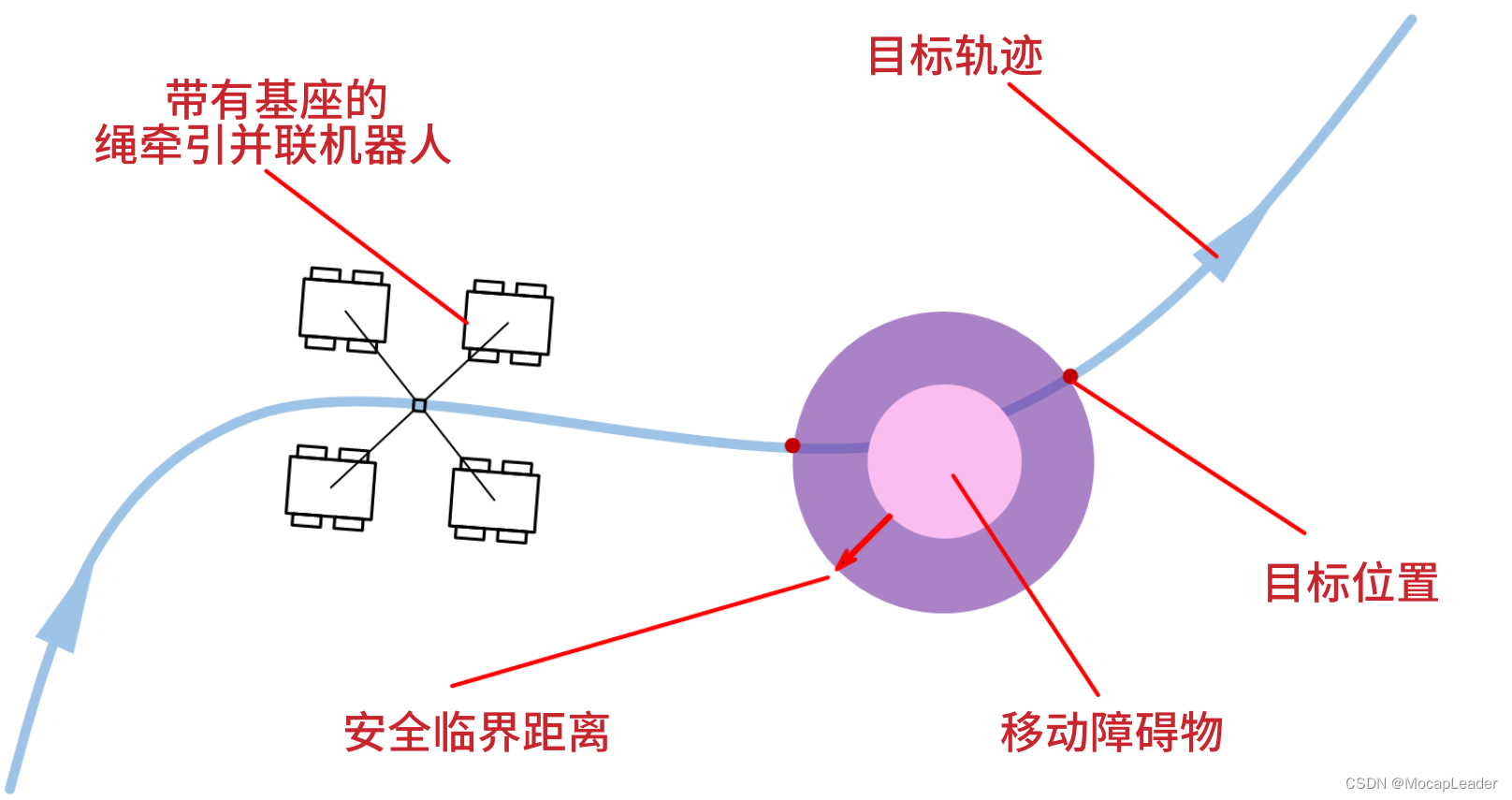
绳牵引并联机器人在受限环境中执行操作任务时,可能会遇到轨迹规划方法未考虑的动态障碍物,需要实时避让动作来绕过或越过障碍物。由于高维状态空间、以及多个绳索和移动基座引起的约束,这是个有挑战的课题。
该项研究解决了这个问题。所提出的算法能够实现绳牵引并联机器人及时躲避,避免与障碍物碰撞,并返回到目标轨迹上。
避障算法
该研究提出了一种基于强化学习(RL)的避障控制器(RL-based OAC),并将其集成到轨迹跟踪控制器(TTC)中,并设计了一种基于Soft Actor Critic(SAC)算法和注意力模块的OAC,用于处理具有固定长度绳索连接到移动基座的绳牵引并联机器人的动态障碍物实时避让问题。
该方法可以处理CDPR的多个约束和高维状态空间,实现了CDPR在实时动态障碍物环境下的动态避障。
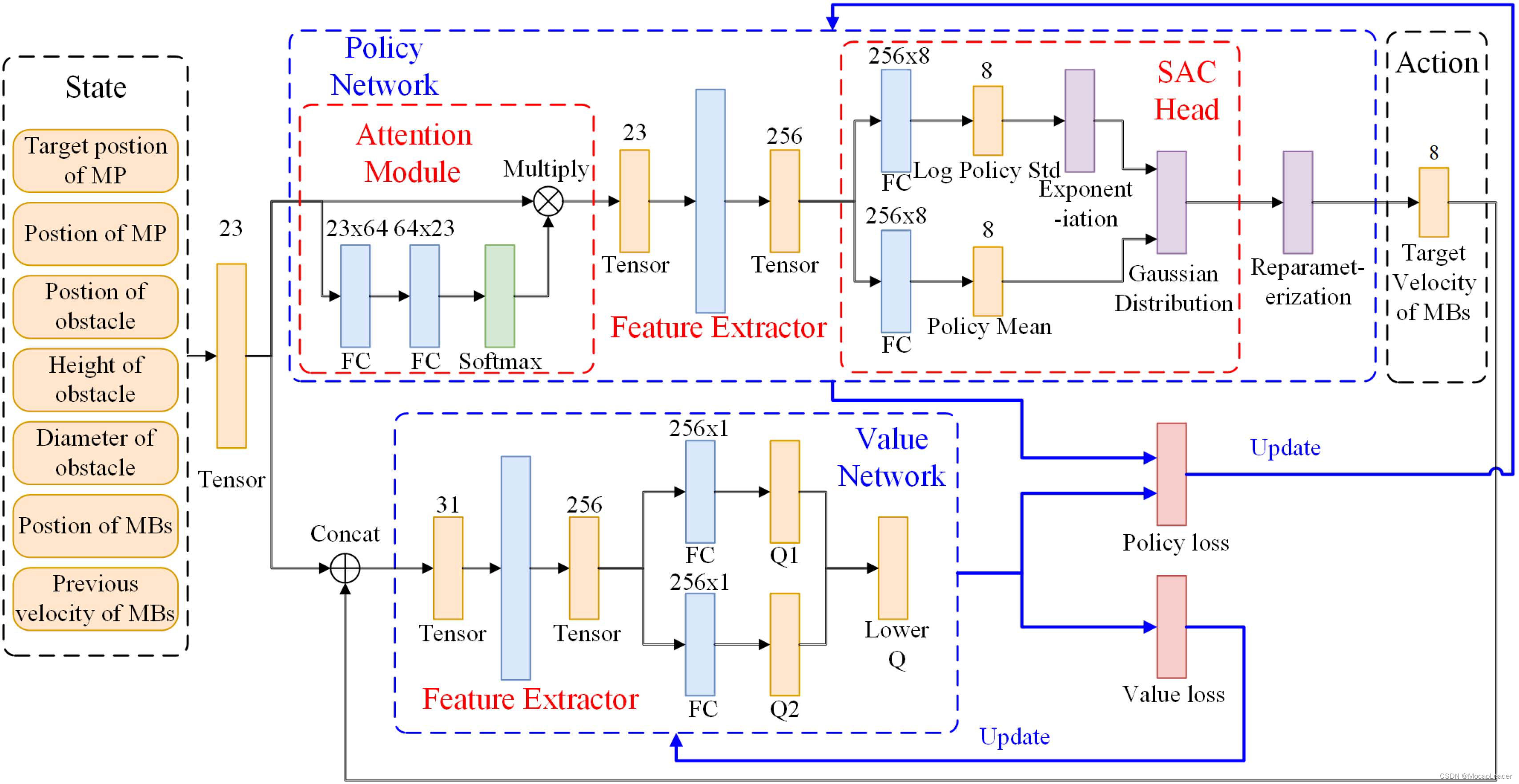
在Mujoco模拟器中对RL-based OAC进行训练。分别基于两阶段训练策略和一阶段训练策略进行训练。
基于两阶段训练策略训练的OAC集中在5万集以内,OAC的训练时间约为35分钟。基于单阶段训练策略训练的OAC收敛在50万集以内,OAC的训练时间约为5.5小时。两个OAC最终获得了几乎相同的累计奖励。研究表明,使用奖励塑造技术的两阶段训练策略可以加速OAC的训练。
真实实验
在真实环境中,利用训练好的RL-based OAC方法进行实验验证。
实验对象为连接有四个固定长度绳索的四个移动基座的绳牵引并联机器人。使用两种规则的障碍物,一种是高度为0.32米的较低的障碍物,一种是高度为0.92米的较高的障碍物。
CDPR的移动平台可以从上方越过低障碍物,但无法从上方越过高障碍物,只能采取绕行的方式避障。
在实验过程中,由NOKOV度量动作捕捉系统实时获取绳索的位置、移动基座的位置,以及动态障碍物的位置和形状信息。

遇到不同高度的障碍物时,RL-based OAC方法驱使CDPR采取不同的避障方式,成功地越过或绕过正在移动的障碍物。
参考文献:
Y. Liu, Z. Cao, H. Xiong, J. Du, H. Cao and L. Zhang, “Dynamic Obstacle Avoidance for Cable-Driven Parallel Robots With Mobile Bases via Sim-to-Real Reinforcement Learning,” in IEEE Robotics and Automation Letters, vol. 8, no. 3, pp. 1683-1690, March 2023, doi: 10.1109/LRA.2023.3241801.
原文链接:
https://ieeexplore.ieee.org/document/10035491
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









