







场景:通过prometheus去拉取通过actuator组件暴露的端点中的JVM相关指标。通过告警规则,检测线上服务出现频繁full gc。
((jvm_gc_pause_seconds_count{action="end of major GC",cause!="Heap Dump Initiated GC"}- jvm_gc_pause_seconds_count{action="end of major GC",cause!="Heap Dump Initiated GC"} offset 1d) >2)
or
((jvm_gc_pause_seconds_count{action="end of major GC",cause!="Heap Dump Initiated GC"}-min_over_time(jvm_gc_pause_seconds_count{action="end of major GC",cause!="Heap Dump Initiated GC"}[1d])>2) and (jvm_gc_pause_seconds_count{action="end of major GC",cause!="Heap Dump Initiated GC"}- jvm_gc_pause_seconds_count{action="end of major GC",cause!="Heap Dump Initiated GC"} offset 1d <=0))
告警通知:JVMFullGcCountTooMuch
说明:一天内full GC次数>2次
频繁full GC可能存在GC参数配置不当、内存泄露等问题。
获得full GC发生频率以及暂停时间情况
查看GC情况:
jstat -gc [pid]
发生频率:
- 周期性 | 常发 | 偶发
暂停时间:
- 一次full GC处理时间是否过长:一般一次Full GC的耗时应该在几百毫秒,不超过1s。
Full GC的原因
Prometheus监控中获得常见的full GC 原因:
topk(3,sum(increase(jvm_gc_pause_seconds_count{application="应用名称",action="end of major GC"}[1d]))by (cause,application))
- Ergonomics : JVM自动调节Heap导致GC。(可能情况:进行Minor GC时,如果判断老年代最大可用的连续空间不足于存储新生代所有对象总空间,就会触发Full GC)。
- Allocation Failure : 内存分配失败。
- Metadata GC Threshold :元数据占用内存超过了阈值,元空间不足。
- Heap Dump Initiated GC : 进行Dump heap时触发的。(可以忽略)
这里主要涉及的都是堆内存分配问题。
JVM 内存占用情况
需要查看的内容:
- Full GC后内存是否有释放。
- GC内存配置情况。
- 内存占用最大值和最小值、老生代的占用情况等。
# PromQL查询监控中full 内存占用曲线
jvm_memory_used_bytes{area="heap",id="PS Old Gen"}
# 查看JVM配置
jcmd <pid> VM.flags
通过图表GC内存占用、堆内存占用率分析堆内存使用是否过高。
Full GC的出现与Metadata GC Threshold有关,可查看Metaspace内存占用情况,如果Metaspace区域的内存稳定上升、波动范围合理、不频繁触发Full GC则不用特殊处理。如果由于系统一次性加载过多数据进内存,可能会导致频繁有大对象进入老年代,从而触发Full GC。则需要调大Survivor区,可以考虑增加JVM启动参数中的MetaspaceSize值。
一般的应用,XMX可以设置为物理内存的1/2~2/3。需要较多地使用Heap外内存应用,物理内存不要超过1/2,例如ES、Kafka等中间件,需要大量读写文件,操作系统需要大量的Page Cache,才能有足够的缓存提高性能,所以JVM Heap不要过大,以预留给非Heap的其他内存。
-XX:MaxMetaspaceSize 参数设置了元空间的最大大小。元空间会根据需要动态扩展,但不会超过这个设置的最大值。当元空间使用量超过这个值时,JVM 将触发 Full GC(也会附带younggc),尝试回收不再需要的类元数据以及相关资源。
如果发现堆内存使用过高或者出现长时间的Full GC,可能需要获取dump文件进一步分析内存泄露可能性。
查看其它监控数据
了解系统是否承载高并发请求或处理数据量过大。如果是这种情况,可以尝试优化系统性能,提高并发处理能力,或者增加服务器数量来分担负载。
# QPS
sum(rate(http_server_requests_seconds_count[1m]))
# CPU
system_cpu_usage
...
获得heap dump文件
文章开头有说使用actuator暴露监控指标,也能通过actuator获得heap dump文件
# 添加heapdump,用于开发heapdump端点
management.endpoints.web.exposure.include=health,prometheus,heapdump
更新完成后通过/actuator/heapdump下载dump文件(文件类型为.hprof)
也可以配置:
可以通过配置JVM启动参数来获得dump文件用于分析问题:
1. Heap Dump
生成堆转储快照:
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=./logs/heapdump.hprof
OOM时会自动Dump堆到指定路径。
2. Thread Dump
生成线程Dump快照:
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=./logs/heapdump.hprof
OOM时会自动Dump线程信息到指定路径。
分析dump文件,看是否有大对象持续创建或频繁加入等情况
推荐使用:Eclipse Memory Analyzer(MAT) 工具进行分析。
(下载地址 https://www.eclipse.org/mat/downloads.php )
将下载的文件dump文件通过mat打开:
选择默认的“Leak Suspects Report”
获得内存泄露分析报告
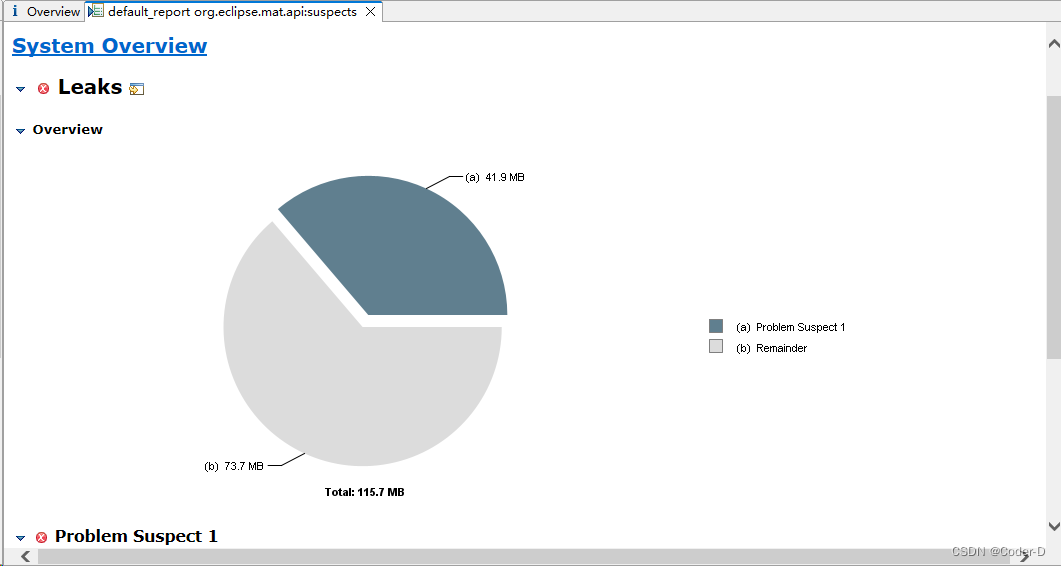
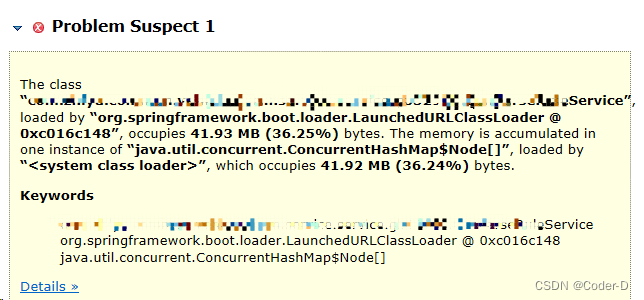
从示例图中可看出,存在一个可疑问题:在“XXXService”中可能存在一个ConcurrentHashMap大对象,占用41.92 MB。
建议优化该Service中的程序。
full GC次数过多的常见原因:
- 堆内存设置过小,容易提前填满
- 临时对象生成速度过快,回收不及时
- 有内存泄漏,堆积非应用对象
- 老年代对象存活周期过长
定位 full GC 问题需要关注:
- GC 时间及停顿时间长度
- 堆内存布局和使用率
- 不同代对象和存活周期情况
可以通过调整堆大小、优化代码、切换 GC 器等手段来减少 full GC 次数。














 7756
7756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









