







Web+Java框架课程设计——网上购物系统
一、需求建模
1. 项目介绍
本项目为网上购物系统,可供商家和顾客使用,提供商品在线分享购买的平台,系统将分为用户和管理员两个角色,其中系统用户部分的主要功能包括登陆注册,商品分类展示、商品详情展示、购物车、下订单、留言板等功能,管理员部分的功能有商品分类管理,商品管理,订单管理、用户管理、留言管理等。
2.主要功能
①网站前台功能
1.首页:提供一个网站首页,可进行网站用户的登录,注册,所有商品的分类,热门商品和最新商品的展示等。
2.用户的注册:针对还未注册的用户完成注册功能的使用,在注册的过程中涉及数据的合法性校验,以及利用 ajax 完成用户名是否已被注册的异步校验。
3.用户的登录:对于已经注册并且激活的用户提供的登录操作。
4.用户的退出:对于已经登录的用户,退出系统。
5.首页商品展示:展示出最新商品和热门商品。
6.分类页面商品展示:根据一级分类和二级分类去展示该分类下的所有商品。
7.商品详情展示:点击某个商品时可以展示该商品的具体详细信息。
8.购物车:用于存放用户的购物内容,用户可根据自己的情况修改自己的购物车。
9.订单:对于已经登录的用户可以对购物车内容进行付款生成订单,可以为自己的订单进行付款或者查看。
10.留言评价分享:网站加入留言板功能,供登录的用户自由发表评价分享心得信息,进行交流互动。
②网站后台功能
1.管理员登录:管理者根据账户和密码进行登录。
2.商品一级、二级分类管理:管理者可以对前台显示的一级、二级分类进行管理,包括添加、删除、修改操作。
3.商品管理:管理者可以对前台显示的商品进行管理包括添加,修改,删除,查询的功能。
4.用户管理:管理者可以查看该网站中已经注册过的所有用户的所有信息。
二、数据库应用需求分析

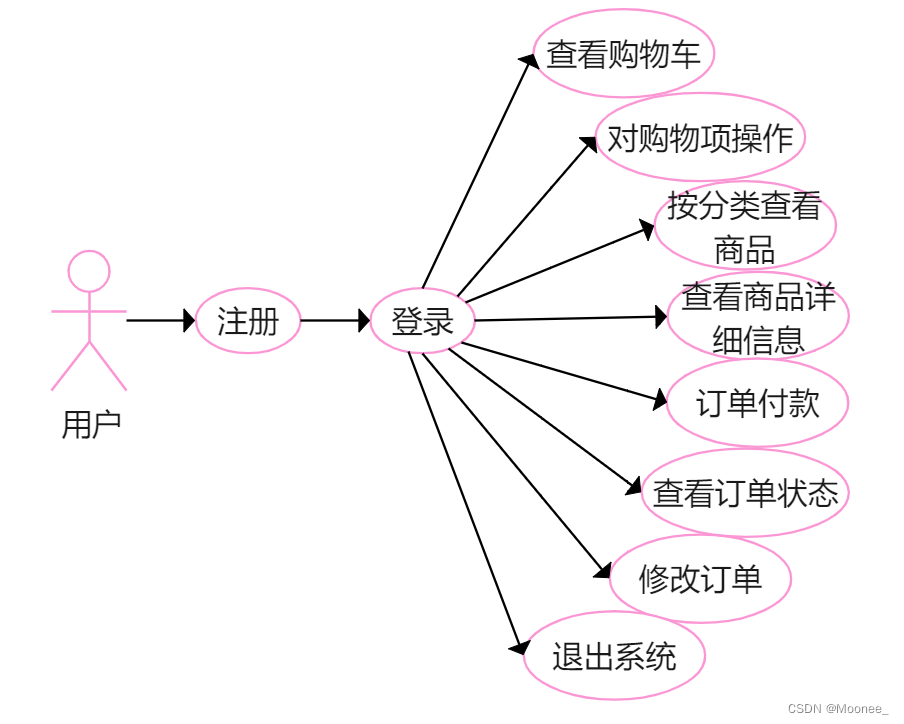
三、设计建模
1.架构设计

业务控制层:控制业务逻辑层 service,担架起了外界与业务层沟通的桥梁,前端在调用相关业务时,都会通过 controller 层,由 controller 层去调用相关的 service 层代码并且把数据返回给前端。
业务逻辑层:如用户的注册、发表留言等功能会在 service 层中进行,业务离不开数据的支持,因此数据访问层 mapper 是必不可少的。
数据访问层:对数据进行持久化操作,将存储在数据库中的数据提交给业务层,同时将业务层处理的数据保存到数据库。
2.数据库概念结构和逻辑结构设计
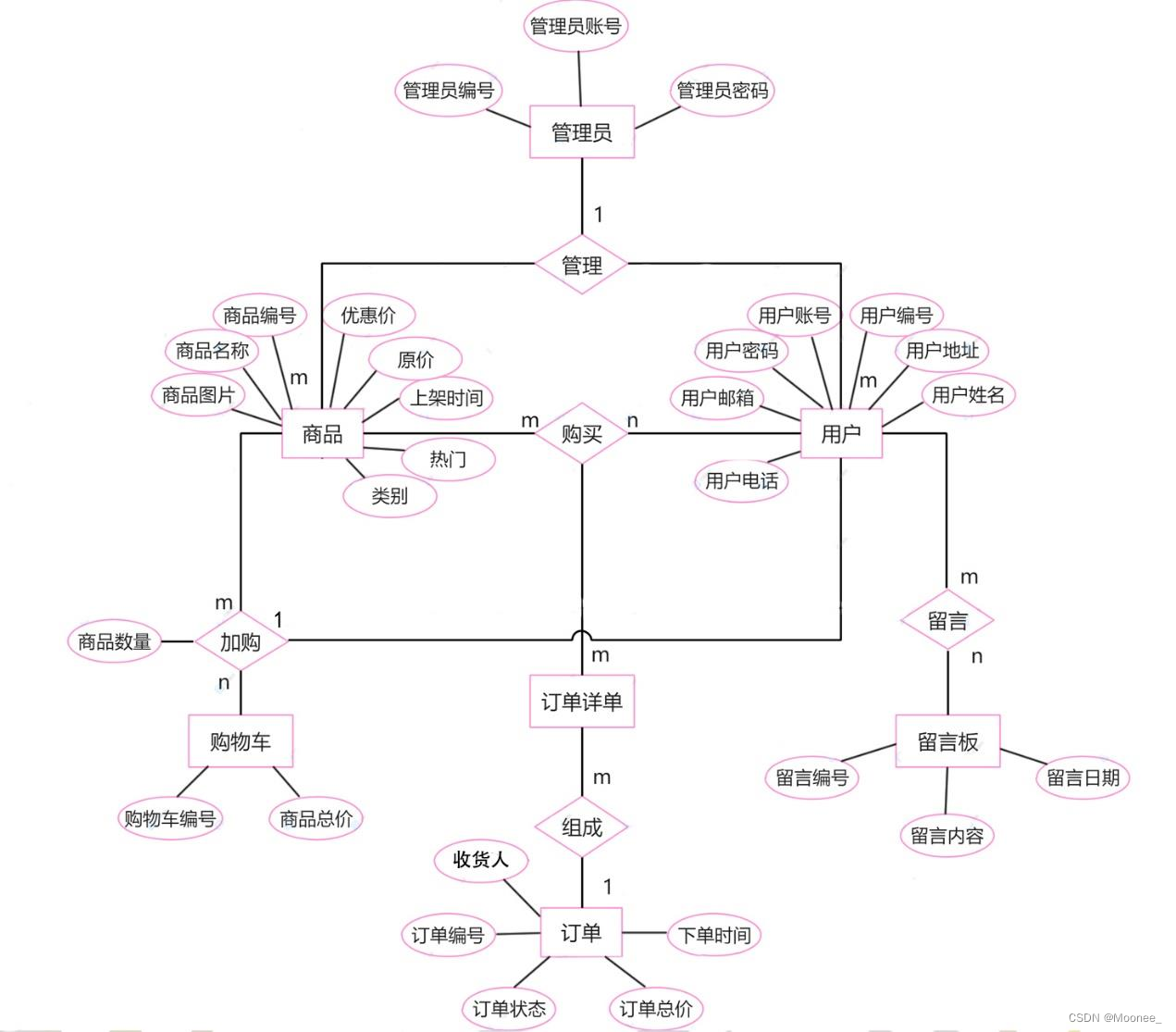
3.模块设计
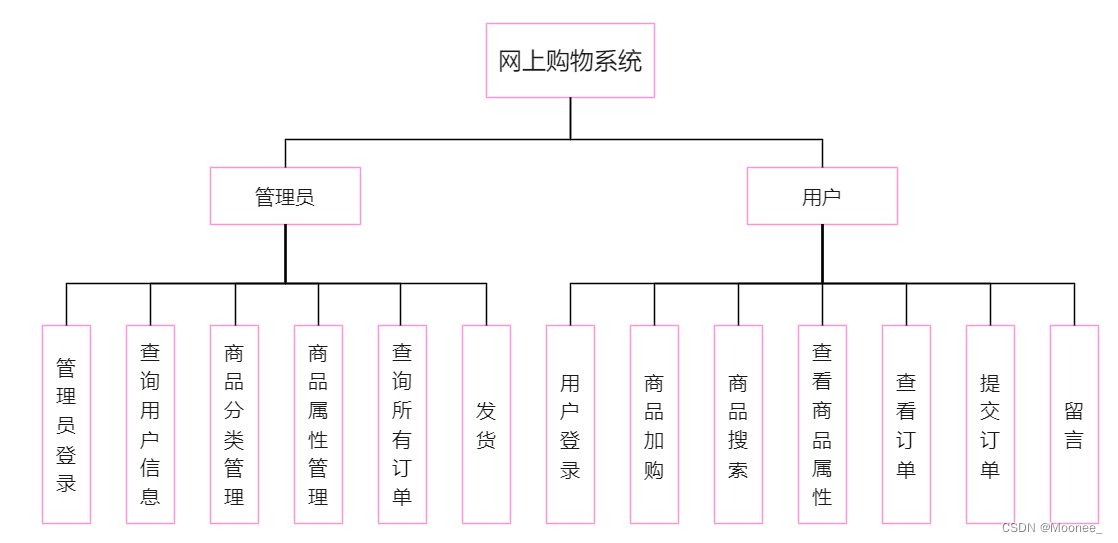
四、实现
1.整体代码结构

2.数据库表的结构

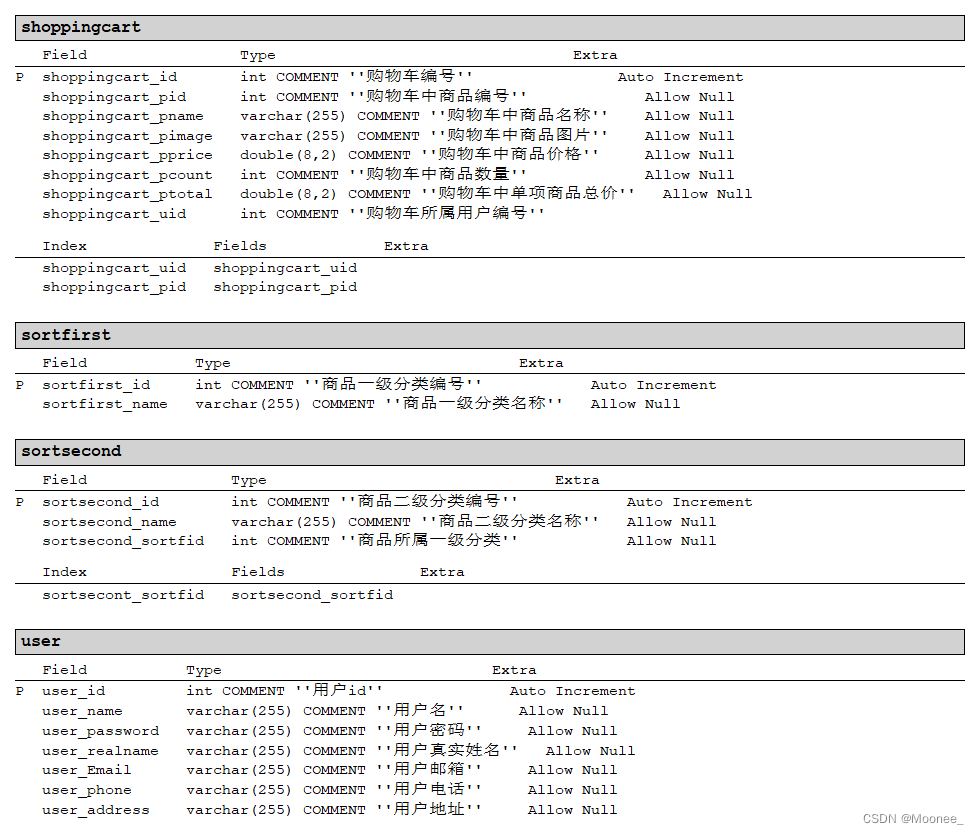
部分测试:
测试管理员视图:
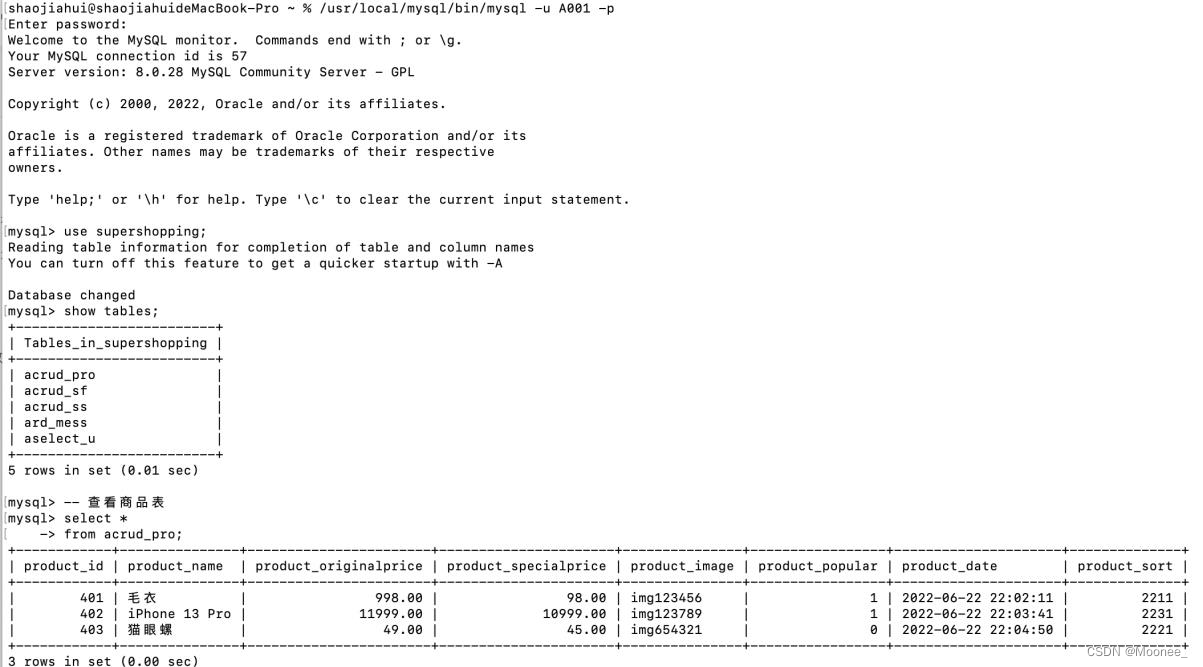
测试用户视图:

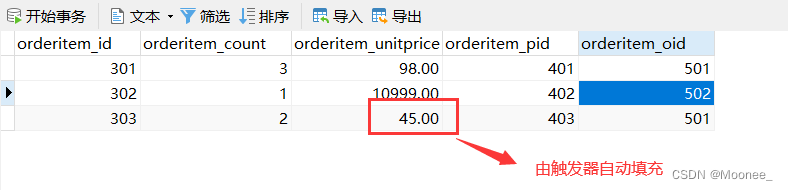
触发器:
部分效果展示:
购物车中添加新订单:

插入新的订单:
3.系统模块实现(管理员)
①管理员登录界面

②管理员主界面
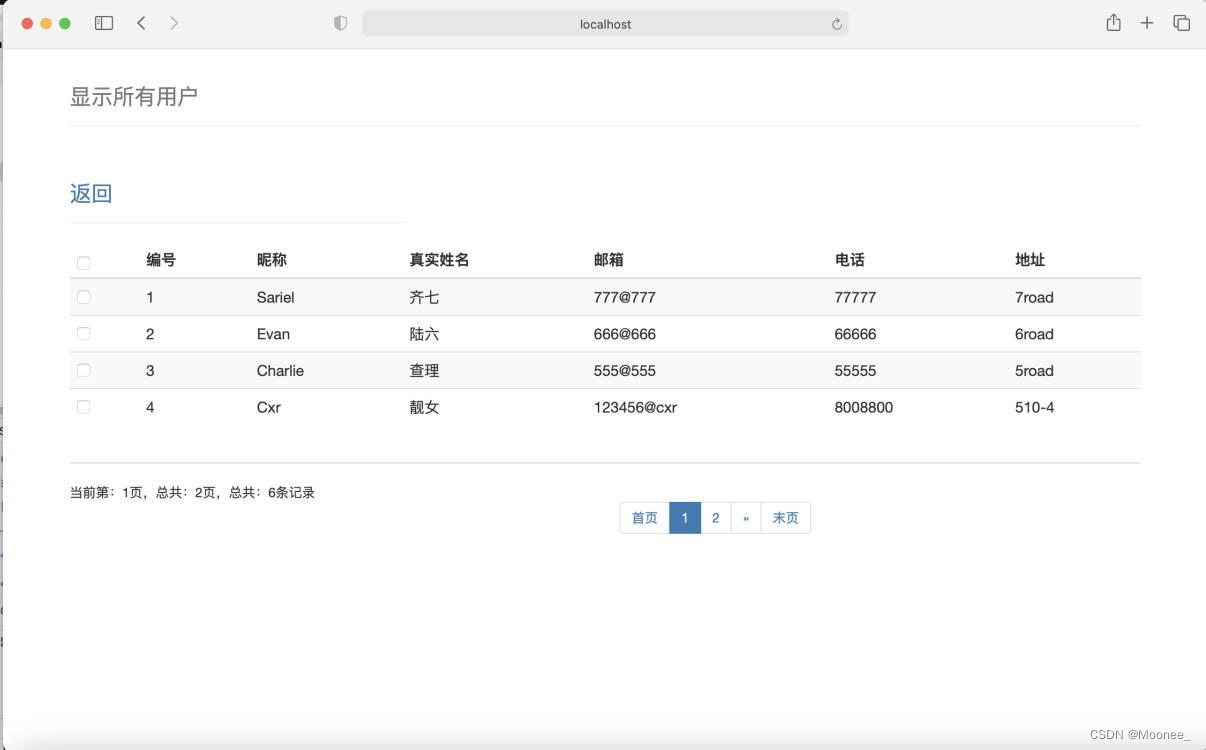
③管理员查询用户信息
④管理员管理一、二级分类信息
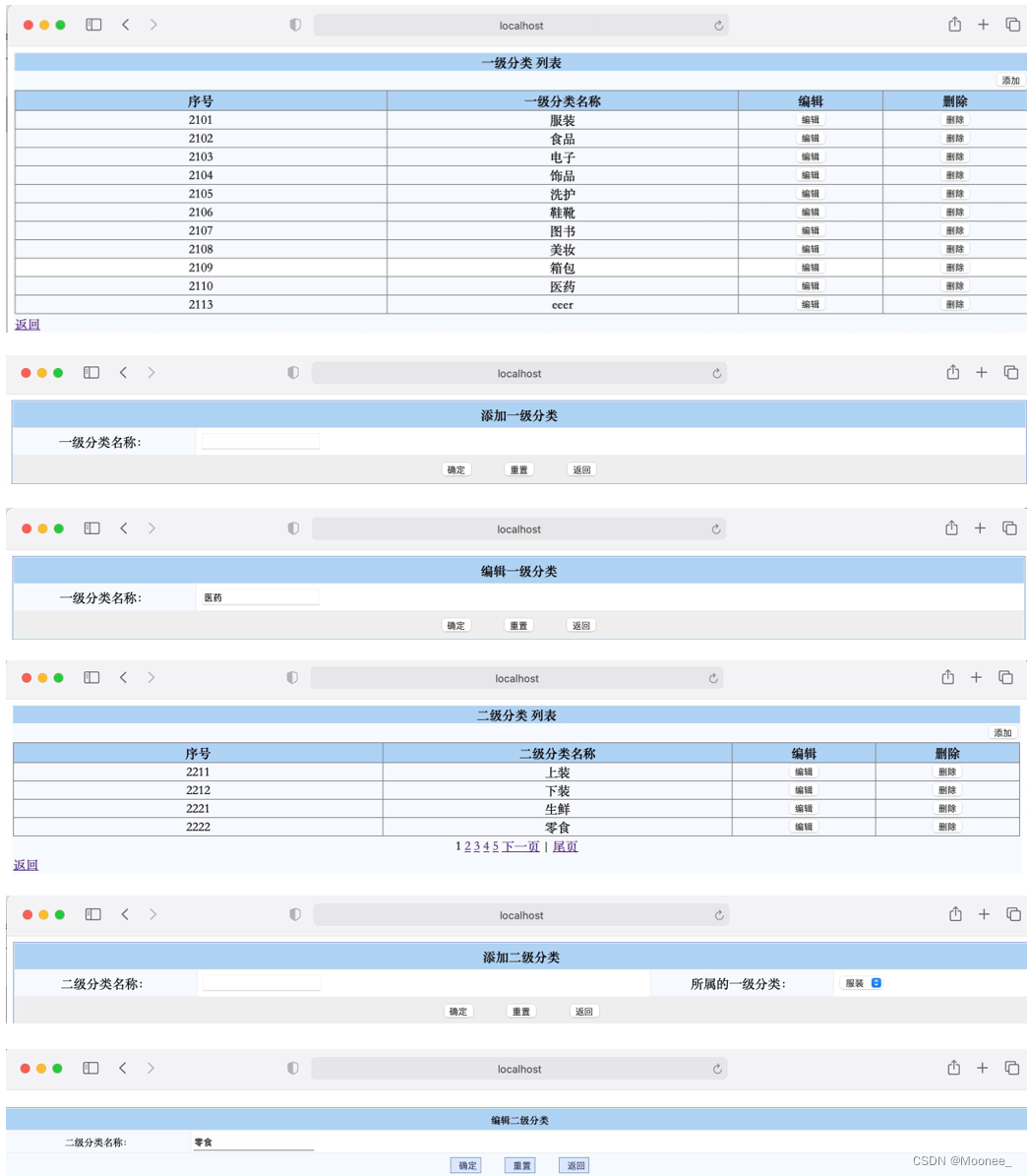
⑤管理员管理商品信息
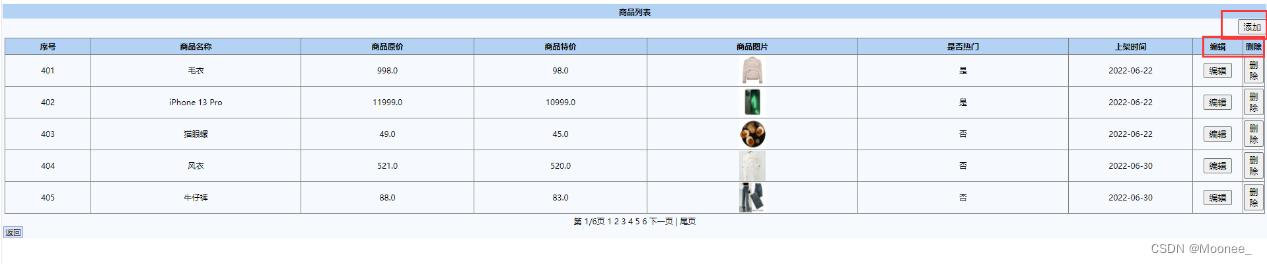


⑥管理员查询所有订单
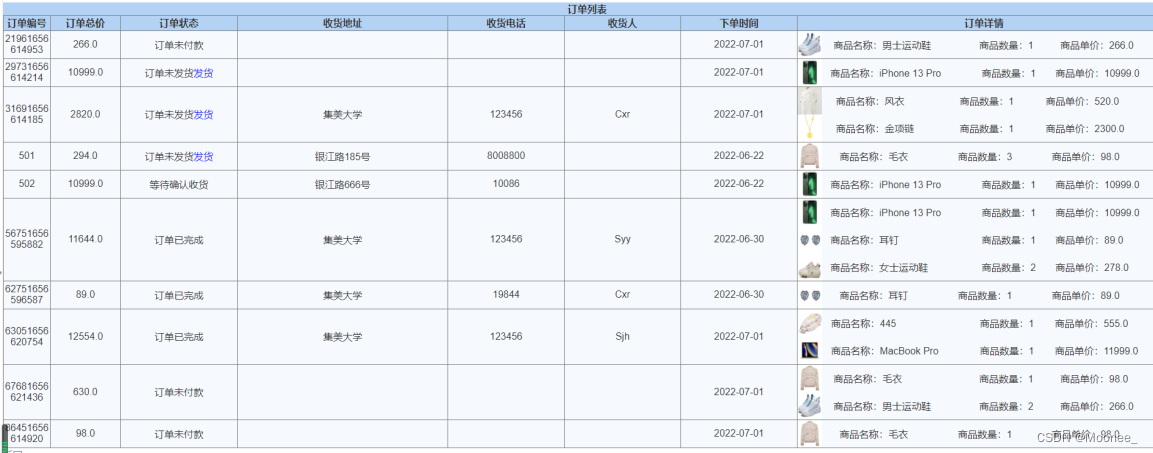
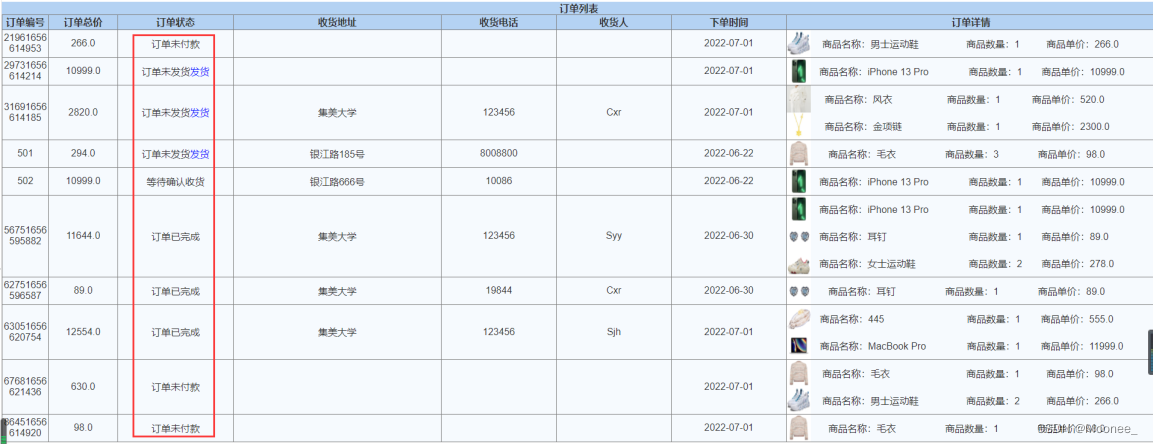
⑦管理员发货
⑧管理员退出

4.系统模块实现(用户)
①用户登录界面
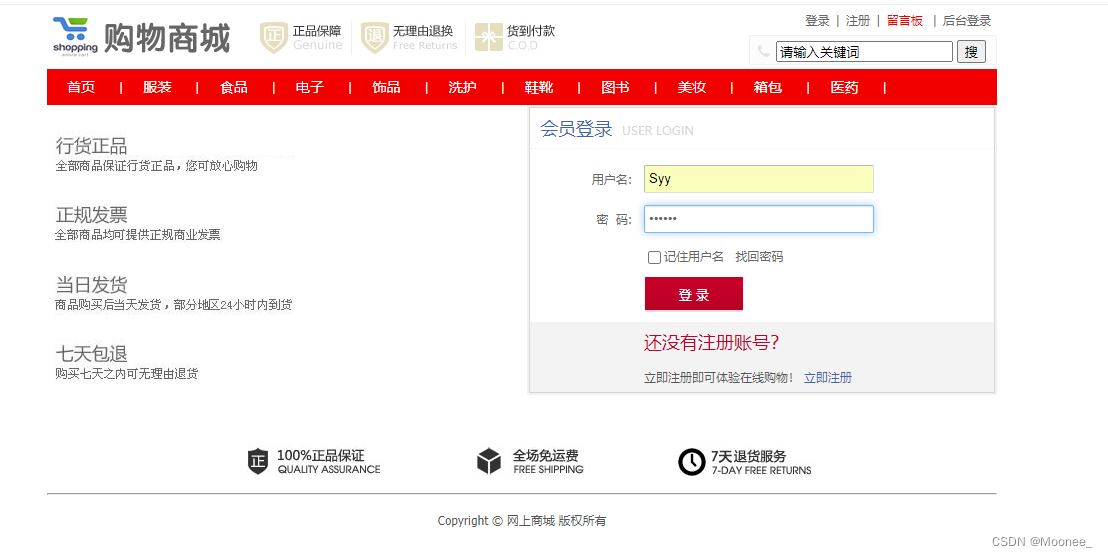
②用户注册界面

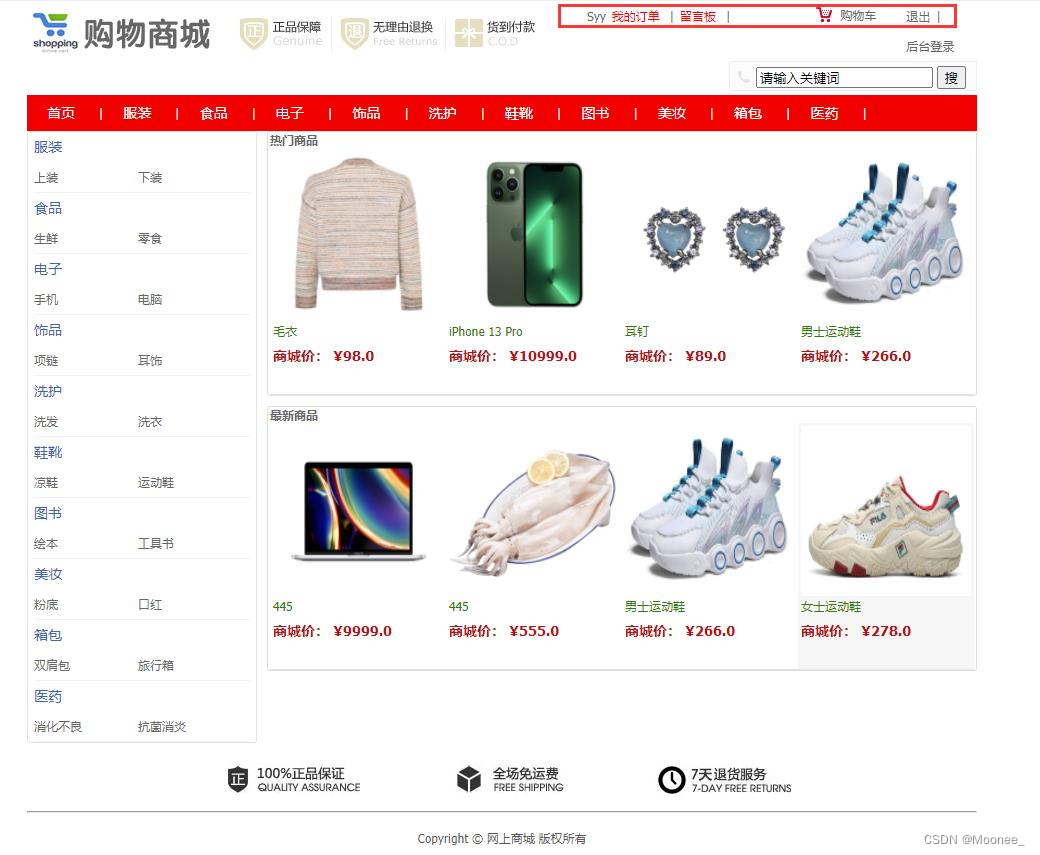
5.系统模块实现(商城)
①商城主界面
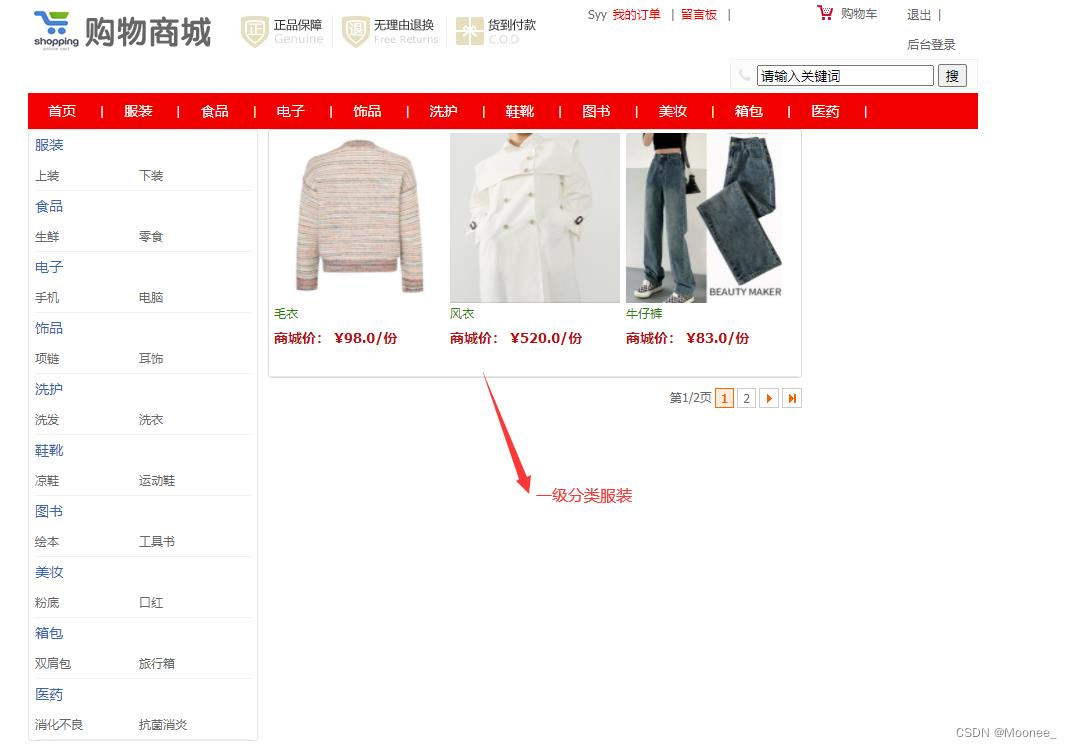
②一级分类界面
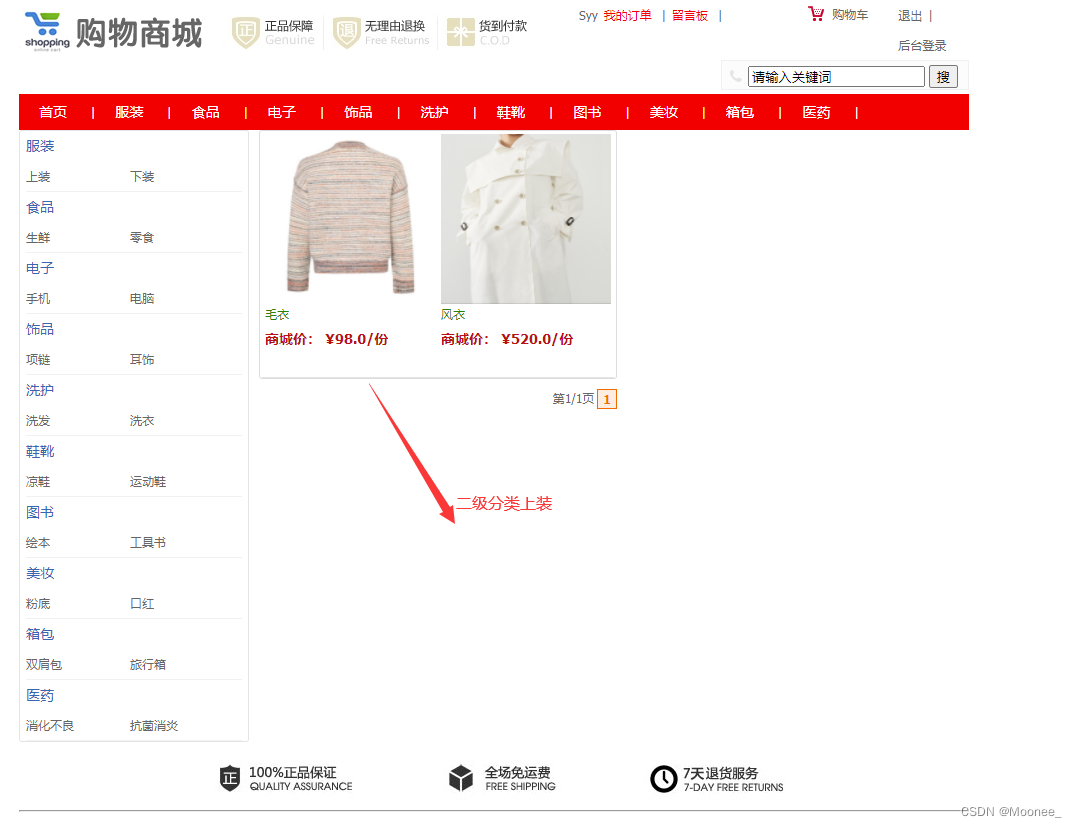
③二级分类界面
④商品详情界面
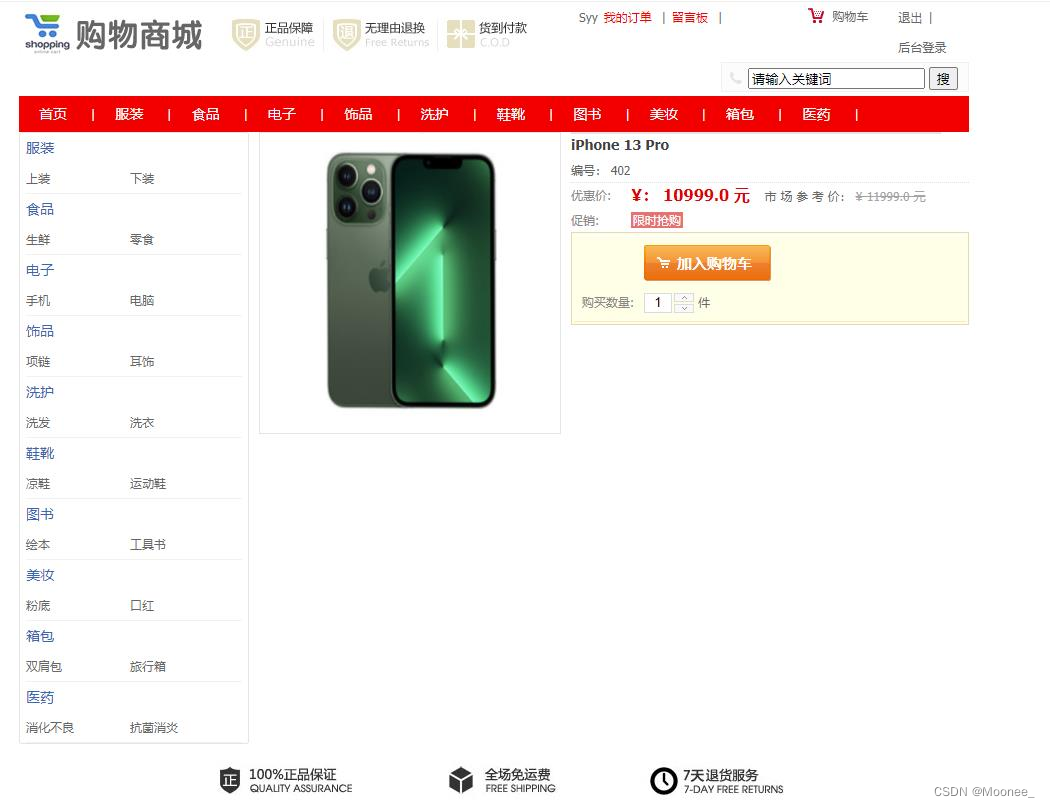
⑤购物车界面
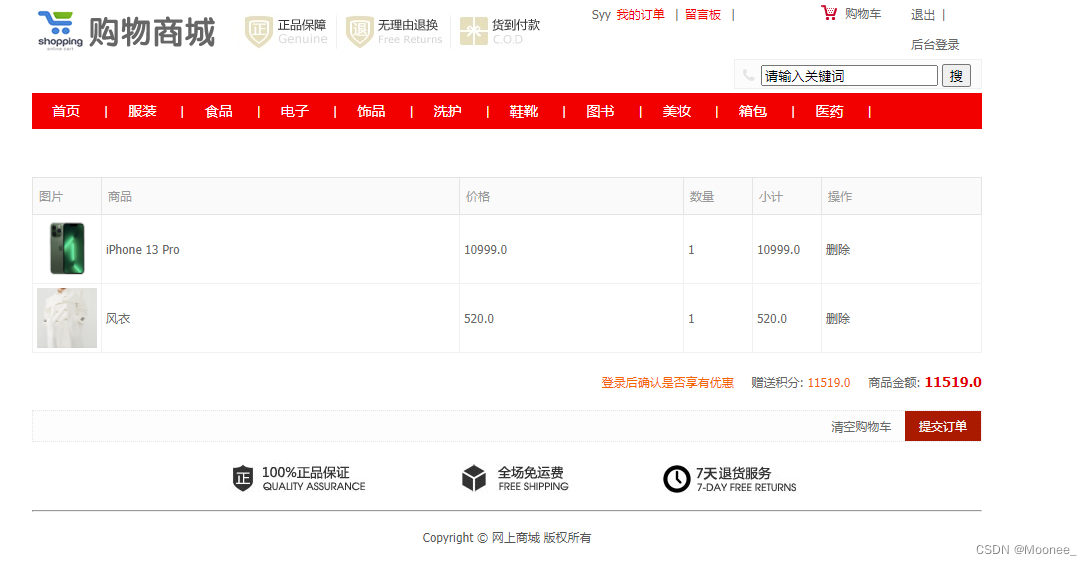
⑥订单提交界面
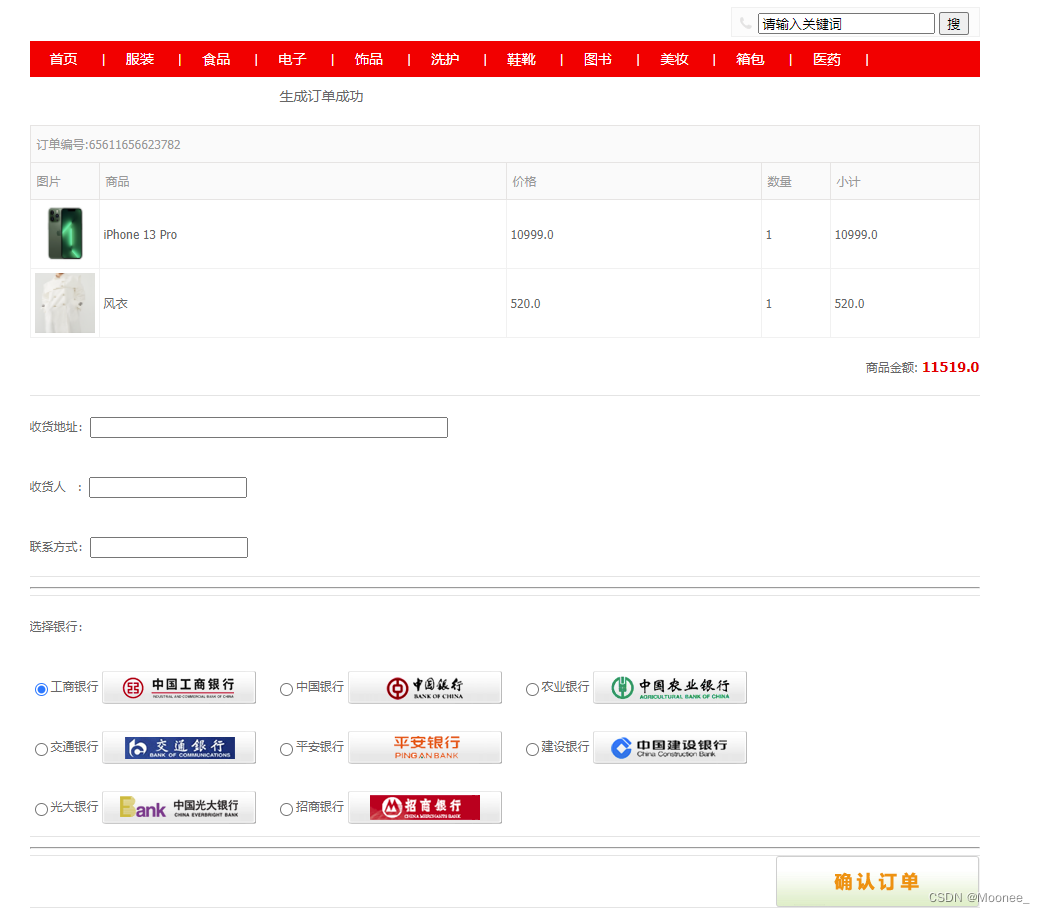
⑦订单信息界面
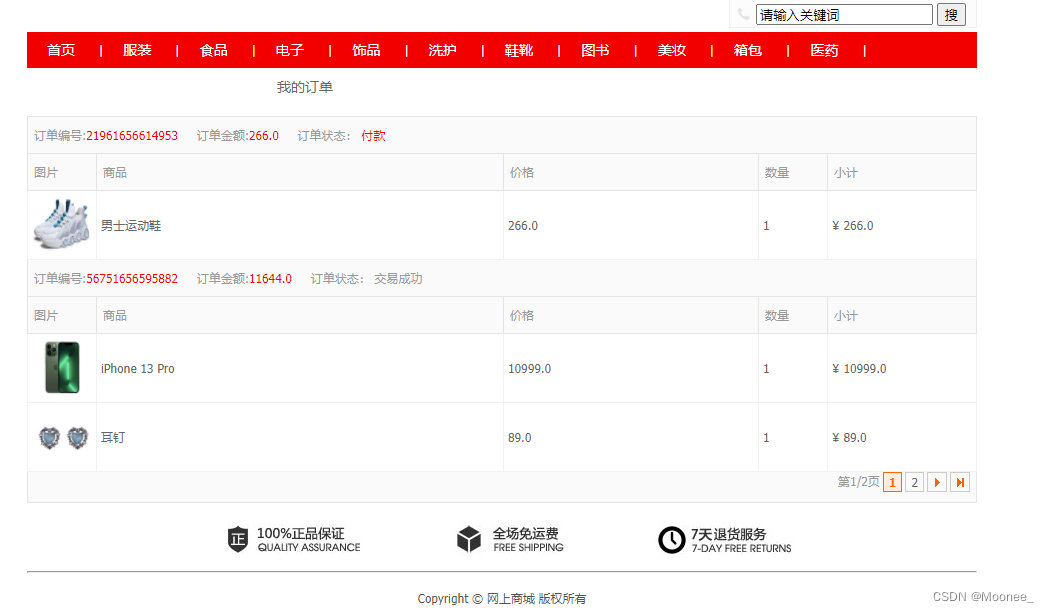
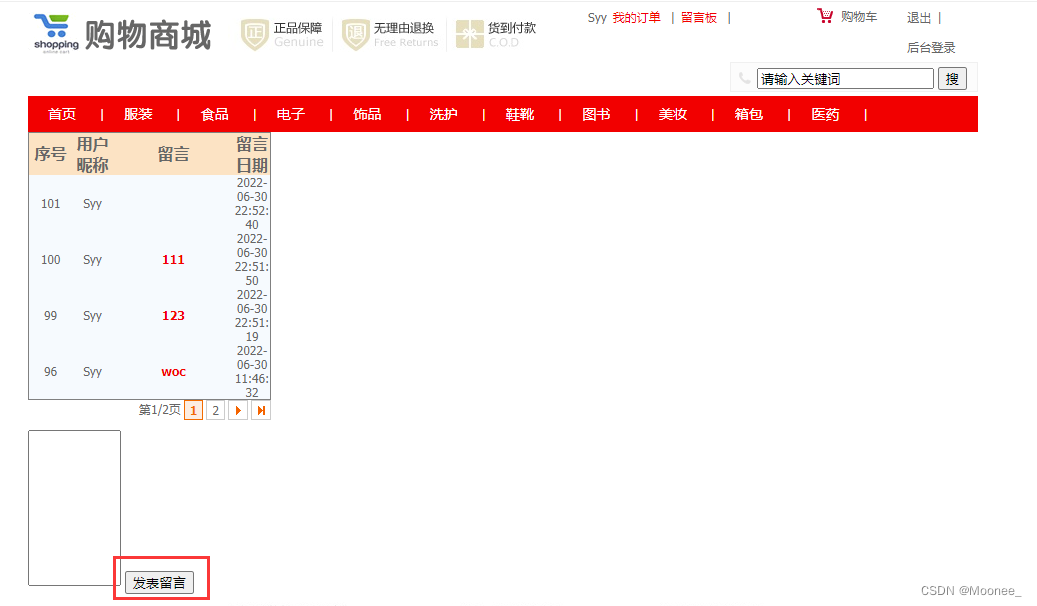
⑧留言板界面
说明:该项目仅为博主学习java+web框架设计的作业,必然存在缺陷与不足,仅供参考。
项目各部分功能实现java源码已上传至主页资源(https://download.csdn.net/download/Moonee_/88630914?spm=1001.2014.3001.5501)。愿意经济支持一下博主也可以直接付费购买此项目实现源码及数据库文件(拍下请私聊):


















 3340
3340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











