







深度学习实验六:对自有数据集进行图片标注及数据预处理
一、实验目的
参考“林业病虫害数据集和数据预处理方法介绍”(https://aistudio.baidu.com/projectdetail/5117657)构建自己的数据集。
大致步骤:收集图片,按一定比例划分训练集、验证集、测试集;用标注软件标注目标对象;数据读取和预处理,并可视化显示。
二、实验环境
python 3.7、PaddlePaddle 2.3.2、GPU V100 32GB
三、实验内容
1.构建我的数据集“poultry”
数据集“poultry”已上传至博主主页资源:https://download.csdn.net/download/Moonee_/88508712?spm=1001.2014.3001.5501
①结构
- 提供了100张图片,其中训练集77张,验证集11,测试集12张。
- 包含三种家禽,分别是chicken、duck和goose。
- 包含了图片和标注,后续解压存放在poultry目录下。
目录结构如下:
poultry
|---train
| |---annotations
| | |---xmls
| | |---chicken1.png
| | |---chicken2.png
| | |---...
| |
| |---images
| |---chicken1.png
| |---chicken2.png
| |---...
|
|---val
| |---annotations
| | |---xmls
| | |---chicken25.xml
| | |---chicken26.xml
| | |---...
| |
| |---images
| |---chicken25.png
| |---chicken26.png
| |---...
|---test
|---images
|---chicken29.png
|---chicken30.png
|---...
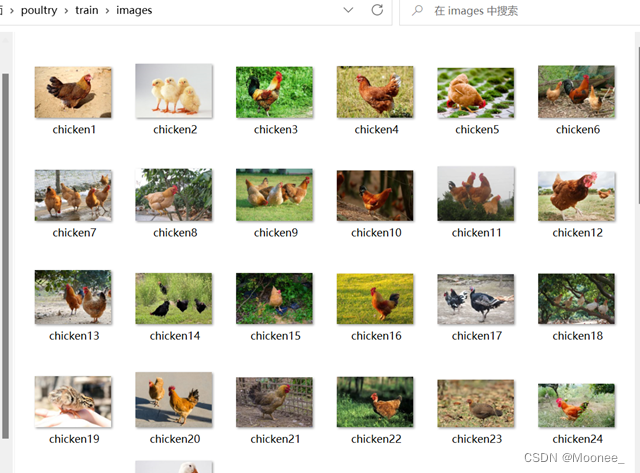
②图片标注
使用了图片标注工具labelimg对数据集中的图片进行真实框标注,并生成对应的xml文件。
(labelimg小巧方便蛮好用的,当然你也可以使用其他图片标注工具)
以文件duck11.png为例:

生成的xml文件:
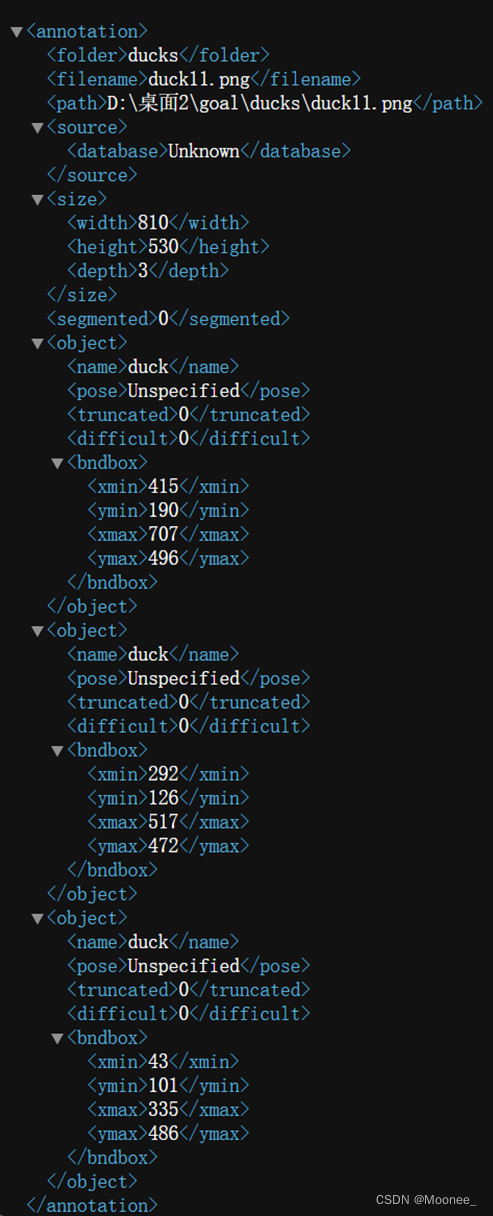
其主要参数说明如下:
- size:图片尺寸
- object:图片中包含的物体,一张图片可能中包含多个物体
- name:家禽名称
- bndbox:物体真实框
- difficult:识别是否困难
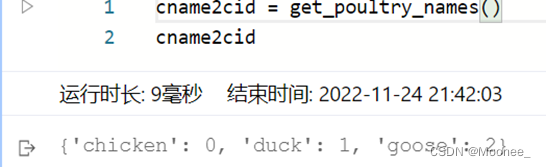
③将家禽的类别名字(字符串)转化成数字表示的类别。
因为神经网络里面计算时需要的输入类型是数值型的,所以需要将字符串表示的类别转化成具体的数字。
④读取标注数据
从annotations/xml目录下面读取所有文件标注信息。
(这部分代码不放了,想详细学习可以直接点进文章开头的链接去看)
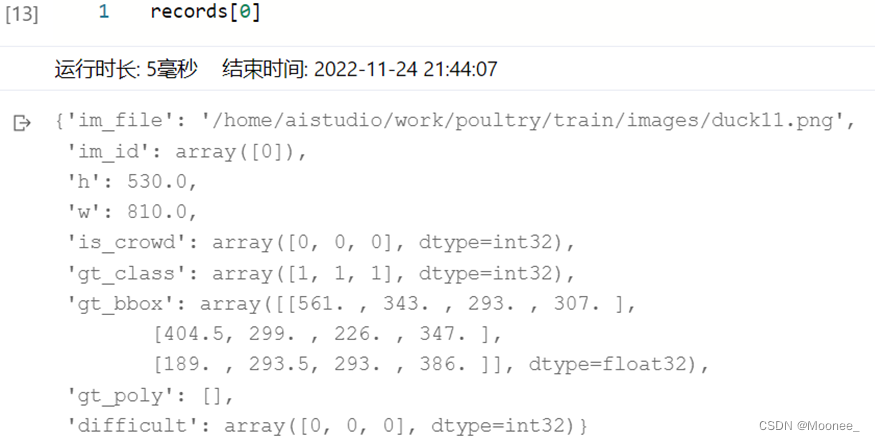
通过程序将所有训练数据集的标注数据全部读取出来了,存放在records列表下面,其中每一个元素是一张图片的标注数据,包含了图片存放地址,图片id,图片高度和宽度,图片中所包含的目标物体的种类和位置。
2.数据读取和预处理
①数据读取
根据records里面的描述读取图片及标注。
def get_bbox(gt_bbox, gt_class):
# 对于一般的检测任务来说,一张图片上往往会有多个目标物体
# 设置参数MAX_NUM = 10, 即一张图片最多取10个真实框;
# 如果真实框的数目少于10个,则将不足部分的gt_bbox, gt_class和gt_score的各项数值全设置为0
MAX_NUM = 10
gt_bbox2 = np.zeros((MAX_NUM, 4))
gt_class2 = np.zeros((MAX_NUM,))
for i in range(len(gt_bbox)):
gt_bbox2[i, :] = gt_bbox[i, :]
gt_class2[i] = gt_class[i]
if i >= MAX_NUM:
break
return gt_bbox2, gt_class2
def get_img_data_from_file(record):
im_file = record['im_file']
h = record['h']
w = record['w']
is_crowd = record['is_crowd']
gt_class = record['gt_class']
gt_bbox = record['gt_bbox']
difficult = record['difficult']
img = cv2.imread(im_file)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# check if h and w in record equals that read from img
assert img.shape[0] == int(h), \
"image height of {} inconsistent in record({}) and img file({})".format(
im_file, h, img.shape[0])
assert img.shape[1] == int(w), \
"image width of {} inconsistent in record({}) and img file({})".format(
im_file, w, img.shape[1])
gt_boxes, gt_labels = get_bbox(gt_bbox, gt_class)
# gt_bbox 用相对值
gt_boxes[:, 0] = gt_boxes[:, 0] / float(w)
gt_boxes[:, 1] = gt_boxes[:, 1] / float(h)
gt_boxes[:, 2] = gt_boxes[:, 2] / float(w)
gt_boxes[:, 3] = gt_boxes[:, 3] / float(h)
return img, gt_boxes, gt_labels, (h, w)
②数据预处理
数据预处理是训练神经网络时非常重要的步骤。合适的预处理方法,可以帮助模型更好的收敛并防止过拟合。
常用的方法主要有以下几种:
- 随机改变亮暗、对比度和颜色等
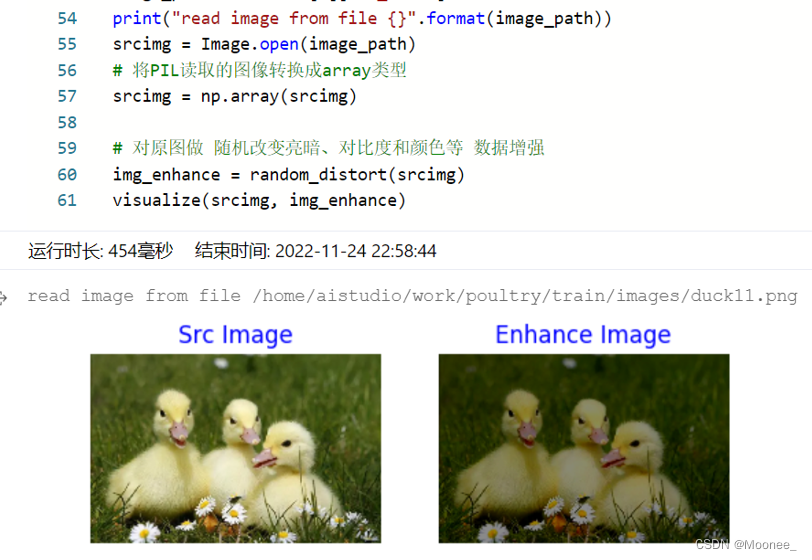
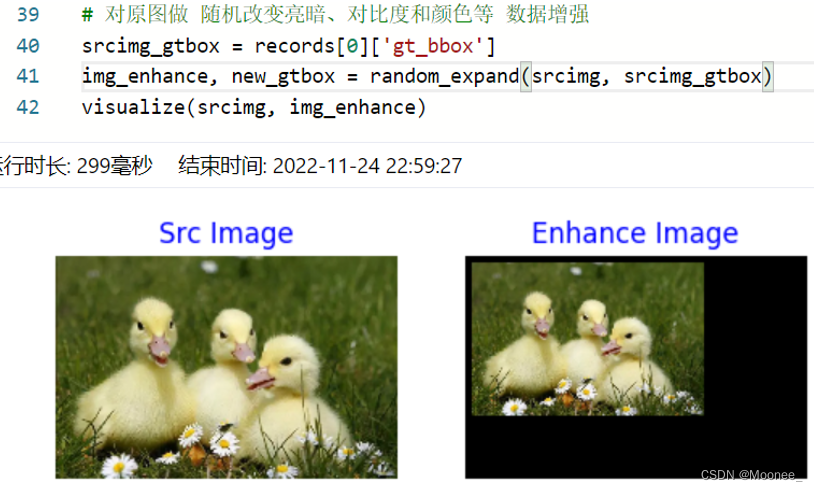
- 随机填充
- 随机裁剪

- 随机缩放

- 随机翻转

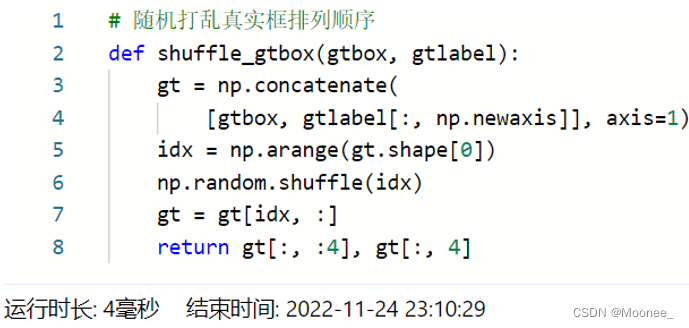
- 随机打乱真实框排列顺序
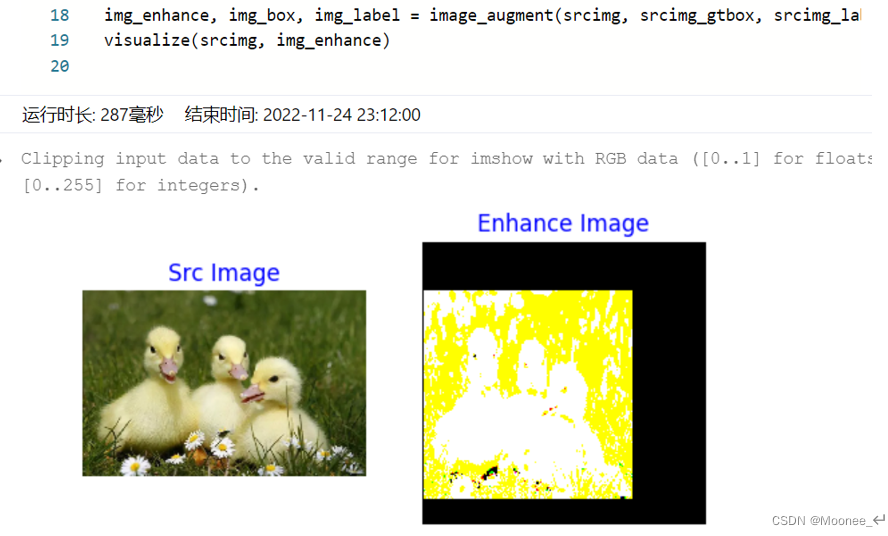
- 图像增广方法汇总
3. 使用飞桨高层API快速实现数据增强
除去使用numpy,百度飞桨提供了拿来即用的数据增强方法,方便快捷。
①实现亮度增强

②实现批量数据读取
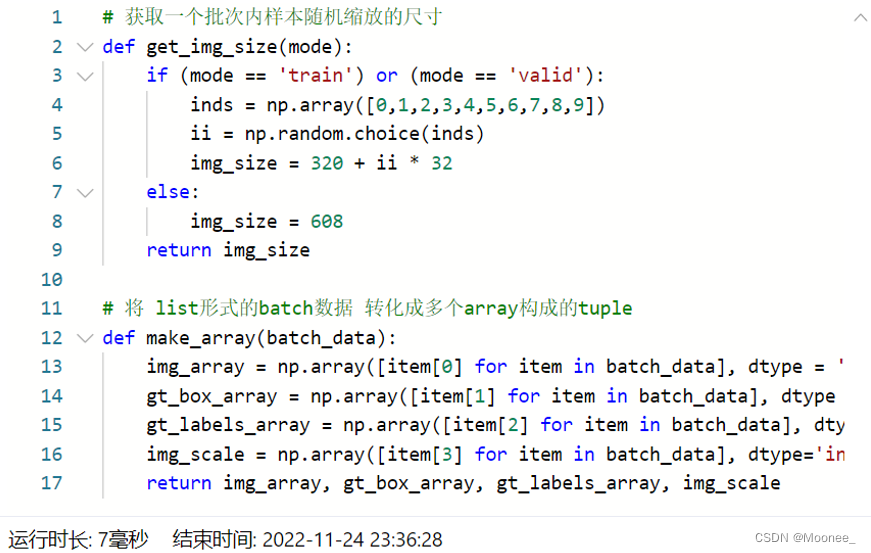
③实现数据优化加速
由于数据预处理耗时较长,可能会成为网络训练速度的瓶颈,所以需要对预处理部分进行优化。
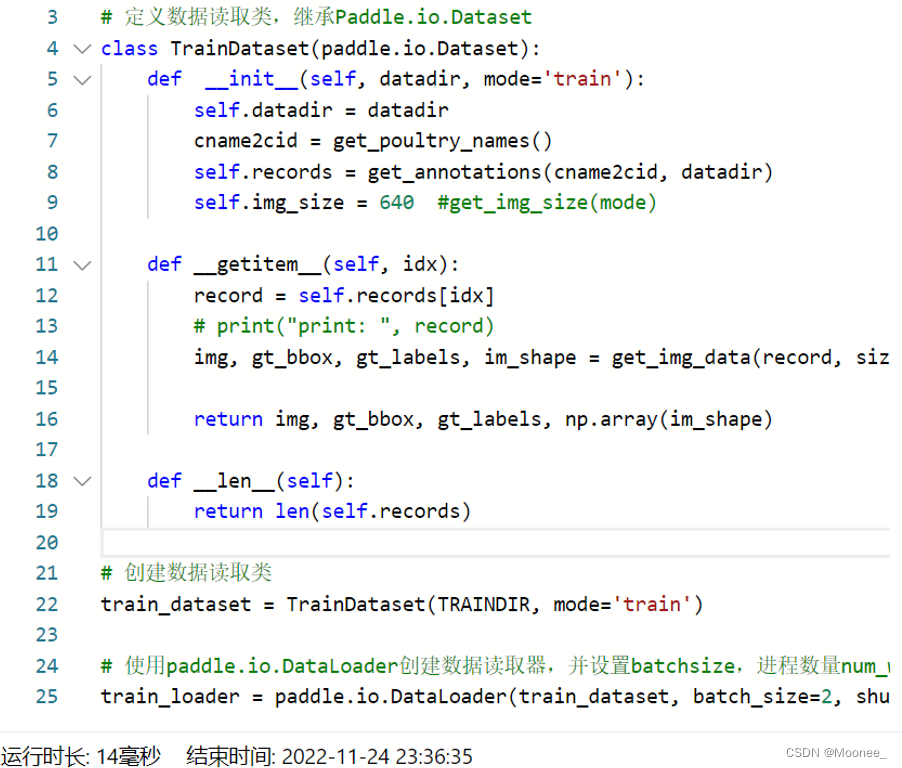
四、实验小结
代码运行中出现的错误:

解决方法:是random.randrange()函数中第1个参数大于第2个参数导致的,修正参数即可解决。

















 5357
5357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











