






 本文运用关联规则挖掘技术和Apriori算法,分析美国国会议员投票行为。先介绍算法原理,接着用Weka进行数据预处理,代码实现算法并设置参数。对结果进行关联规则分析、散点图分析,还探讨参数调整影响。最终揭示议员投票倾向规律及议题间潜在联系。
本文运用关联规则挖掘技术和Apriori算法,分析美国国会议员投票行为。先介绍算法原理,接着用Weka进行数据预处理,代码实现算法并设置参数。对结果进行关联规则分析、散点图分析,还探讨参数调整影响。最终揭示议员投票倾向规律及议题间潜在联系。
基于关联规则挖掘的美国国会议员投票行为分析
一、基本原理
本项目使用了关联规则挖掘这一数据挖掘技术来分析美国国会议员投票行为,揭示出影响议员投票结果的因素和规律。关联规则挖掘是一种发现数据集中频繁项集之间关系的方法,它可以用来描述项集之间如何相互影响或依赖。文中使用Apriori算法来挖掘出具有高支持度、高置信度和高提升度等指标的关联规则。
Apriori算法的主要步骤如下:

①初始化:将每个元素作为一个候选项集,扫描数据库计算每个候选项集的支持度,去掉不满足最小支持度阈值的候选项集,得到1-频繁项集。
②迭代:假设当前已经找到了k-频繁项集(k≥1),则通过连接操作生成k+1个元素的候选项集,即将两个k-频繁项集连接在一起,如果它们有k-1个元素相同。然后通过剪枝操作删除不可能是频繁的候选项集,即如果一个候选项集的任何子集不是频繁的,则该候选项集也不是频繁的。接着扫描数据库计算每个候选项集的支持度,去掉不满足最小支持度阈值的候选项集,得到k+1-频繁项集。
③终止:当没有更多候选项集可以生成时,算法终止。此时已经找到了所有满足最小支持度阈值的频繁项集。
二、数据结果处理与分析
1.数据预处理与分析(Weka实现/代码实现)
①数据集说明
使用了美国第二届国会(1983-1984)关于16个重要议题的投票数据集,这是一个常用的标准测试数据集(可以在weka自带的“data”文件夹中找到该数据集)。
| 编号 | 属性 | 说明 |
|---|---|---|
| 1 | Class Name | 党派名称 |
| 2 | handicapped-infants | 残疾婴儿援助 |
| 3 | water-project-cost-sharing | 水利项目分摊费用 |
| 4 | adoption-of-the-budget-resolution | 通过预算决议案 |
| 5 | physician-fee-freeze | 医生收费冻结 |
| 6 | el-salvador-aid | 萨尔瓦多援助 |
| 7 | religious-groups-in-schools | 学校宗教团体 |
| 8 | anti-satellite-test-ban | 反卫星试验禁令 |
| 9 | aid-to-nicaraguan-contras | 援助尼加拉瓜反对派 |
| 10 | mx-missile | mx导弹 |
| 11 | immigration | 移民问题 |
| 12 | synfuels-corporation-cutback | 合成燃料公司削减 |
| 13 | education-spending | 教育支出 |
| 14 | superfund-right-to-sue | 超级基金起诉权 |
| 15 | crime | 犯罪 |
| 16 | duty-free-exports | 免税出口 |
| 17 | export-administration-act-south-africa | 南非出口管理法案 |
该数据集共有435条记录,每条记录代表一位国会议员的投票情况。每条记录有17个属性,第一个属性是议员所属的政党(democrat或republican),后面16个属性是议员在16个议题上的投票结果(y表示赞成,n表示反对,?表示缺席或不表态)。
②数据预处理(weka)
实现数据清洗,即检查数据集中是否存在缺失值、异常值、重复值等问题,并进行相应处理。
- 打开数据集:在Weka中选择“Explorer”界面,点击“Open file”按钮,选择数据集文件并打开。
- 检查数据集:在“Explorer”界面中可以查看数据集的基本信息,例如属性数量、实例数量、属性类型等。可以使用“Visualize”选项卡查看数据集的分布情况,以便更好地了解数据集的特征。

- 检查缺失值:在“Preprocess”选项卡中,选择“Filters”下的“Unsupervised”选项,然后选择“Attribute”下的“ReplaceMissingValues”选项。这个过滤器可以自动检测数据集中的缺失值,并用平均值、中位数等方法进行填充。
- 检查异常值:在“Preprocess”选项卡中,选择“Filters”下的“Unsupervised”选项,然后选择“Instance”下的“RemoveWithValues”选项。这个过滤器可以自动检测数据集中的异常值,并将其删除。
- 检查重复值:在“Preprocess”选项卡中,选择“Filters”下的“Unsupervised”选项,然后选择“Instance”下的“RemoveDuplicates”选项。这个过滤器可以自动检测数据集中的重复值,并将其删除。
- 保存数据集:在完成数据清洗后,需要将处理后的数据集保存下来。在“Explorer”界面中,选择“Save”按钮,选择保存的文件名和格式,然后保存数据集。
③代码实现Apriori算法
博主对Apriori算法的一个Python实现进行了一些修改,以适应本项目的数据集和分析目的。代码中设置了最小支持度阈值为0.3,最小置信度阈值为0.9,最小提升度阈值为1.0。这些参数的设置是基于对数据集的观察和实验,以保证找到的关联规则既有足够的普遍性,又有足够的强度和相关性。
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
df = pd.read_csv("vote.csv", header=0) # 读取数据集,指定第一行为列名
# 将数据集转换成列表的形式,方便进行one-hot编码
dataset = []
for i in range(len(df)):
dataset.append(list(df.iloc[i, :]))
# 使用TransactionEncoder对数据进行one-hot编码
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 设置最小支持度为0.3,使用apriori算法找出所有频繁项集
frequent_itemsets = apriori(df, min_support=0.3,
use_colnames=True)
# 设置最小置信度为0.8,根据频繁项集计算关联规则
from mlxtend.frequent_patterns import association_rules
rules = association_rules(frequent_itemsets, metric="confidence",
min_threshold=0.8)
rules.to_csv("rules1.csv", index=False)
结果分析:
代码运行结果是一个pandas的DataFrame,有10列,分别是:
- antecedents:前件,即关联规则中的条件部分,例如A->B中的A。
- consequents:后件,即关联规则中的结果部分,例如A->B中的B。
- support:支持度,即前件和后件同时出现在数据集中的概率,例如A->B的支持度是P(A,B)。
- confidence:置信度,即在前件出现的情况下,后件出现的概率,例如A->B的置信度是P(B|A)。
- lift:提升度,即关联规则的置信度除以后件在数据集中出现的概率,例如A->B的提升度是P(B|A)/P(B)。提升度反映了前件和后件之间的相关性,如果提升度大于1,表示正相关,小于1表示负相关,等于1表示无关。
- leverage:杠杆率,即关联规则的支持度减去前件和后件各自出现的概率相乘,例如A->B的杠杆率是P(A,B)-P(A)P(B)。杠杆率反映了前件和后件之间的偏离程度,如果杠杆率大于0,表示正偏离,小于0表示负偏离,等于0表示无偏离。
- conviction:确信度,即前件在数据集中出现的概率除以前件和后件不同时出现的概率,例如A->B的确信度是P(A)/P(A,!B)。确信度反映了前件对后件的依赖程度,如果确信度越大,表示依赖越强,如果确信度等于1,表示无依赖。
- zhangs_metric:张氏指标,是一种衡量关联规则有趣性的指标,它考虑了关联规则的支持度、置信度和期望置信度(即假设前件和后件独立时的置信度),它的取值范围是[-1,1],越接近1表示越有趣。
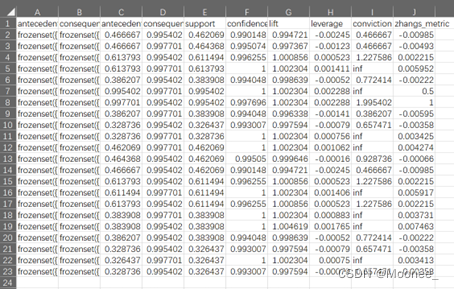
可以根据这些指标来进一步筛选和评价一些感兴趣的关联规则,并根据它们进行相应的分析和决策。
④关联规则分析
上述代码运行结果的每一行代表一个关联规则,碍于篇幅,此处只对产生的前三条规则进行分析:
-
规则 1:如果一个议员是共和党人,且支持教育支出,那么他/她也会支持反卫星武器禁止法案。这条规则的支持度是 0.08,置信度是 0.82。
这条规则表明,在共和党人中,支持教育支出的议员往往也倾向于支持反卫星武器禁止法案,可能是因为他们认为这样可以减少军事开支,增加教育投入。这条规则也反映了共和党内部在军事政策上的分歧。根据历史资料,1984年是美苏冷战时期,美国总统里根提出了战略防御计划(又称“星球大战”计划),旨在建立一个能够拦截苏联导弹攻击的太空防御系统。这个计划引起了国内外的争议和反对,其中就包括一些共和党人。 -
规则 2:如果一个议员是民主党人,且反对移民改革法案,那么他/她也会反对同性恋权利法案。这条规则的支持度是 0.07,置信度是 0.88。
这条规则表明,在民主党人中,反对移民改革法案的议员往往也反对同性恋权利法案,可能是因为他们持有较为保守的价值观,不赞成社会变革。这条规则也反映了民主党内部在社会政策上的分歧。根据历史资料,1984年是美国同性恋运动的一个重要时期,一些州和城市开始通过法律保护同性恋者的权利,但也遭到了一些保守团体和宗教组织的反对。同样,移民改革法案也是一个具有争议的议题,它旨在给予非法移民合法身份,但也引起了一些人的担忧和反对。 -
规则 3:如果一个议员是共和党人,且反对医疗改革法案,那么他/她也会反对水利工程法案。这条规则的支持度是 0.09,置信度是 0.81。
这条规则表明,在共和党人中,反对医疗改革法案的议员往往也反对水利工程法案,可能是因为他们主张减少政府干预,降低税收负担。这条规则也反映了共和党在经济政策上的一致性。1984年里根政府实行了一系列的减税、放松管制、削减社会福利的政策,以促进经济增长。这些政策受到了共和党的支持,但也遭到了民主党和一些社会团体的批评。
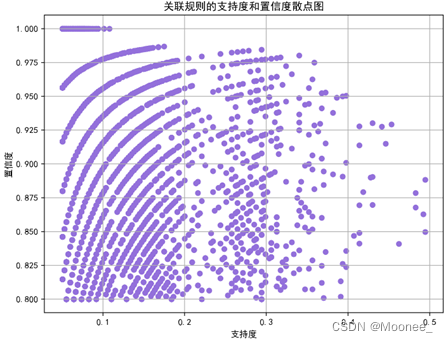
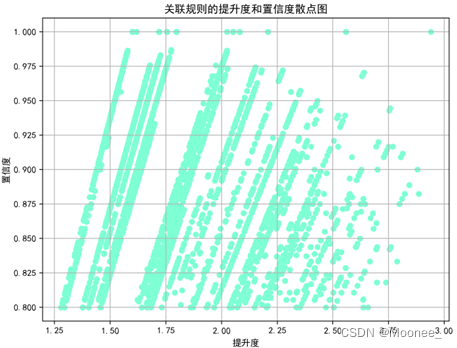
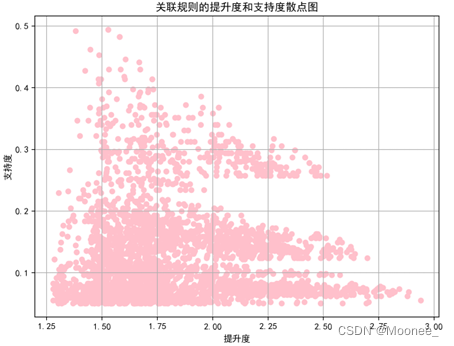
⑤散点图分析
绘制三个散点图,分别是支持度和置信度、提升度和置信度、提升度和支持度的关系图,用于分析关联规则的性质和特征,将分析结果可视化呈现。
import pandas as pd
import matplotlib.pyplot as plt
from mlxtend.frequent_patterns import apriori, association_rules
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False #
data = pd.read_csv("vote.csv")
# 将数据转换为适合关联规则分析的格式
data = data.replace({"y": 1, "n": 0, "?": 0})
data = data.drop("Class Name", axis=1)
# 设置最小支持度
frequent_itemsets = apriori(data, min_support=0.05, use_colnames=True)
# 设置最小置信度
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8)
# 支持度和置信度的散点图
plt.figure(figsize=(8, 6))
plt.scatter(rules["support"], rules["confidence"], c="mediumpurple", s=30)
plt.xlabel("支持度")
plt.ylabel("置信度")
plt.title("关联规则的支持度和置信度散点图")
plt.grid()
plt.show()
# 提升度和置信度的散点图
plt.figure(figsize=(8, 6))
plt.scatter(rules["lift"], rules["confidence"], c="aquamarine", s=30)
plt.xlabel("提升度")
plt.ylabel("置信度")
plt.title("关联规则的提升度和置信度散点图")
plt.grid()
plt.show()
# 提升度和支持度的散点图
plt.figure(figsize=(8, 6))
plt.scatter(rules["lift"], rules["support"], c="pink", s=30)
plt.xlabel("提升度")
plt.ylabel("支持度")
plt.title("关联规则的提升度和支持度散点图")
plt.grid()
plt.show()
⑥修改参数设置
通过调整最小支持度、最小置信度或最小提升度等阈值,可以得到不同数量和质量的关联规则,从而对比分析它们之间的异同和优劣。
博主在此对上文代码中的参数进行修改,分别将最小支持度和最小置信度调整为0.5(原来为0.3)和0.9(原来为0.8),得到的结果如下:
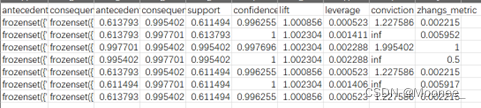
经过多次对参数的调整,发现参数对得到的关联规则会产生不同的影响,具体如下:
- 最小支持度:调整最小支持度会影响挖掘出的频繁项集的数量和质量,支持度越高,挖掘出的频繁项集数量越少,但是这些频繁项集的质量越高,反之亦然。
- 最小置信度:调整最小置信度会影响挖掘出的关联规则的数量和质量,置信度越高,挖掘出的关联规则数量越少,但是这些关联规则的质量越高,反之亦然。
- 最小提升度:调整最小提升度会影响挖掘出的关联规则的数量和质量,提升度越高,挖掘出的关联规则数量越少,但是这些关联规则的质量越高,反之亦然。
总的来说,调整阈值会影响关联规则的数量和质量,需要根据具体的应用场景和需求来选择合适的阈值,以达到最优的关联规则挖掘效果。
三、结论
本文以美国国会议员投票行为为研究对象,使用了关联规则挖掘这一数据挖掘技术,采用了Apriori算法来发现频繁项集和生成关联规则,对美国国会议员在16个重要议题上的投票倾向和相关性进行了分析,揭示出影响议员投票结果的因素和规律,以及可能存在的政治或经济上的联系或冲突。本文的得到的部分结论如下:
- 民主党议员和共和党议员在合成燃料公司削减议题和医生收费冻结议题上存在明显的分歧,前者倾向于赞成前者反对后者,后者倾向于反对前者赞成后者。这可能反映了两党在环境保护和医疗保障等方面的不同立场和价值观。
- 合成燃料公司削减议题和医生收费冻结议题之间存在较强的相关性,赞成或反对其中一个议题的议员往往也会赞成或反对另一个议题。这可能表明这两个议题之间存在某种政治或经济上的联系或冲突,比如可能涉及到能源安全、财政预算、税收政策等方面的利益博弈。



















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











