







第一章
1.1 基本术语
(色泽=青绿;根蒂=蜷缩;敲声=浊响),
(色泽=乌黑;根蒂=稍蜷;敲声=沉闷),
(色泽=浅白;根蒂=硬挺;敲声=清脆),...
-
数据集(data set):上述记录的集合。
-
示例(instance)、样本(sample):每条记录关于事件或对象(这里是西瓜)的描述。
-
属性(attribute)、特征(feature):反映事件或对象在某方面的的表现或性质的事项,如“色泽”、“根蒂”、“敲声”。
-
属性值(attribute value):属性上的取值,如“青绿”、“乌黑”。
-
属性空间(attribute space)、样本空间(sample space)、输入空间(input space):属性张成的空间。如:把“色泽”、“根蒂”、“敲声”作为三个坐标轴,则他们张成一个用于描述西瓜的三维空间,每个西瓜都可以在这个空间中找到自己的坐标位置。
-
特征向量(feature vector):由于空间中的每个店对应一个坐标向量,因此我们也把一个示例称为一个特征向量。
一般地,令 D = { x 1 , x 2 , . . . x m } D=\{x_1,x_2,...x_m\} D={x1,x2,...xm}表示包含 m m m个示例的数据集。
每个示例由 d d d个属性描述, d d d称为样本 x i x_i xi的**“维数”(dimensionality)**
每个示例 x i = ( x i 1 ; x i 2 ; . . . ; x i d ) x_i=(x_{i1};x_{i2};...;x_{id}) xi=(xi1;xi2;...;xid)是d维样本空间 X X X中的一个向量, x i ∈ X x_i\in X xi∈X
其中 x i j x_{ij} xij是 x i x_i xi在第 j j j个属性上的取值。(如:上述第3个西瓜在第2个属性上的值 x 32 = 硬 挺 x_{32}=硬挺 x32=硬挺)
- 学习(learning)、训练(training):从数据中学的模型的过程,该过程通过执行某个学习算法来完成。
- 训练数据(training data):训练过程中使用的数据。
- 训练样本(training sample):训练数据中的每一个样本称为一个。
- 训练集(training set):训练样本组成的集合。
- 假设(hypothesis):学的模型对应了关于数据的某种潜在规律。
- 真相、真实(ground-truth):这种潜在规律自身,学习的过程就是为了找出或逼近真相。
- 学习器(learner):本书有时将模型称为学习器,可以看做学习算法在给定数据和参数空间上的实例化。
为了判断没有切开的瓜是不是好瓜,建立**预测(prediction)**的模型,我们需要获得训练样本的“结果”。
例如:((色泽=青绿;根蒂=蜷缩;敲声=浊响),好瓜)。
- 标记(label):关于示例的信息,即“好瓜”。
- 样例(example):拥有了标记信息的示例。
一般地,用 ( x i , y i ) (x_i,y_i) (xi,yi)表示第 i i i个样例,其中 y i ∈ Y y_i \in Y yi∈Y是示例 x i x_i xi的标记, Y Y Y是所有标记的集合,称为标记空间(label space)或输出空间(output space)。
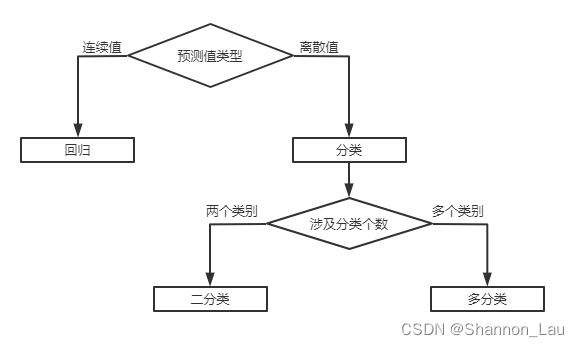
- 分类(classification):离散值
- 回归(regression):连续值
- 二分类(binary classification):两个类别,其中一个类为正类(positive class),另一个称为反类(negative class)或负类。
- 多分类(multi-class classification):涉及多个类别。
一般地,预测任务是通过对训练集 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } \{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\} {(x1,y1),(x2,y2),...,(xm,ym)}进行学习,建立一个从输入空间 X X X到输出空间 Y Y Y的映射$ f:X \to Y$。
对于二分类: Y = { − 1 , + 1 } Y=\{-1,+1\} Y={−1,+1}或 { 0 , 1 } \{0,1\} {0,1};
对于多分类:$\abs{Y} \gt 2 $;
对于回归任务: Y ∈ R , R 为 实 数 集 Y \in R ,R为实数集 Y∈R,R为实数集。
- 测试(testing):学的模型行后,使用其进行预测的过程。
- 测试样本(testing sample):被预测的样本。
如:学得 f f f之后,对测试例 x x x,可得到预测标记 y = f ( x ) y=f(x) y=f(x)
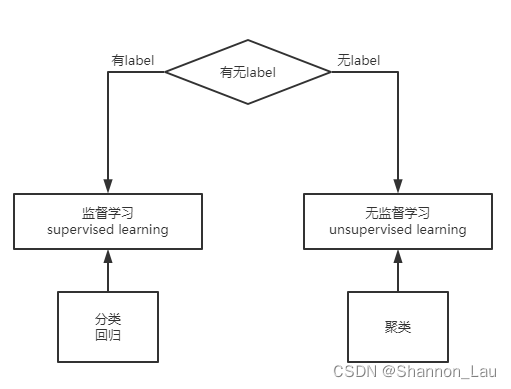
- 聚类(clustering):将训练集中的西瓜分成若干组。
- 簇(cluster):每一组。
这些自动生成的簇可能对应一些潜在的概念划分,如:“浅色瓜”、“本地瓜”。这样的学习过程有助于我们了解数据内在的规律,能更深入的分析数据建立基础。
重要的是:在聚类学习的过程,我们不知道他会根据什么概念划分,即不知道“浅色瓜”、“本地瓜”这样的概念,且学习的过程中使用的训练样本通常不拥有标记信息。
- 学习任务类型
- 机器学习的目标
使学得的模型能很好的适用于“新样本”,而不仅仅在训练样本上工作的很好。
- 泛化能力(generalization):学得模型适用于新样本的能力。
具有强泛化能力的模型能很好地适用于整个样本空间,训练集虽然是样本空间的一个很小的采样,我们任然希望它能很好地反应出样本空间的特性。
我们通常假设样本空间中全体赝本服从一个未知**“分布”(distribution) D D D,我们获得的每个样本都是独立同分布(independent and identically distribution, 简称 i,i,d)**.
一般而言,训练样本越多,关于 D D D的信息越多,越有可能通过学习获得具有强泛化能力的模型。
1.2 假设空间
-
科学推理的两大基本手段:
-
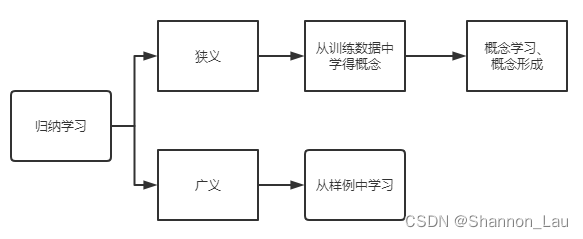
归纳(induction)
从特殊到一般的“泛化”(generalization)过程,从具体事实归结出一般规律。
ep:“从样例中学习”显然是一个归纳的过程,因此亦称为“归纳学习”(inductive learning)
-
演绎(deduction)
从一般到特殊的“特化”(specialization)过程,从基本原理推演出具体状况。
ep:基于一组公理和推理规则推导出与之相洽的定理,这是演绎。
-
概念学习技术目前研究、应用比较少,因为要学得性能好的概念模型很难。现阶段常用“黑箱”模型。
- 布尔概念学习
这是概念学习中最基本的,即对“是”“不是”这样的可表示为0/1布尔值得目标概念的学习。

通过以上数据集学习“好瓜”
由三个属性判断,于是将学到“好瓜是某种色泽、某种根蒂、某种敲声的瓜”这样的概念。
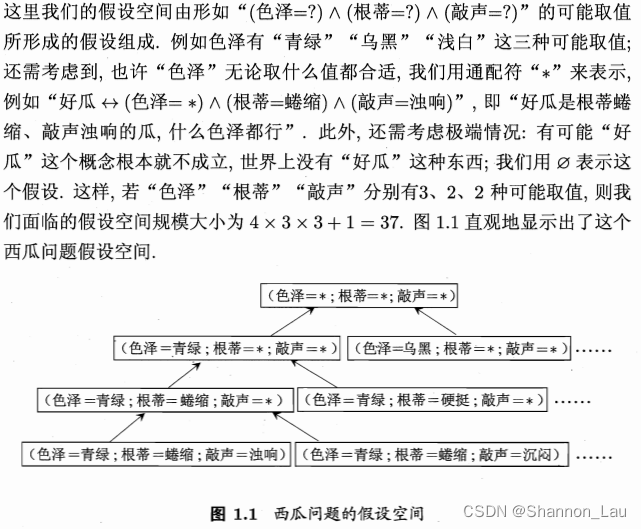
布尔表达式:“ 好 瓜 ↔ ( 色 泽 = ? ) ⋀ ( 根 蒂 = ? ) ⋀ ( 敲 声 = ? ) 好瓜\leftrightarrow (色泽=?)\bigwedge(根蒂=?)\bigwedge(敲声=?) 好瓜↔(色泽=?)⋀(根蒂=?)⋀(敲声=?)”
根据编号1, ( 色 泽 = 青 绿 ) ⋀ ( 根 蒂 = 蜷 缩 ) ⋀ ( 敲 声 = 浊 响 ) (色泽=青绿)\bigwedge(根蒂=蜷缩)\bigwedge(敲声=浊响) (色泽=青绿)⋀(根蒂=蜷缩)⋀(敲声=浊响)是好瓜。但这是见过的。
我们的目的是泛化:通过对训练集中的瓜学习以获得对没见过的瓜进行判断的能力。
仅仅将训练集中的瓜记住,就是所谓的“机械学习”。
学习可以看在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”(fit)的假设。
搜索的策略可以自顶向下、从一般到特殊等等,搜索过程中删除与正例不一致、和反例一致的假设,最后获得与训练集一致的假设。
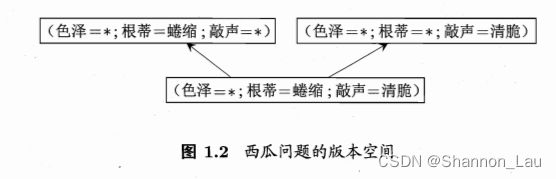
- 版本空间(version space):与训练集一致的“假设集合”
- 如图是与表1.1训练集对应的版本空间:















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









