








这些知识点以前大部分都知道,就简单记一下。
简单的验证 single validation(这个与以前的想法有些出入)
我们并不能完全依靠我们的
Ein
来评价模型的好坏,一因为仅仅靠
Ein
会很容易过拟合
所以,想法就是 留出一部分数据集作为test_data,以免他被污染。
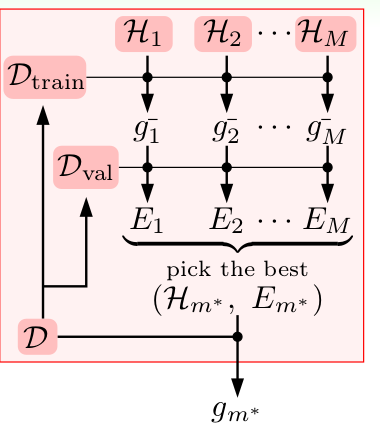
我们有很多的H,通过train_data 得到一系列的
g−
,然后用test_data得到
g−
对应的 E,选出最小E对应的
Hm∗
。
注意:是选出
Hm∗
,而不是
g−
。
然后,我们用总数据集D去训练
Hm∗
,再才得到最好的
gm∗
原因:
g−
与
gm∗
其实并不一定相等。因为,
gm∗
是通过总数据量D训练得到的,而
g−
是通过train_data得到的。那么普遍情况下,
gm∗
要比
g−
好。只有当test_data很小,train_data接近D时,才差不多。
一般情况下,我们的test_data选取总数据的20%.即N/5 .
交叉验证 cross validation
留一法
留一个作为test_data,其余都作为train_data.循环N次,再把N个error取平均.
该方法理论上很好,但是实际上,并不常用.一般再数据量很小的时候用.
缺点有:
1.可能计算量很大
2.稳定性不是很好,因为每次仅仅留一个点作为test_data
k-fold 交叉验证
一般K取10. 也有取5的.k越大,越精确.但是运算量大.
总结
- 交叉验证其实对结果还是有一些乐观成分.
- 只要计算量允许,就用10折交叉验证,10折效果一般比5折好.
- cross validation 比single validation(普通验证法) 好,只要计算量允许,一定要用cross validation















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









