









先po一段代码
String tmp=new String("abcd");
byte[] tmpBytes=tmp.getBytes();
String chineseStr=new String("a一二");
byte[] chiBytes=chineseStr.getBytes();//tmp variables
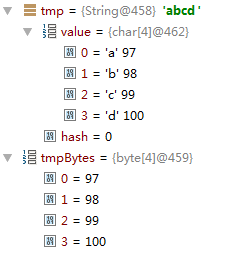
上图展示的是tmp的详细信息。以我们熟悉的ascii码来存储。此处不赘述。
//chineseStr variables
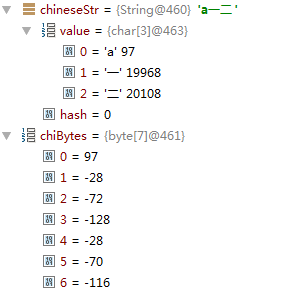
此处有若干问题:
- chineseStr内容有英文有中文,两者需要的存储空间是不同的,分别是多少
- value中的19968和20108分别来自哪儿
- 上一问题中的俩数字是怎么转换成chiBytes中数值的
现在一一来回答。
- 英文依旧用ascii码来存储,只需要一个byte就能存储,所以chiBytes[0]==97。而中文字符则需要三个bytes来存储。
- 我们可以在网上查找中文字符对应的unicode码。在工具类网站上查到,”一”对应的unicode码是 “\u4e00”,而0x4e00=19968。同样,“二”的unicode码是 “\u4e8c”,而0x4e8c=20108。所以第二个问题答案就是这些中文字符的unicode码。
- 根据此处提供的信息:通常汉字用 UTF-8 表示时是三个字节,格式为「1110XXXX 10XXXXXX 10XXXXXX」。0x4e00=0100111000000000b,将其插入空缺位得,11100100 10111000 10000000。所需的空间正好是3bytes,再每个byte内容以十进制表示,分别是-28 -72 -128。正对应chiBytes[1]、chiBytes[2]、chiBytes[3]。对0x4e8c做类似处理将获得同样结果。
Unicode和UTF-8的关系。一言以蔽之,Unicode是字符集,UTF-8是编码方式。
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx (文中出现的是此种方式)
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx















 2025
2025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









