




长尾分布下的分类问题
基于深度学习的分类算法应用于长尾分布数据集时,识别效果不好。对尾部类别的学习效果很差。为解决长尾分类下的识别问题,有多种不同思想的优化方法。最简单的方法是重采样(re-sampling)和重加权(re-weighting)。一些最新研究方法包括知识迁移和解耦特征和分类器。
重采样(re-sampling)
重采样的具体做法包括对头部类别样本的欠采样和对尾部类别样本的过采样。但过采样容易在尾部类别过拟合。
重采样一般会选择过采样的方式,欠采样会丢失过多的头部类别信息,导致欠拟合的发生。为避免丢失大量信息,可采用数据增强来增加样本的多样性。减少过拟合的风险。
重加权(re-weighting)
重采样的方式实际上调整了每个类别损失在总损失中的占比。缓解因为长尾分布导致的梯度占比失衡。有许多研究通过给loss中样本加权来调整总损失中各类别的梯度占比。
CEloss-weight
最简单的一种方法,在计算交叉熵损失时,为每个类别的样本加权。权重一般取逆类别频率。如正负样本为50:1。那么就将正负样本的权重设置为[1:50]。pytorch的CrossEntropyLoss实现中就提供了weight参数。
import torch.nn as nn
weights = torch.tensor([1, 50])
loss_fn = nn.CrossEntropyLoss(weight=weights)
Focal loss
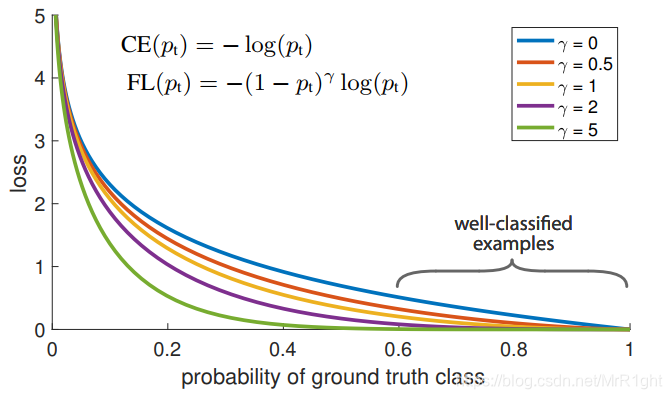
简单的loss加权可能会增加正类样本的误分概率。因为重加权后相当于缩小每个正样本在总损失中的占比。focal loss引入难易程度样本因子 ( 1 − p t ) β (1-p_t)^\beta (1−pt)β。用幂函数增加误差样本的权重。focal loss结合了逆类别频率因子 a t a_t at,和难易样本因子 ( 1 − p t ) β (1-p_t)^\beta (1−pt)β。在缩小正样本梯度占比的同时,增加误分样本的损失。
l
o
s
s
f
l
=
−
a
t
(
1
−
p
t
)
β
l
o
g
(
p
t
)
loss_{fl}=-a_t(1-p_t)^\beta log(p_t)
lossfl=−at(1−pt)βlog(pt)
focal loss在学习的后期,大多数样本的预测概率在0.99+。这些样本的难易程度因子为
(
1
−
p
t
)
2
=
1
e
−
4
(1-p_t)^2=1e-4
(1−pt)2=1e−4。这个因子足够的小,使得这些模型对拟合很好的样本产生的损失会非常的小。促使模型只关注于难分样本。所以叫focal loss。但这种方法也存在一定的问题。
focal loss实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class focal_loss(nn.Module):
def __init__(self, alpha=None, gamma=2.0, num_classes=2):
super(focal_loss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.num_classes = num_classes
def forward(self, y_pred, y_labels): # [B, C],
y_pred = torch.softmax(y_pred, dim=1)
class_mask = F.one_hot(y_labels, num_classes=self.num_classes) # [B, C]
pt = (y_pred * class_mask).sum(dim=1) # [B, ]
if self.alpha is None:
loss = -((1 - pt) ** self.gamma) * pt.log()
loss = loss.mean()
else:
alpha = self.alpha[y_labels]
loss = -alpha * ((1 - pt) ** self.gamma) * pt.log()
loss = loss.sum() / alpha.sum() # 求加权平均
return loss
原论文中, g a m m a gamma gamma的取值为2获得最优结果。但原论文是应用于目标检测中的。用于区分侯选框是前景还是背景。这个正负比值是极度不均衡的,所以论文中 g a m m a gamma gamma的取值较大。但在实际长尾任务中不均衡程度不会这么严重。在使用中,通常 g a m m a = 0.5 gamma=0.5 gamma=0.5能获得较好的结果。同时,发现focal loss的效果不稳定,时而优于/时而差于ce loss的优化结果。使用中还是要多尝试。
Gradient Harmonizing mechanism (GHM) [ 1 ] [ 2 ] \ ^{[1][2]} [1][2]
GHM指出,过多的关注难分样本也存在问题。如果样本中包含离群点(数据噪声),在模型已经收敛到一定程度后,这些离群点会仍然被误分。而focal loss强制模型去关注这些离群点。会导致模型越来越差。GHM提出正是为了改进这个问题。
focal loss中定义了 p t p_t pt来衡量样本的难易程度,使用幂函数 ( 1 − p t ) β (1-p_t)^\beta (1−pt)β减少易分样本的梯度。让模型关注与难分样本。GHM认为不仅要忽略易分样本,也要忽略离群点。又将 p t p_t pt进一步细分为难分样本和疑似离群点。具体做法是,作者认为 p t p_t pt满足以下分布:
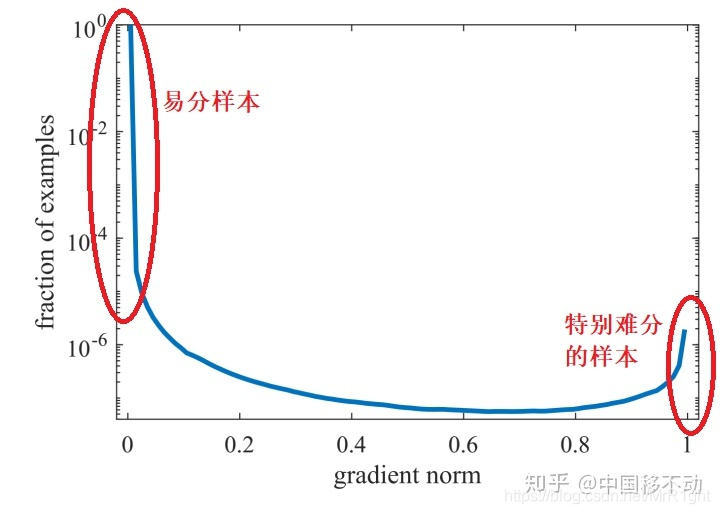
这里的gradient norm等价于focal loss论文汇总的
p
t
p_t
pt。作者认为既不应该关注易分样本,也不应该过多关注特征难分样本。上图分布可以看出,易分和特征难分样本数据都比较多。通过对
p
t
p_t
pt进行分桶。统计每个桶样本个数(思想和数据挖掘中连续特征离散化的分桶思想差不多)。对样本数较多的进行衰减。为和原文公式保持一致,下文
p
t
pt
pt用
g
g
g表示。GHM公式如下:
L
G
H
M
−
C
=
∑
i
=
1
N
L
C
E
(
l
o
g
i
t
,
l
a
b
e
l
)
G
D
(
g
i
)
L_{GHM-C}=\sum_{i=1}^N\frac{L_{CE}(logit,label)}{GD(g_i)}
LGHM−C=i=1∑NGD(gi)LCE(logit,label)
G
D
(
g
i
)
GD(g_i)
GD(gi)表示单位梯度模长g部分的样本个数。(落在当前桶中的样本个数)。公式:
G
D
(
g
)
=
1
l
ε
(
g
)
∑
i
=
1
N
δ
ε
(
g
i
,
g
)
GD(g)=\frac{1}{l_\varepsilon (g)}\sum_{i=1}^N\delta_\varepsilon(g_i,g)
GD(g)=lε(g)1i=1∑Nδε(gi,g)
∑
k
=
1
N
δ
ε
(
g
k
,
g
)
\sum_{k=1}^N\delta_\varepsilon(g_k,g)
∑k=1Nδε(gk,g)表明样本1~N中,梯度模长在
(
g
−
ε
2
,
g
+
ε
2
)
(g-\frac{\varepsilon}{2},g+\frac{\varepsilon}{2})
(g−2ε,g+2ε)区间的样本个数。
l
ε
(
g
)
l_\varepsilon (g)
lε(g)表示区间
(
g
−
ε
2
,
g
+
ε
2
)
(g-\frac{\varepsilon}{2},g+\frac{\varepsilon}{2})
(g−2ε,g+2ε)的长度。
知识迁移
将模型学到的头部类别特征知识迁移到尾部类别。通常需要将复杂的设计。暂未学习。可参考 [ 3 ] [ 4 ] [ 5 ] \ ^{[3][4][5]} [3][4][5]
特征和分类解耦
特征和分类解耦的方法在长尾数据集上取得了SOTA的成绩。研究发现将特征学习和分类解耦,把长尾分布下的学习分为两个阶段。在特征学习阶段采用样本均衡采样,在分类器学习时,冻结其它层参数,采用类均衡采样。可以获得更好的结果。如Decoupling [ 6 ] \ ^{[6]} [6]和BBN [ 7 ] \ ^{[7]} [7]方法。
实验结果
使用data fountain的O2O商铺食品安全相关评论发现竞赛数据测试CE,CE with weight,focal loss, seesaw loss。数据包含两类非负面和负面。数据占比大约10:1。使用五折交叉验证,保持其他超参一致。实验结果如下:
| loss function | fold 1 | fold 2 | fold 3 | fold 4 | fold 5 | mean |
|---|---|---|---|---|---|---|
| crossentropy | 0.907 | 0.916 | 0.902 | 0.913 | 0.897 | 0.907 |
| crossentropy(weight) | 0.899 | 0.917 | 0.905 | 0.888 | 0.906 | 0.903 |
| focal loss | 0.929 | 0.913 | 0.886 | 0.890 | 0.916 | 0.907 |
| seesaw loss | 0.904 | 0.898 | 0.89 | 0.919 | 0.856 | 0.8957 |
分布图如下:
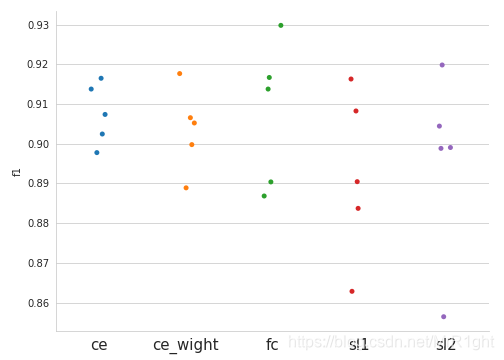
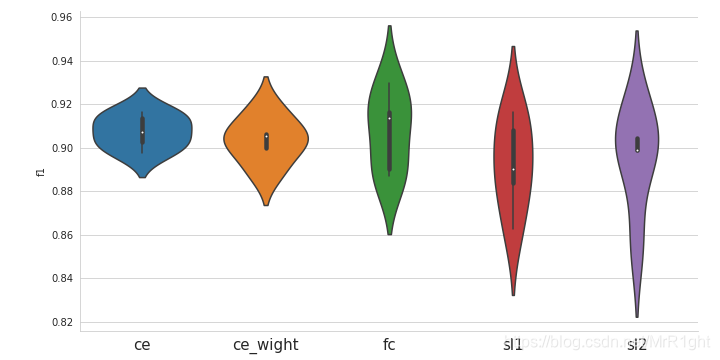
可以看出,最高的结果来自于focal loss。但同时,focal loss的五折结果方差最大。也就说明了focal loss结果不稳定。可能需要多次参数调整才能得到相对于crossentropy更好的结果。
参考:
[1] 5分钟理解Focal Loss与GHM——解决样本不平衡利器
[2] Gradient Harmonized Single-Stage Detector
[3] Deep Representation Learning on Long-tailed Data: A Learnable Embedding Augmentation Perspective
[4] Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification
[5] Large-Scale Long-Tailed Recognition in an Open World
[6] Decoupling Representation and Classifier for Long-Tailed Recognition
[7] BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









