






ElasticSearch+Mongo-connector环境搭建(亲测成功!!)
Linux安装ElasticSearch
(76条消息) linux系统elasticsearch的详细安装配置教程(超级详细)_linux安装elasticsearch_lunaw-的博客-CSDN博客,链接2
1.官网下载linux安装包
Download Elasticsearch | Elastic,我用的是7.8.0
传到服务器上,并解压到指定目录,我用的是tar -zxvf japan.tar.gz -C /elasticsearch/
结果为:


2.修改elasticsearch.yml文件,修改一些核心配置:


修改结果为:(只有这三个不是注释)
注意
此处没有修改数据和日志目录,默认把数据和日志记录放在elasticsearch根目录下,
也没有改端口号,可以看到默认为9200端口
也没有设置ES密码


3.解决es与jdk依赖强的问题:
解决方法:修改bin/elastisearch文件,将java的启动jdk换为elasticsearch安装时自动安装的jdk,而不用服务器内部的jdk
先到bin目录下:
cd elasticsearch/elasticsearch-7.8.0/bin
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wf9aeb3o-1681815784198)(E:\TyporaBiJi\安装环境.assets\image-20230417145001151.png)]](https://i-blog.csdnimg.cn/blog_migrate/2b4b599eff4e2ff5b85028da90622144.png)
修改:vim ./elasticsearch
进去之后选择要插入的位置,先按i,即进入插入模式,然后就可以用鼠标右键粘贴了,也可以修改,注意右边的小键盘输入数字有问题,需要用键盘上面输入数字
在最上面添加:(注意一定在最上面,我之前放在下面某位置,不起作用)
############## 添加配置解决jdk版本问题 ##############
# 将jdk修改为es中自带jdk的配置目录
export JAVA_HOME=/elasticsearch/elasticsearch-7.8.0/jdk
export PATH=$JAVA_HOME/bin:$PATH
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/elasticsearch/elasticsearch-7.8.0/jdk/bin/java"
else
JAVA=`which java`
fi
source "`dirname "$0"`"/elasticsearch-env
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BhFx9uYU-1681815784199)(E:\TyporaBiJi\安装环境.assets\image-20230417152601791.png)]](https://i-blog.csdnimg.cn/blog_migrate/0fa3467af1cc8fb3f0c35ff8e574744b.png)
然后按Esc,退出编辑
然后按:wq,保存并退出 或者按:q!:不保存并退出
4.解决内存不足问题
由于elasticsearch 默认分配 jvm空间大小为2g,如果服务器内存不大就会报错,所以我们需要修改 jvm空间,如果Linux服务器本来配置就很高,可以不用修改。
解决方法:修改配置文件:
进入config目录,修改jvm.options文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FxrYMGbL-1681815784200)(E:\TyporaBiJi\安装环境.assets\image-20230417145947397.png)]](https://i-blog.csdnimg.cn/blog_migrate/0488dd981f4520b46c51b26e59f0101c.png)
将原来的2g,改为256m(只需要改这一个位置)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OllHy2D9-1681815784200)(E:\TyporaBiJi\安装环境.assets\image-20230417150054462.png)]](https://i-blog.csdnimg.cn/blog_migrate/bc6ca4cbce0d666220e6a83b631bad70.png)
5.创建专用用户启动ES
root用户不能直接启动Elasticsearch,所以需要创建一个专用用户,来启动ES(添加一定条件后也可以运行,但是有的博客说后面会有各种问题,不如直接创建用户,很简单)
创建用户:useradd user-es
赋予权限:chown user-es:user-es -R /elasticsearch/elasticsearch-7.8.0
需要启动ES时
先进入Elasticsearch的bin目录,cd elasticsearch/elasticsearch-7.8.0/bin
切换到user-es用户:su user-es
运行:./elasticsearch
(之后再切换到root用户时需要输入root的密码,即服务器实例的密码)
6.此时启动后遇到vm.max_map_count [65530] is too low问题
ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
elasticsearch用户拥有的内存权限太小,至少需要262144,解决办法:
在 /etc/sysctl.conf 文件最后添加如下内容,即可永久修改
切换到root用户,执行命令:su root
执行命令,vim /etc/sysctl.conf
添加如下内容,vm.max_map_count=262144
保存退出,刷新配置文件,sysctl -p
切换user-es用户,继续启动,su user-es
启动es服务,elasticsearch/elasticsearch-7.8.0/bin/elasticsearch &
启动成功后,可以通过http://127.0.0.1:9200/访问,如果出现以下内容,说明ES安装成功:
7.可能遇到的max file descriptors [4096]问题(我没遇到)
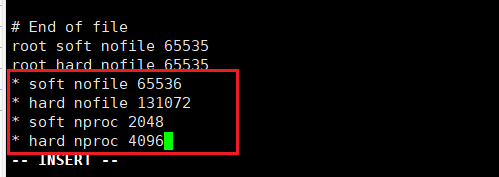
vim /etc/security/limits.conf
添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
8.查看ES进程
查看ES进程:ps -ef|grep ela
需要关闭或重启时,则杀死该进程,然后再启动即可
9.开启端口访问权限
由于我的ES是用作同步MongoDB数据库后,使用ES的模糊查询功能,因此需要从别处访问ES的数据(使用mongo-connector同步数据时需要访问),因此需要开启9200端口的访问权限
(阿里云服务器的安全组规则处添加即可)
10.使用DBeaver Ultimate连接ES数据库
不需要写账号密码,只需要写主机号和端口号

遇到问题:current license is non-compliant for [jdbc]
[(76条消息) current license is non-compliant for jdbc]_数据库人生的博客-CSDN博客
原因:开源版ES的license不允许使用这种连接方式
修改为30天试用版
在服务器查看es的license信息,发现 “type” : “basic”:curl -XGET http://localhost:9200/_license
修改为30天试用版:curl -X POST "localhost:9200/_license/start_trial?acknowledge=true&pretty"
再次查看:发现"type" : “trial”
再次测试连接即可用了
11.安装ik分词器
ik分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik
(76条消息) Linux 安装Elasticsearch和配置ik分词器步骤_es7.8.1安装ik_beyondLi71的博客-CSDN博客
首先,下载.zip类型的安装包,我用.tgz结尾的安装包,过程中出现问题,注意版本要和ES一样,我用的7.8.0
下载完后,我们将ik分词器上传到我们的es的plugins/ik目录下,ik文件夹需要我们自己创建
#切换到ik文件夹下进行文件上传
cd ik
#没有unzip命令的同学输入如下命令安装unzip命令
yum install -y unzip
#对zip进行解压
unzip elasticsearch-analysis-ik-1.10.0.zip
重启es,我们会发现启动时的信息多了一个关于ik的信息,如图所示

之后在浏览器中查看我们之前试过的’五常大米’
http://你的ip:9200/shop/_analyze?pretty&analyzer=ik_max_word&text=五常大米
结果如图所示(我们这次的urlanalyzer换为了ik_max_word,这是在指定我们刚装好的新的分词器)
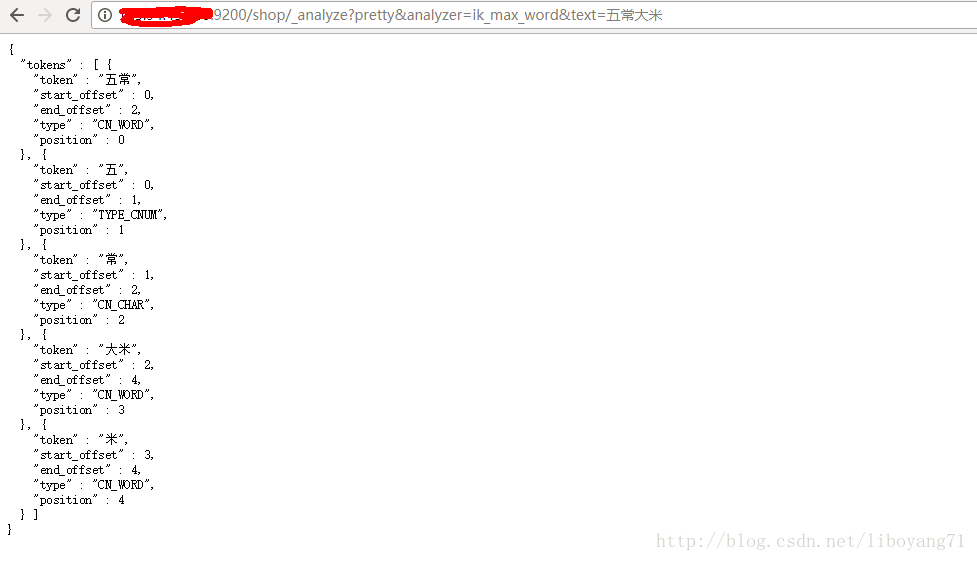
好了,分词器达到了我们预期的效果。ik分词器我们也算是安装成功了。
注意,此处没有设置ik分词器为默认分词器,但是用的时候可以指定分词器为ik了
使用mongo-connector完成同步
背景:
服务器上已经运行了mongodb数据库,现在想要使用mongo-connector完成将mongodb数据库的数据同步到ES上
1.安装python3和python包
安装mongo-connector时需要py3,
由于服务器使用了宝塔面板,可以直接安装python3环境
在这里即可安装
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UB6Q4GFf-1681815784201)(E:\TyporaBiJi\安装环境.assets\image-20230417161107881.png)]](https://i-blog.csdnimg.cn/blog_migrate/38065d4abfdbdeb127ef892c7759e6e6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t5xPdtiU-1681815784201)(E:\TyporaBiJi\安装环境.assets\image-20230417161133103.png)]](https://i-blog.csdnimg.cn/blog_migrate/c2493d94f67895382660dfb306c9e0d8.png)
然后随便创建一个项目,里面是空的就行,因为这里的项目管理器是一个项目使用一个环境,每个项目都有一个环境,因此使用Pip安装的包只会安装到那个环境
然后使用source www/wave_py/wave_venv/bin/activate进入到特定的环境下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JQl5VE4p-1681815784202)(E:\TyporaBiJi\安装环境.assets\image-20230417161547271.png)]](https://i-blog.csdnimg.cn/blog_migrate/8d6170c78cc9bfb6abb5c66d1c65c611.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5LE5v6tg-1681815784202)(E:\TyporaBiJi\安装环境.assets\image-20230417161639020.png)]](https://i-blog.csdnimg.cn/blog_migrate/e34a559bbfc9445dfa0dbd56401aaf8c.png)
然后可以安装python包

我安装的是pymongo3.9(之前用的是4.多),出现了问题


2.创建mongodb集群
单机Linux下搭建MongoDB副本集-三节点 - harlan_op - 博客园 (cnblogs.com)
从步骤二开始(我使用的是27018,27019,27020端口,其中27020是主节点)
注意:
开放这三个端口
使用Keyfile文件,(这是在上面链接基础上附加的操作,在创建完文件后进行,然后再初始化之类的)即先使用准备作为主节点的目录中生成keyFile文件,然后再在这三个的文件中写上keyFile的路径
mongodb复制集开启安全认证 - panchanggui - 博客园 (cnblogs.com)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T7lEt2y2-1681815784202)(E:\TyporaBiJi\安装环境.assets\image-20230417165239212.png)]](https://i-blog.csdnimg.cn/blog_migrate/44c03389c253ddaa2fe3fc76ca2f54d2.png)
3.同步
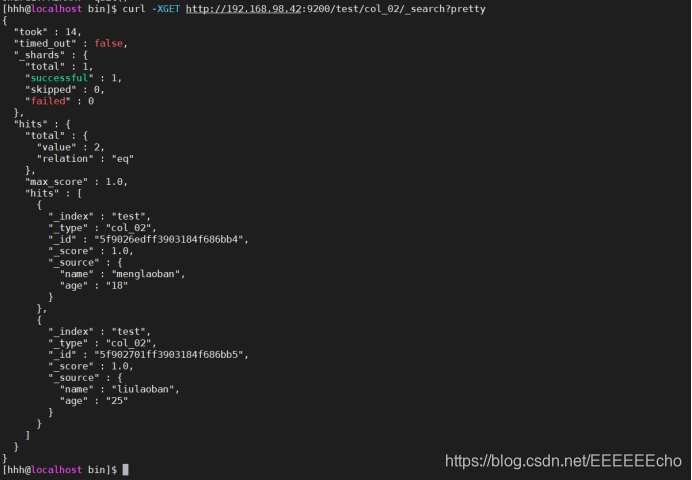
在终端,先运行mongodb数据库,然后mongo --port=27020,然后可以执行mongodb数据库的语句
创建一个新的数据库:use test
插入数据:db.col_02.insert({name:"xiaoming",age:"18"});
然后查看es中的同步情况,使用curl -i localhost:9200,或者远程访问主机号:9200(因为前面已经开启了9200端口)
显示这种即为同步成功
同步时注意:
-
由于mongodb数据库
_id字段是自动生成的,并且mongo-connector会自动添加所有表的_id字段,因此会重复,并且mongo-connector在同步时会将该数据库的所有表数据合到一起作为ES中的一个索引,并且每个表的记录到ES后,ES中的type即为表名称,且ES中不同type的字段名不能相同,否则在插入数据时会无法插入,比如user表和posting表都有
_id属性,则如果首次添加,是给user表添加了一条数据,则之后无法给posting表添加数据,因为posting的原数据中也有_id字段,此时可以删除该索引,然后先给posting表添加数据,则之后添加数据时,无法给user表添加但是可以给posting表添加,则满足需求了 -
由于只需要同步posting数据库,故可以只选择该数据库,但是该方法无法排除user表的
_id和其他表属性,因此// 先到python的环境目录下,即 source www/wave_py/wave_venv/bin/activate nohup mongo-connector -n 'wavemongo.posting' -m localhost:27020 -t http://8.130.99.183:9200 -d elastic2_doc_manager & // 使用nohup ... & 代表作为守护进程,关闭这个会话也不会关闭这个进程 // -n 'wavemongo.posting'代表只包含数据库wavemongo.posting -
nohup mongo-connector -n 'wavemongo.posting' -m localhost:27020 -t http://8.130.99.183:9200 -d elastic2_doc_manager & // 使用nohup ... & 代表作为守护进程,关闭这个会话也不会关闭这个进程 // -n 'wavemongo.posting'代表只包含数据库wavemongo.posting















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









