







字典(dict)和集合(set)是两个很常见的数据结构,并且相比列表(list)和元组(tuple),性能进行了高度优化,在 Python 中被广泛使用,其重要性不言而喻。
字典和集合的定义
字典(dict)是一系列由键(key)和值(value)配对组成的元素的集合,在 Python3.7+中,字典被确定为有序的(注:Python3.6 之前是无序的,而在 Python3.6 中字典有序是一个 implementation detail,无法 100% 确保其有序性;直到 3.7 中才正式成为语言特性,这里的有序性是指数据取出字典的顺序和存进字典时的顺序一致)。字典的长度大小可变,元素可以任意地删减和改变。相比于列表和元组,字典的性能更优,特别是对于查找、添加和删除操作,字典都能在常数时间复杂度内完成。
而集合(set)和字典(dict)基本相同,唯一的区别是:集合没有键和值的配对,是一系列无序的、唯一(集合中元素不重复)的元素组合。
常见操作
1.首先我们来看字典和集合的创建,通常有下面这几种方式:
# 创建字典
d1 = {'name': 'jason', 'age': 20, 'gender': 'male'} # 直接{}的方式更高效
d2 = dict({'name': 'jason', 'age': 20, 'gender': 'male'}) # 需要函数调用,消耗了更多的时间
d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')])
d4 = dict(name='jason', age=20, gender='male')
d1 == d2 == d3 ==d4
True
# dict.fromkeys(iterable, value)可以生成一个value相同的字典
d5 = dict.fromkeys(['aa','bb','cc'],666)
d5
{'aa': 666, 'bb': 666, 'cc': 666}
# 创建集合
s1 = {1, 2, 3}
s2 = set([1, 2, 3])
s1 == s2
True
此外,Python 中字典和集合,无论是键还是值,都可以是混合类型。
d = {1: 'a','b': 2, 3: 3.0}
d
{1: 'a', 'b': 2, 3: 3.0}
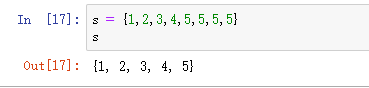
s = {1, 5.0, 'a'}
s
{1, 5.0, 'a'}
不过,要注意的是,用列表作为字典的 key 在是不被允许的,因为列表是一个动态变化的数据结构,而字典当中的 key 要求是不可变的,原因也很好理解,如果 key 是可以变化的话,那么随着 key 的变化,这里就有可能就会出现重复的 key,那么这就和字典的定义相违背,key 和 value 无法一一对应了;但如果把这里的列表换成元组是可以的,因为元组不可变。
2.再来看元素访问的问题。
字典访问可以直接通过键索引值,如果键不存在,就会抛出异常;也可以使用 get(key, default) 函数来进行索引,如果键不存在,调用 get() 函数可以返回一个用户预设的默认值。比如下面这个示例中返回了 ‘null’;还可以使用 setdefault(key, default) 进行索引,与 get() 函数不同,setdefault()函数在索引一个不存在的键的值时,返回预设的默认键的值后,会将新的键值保存在字典中。
# 直接索引键
d = {'name': 'jason', 'age': 20}
d['name']
'jason'
d['location']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-29-46d978634ca1> in <module>
----> 1 d['location']
KeyError: 'location'
# 调用 get() 函数
d = {'name': 'jason', 'age': 20}
d.get('name')
'jason'
d.get('location', 'null')
'null'
d
{'name': 'jason', 'age': 20}
# 调用 setdefault() 函数
d = {'name': 'jason', 'age': 20}
d.setdefault('name')
'jason'
d.setdefault('location','null')
'null'
d
{'name': 'jason', 'age': 20, 'location': 'null'}
而对于集合,要注意的是,集合并不支持索引操作,因为集合本质上是一个哈希表,和列表不一样。
s = {1, 2, 3}
s[0]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-34-5cdbfc2bec29> in <module>
1 s = {1, 2, 3}
----> 2 s[0]
TypeError: 'set' object is not subscriptable
3.想要判断一个元素在不在集合或字典中,可以用 value in dict/set 来判断。不过要注意的是,对于字典,只能判断 key,不能判断 value。
s = {1, 2, 3}
1 in s
True
10 in s
False
d = {'name': 'jason', 'age': 20}
'name' in d
True
'location' in d
False
4.增加、删除、更新操作
d = {'name': 'jason', 'age': 20}
d['gender'] = 'male' # 增加元素对'gender': 'male'
d['dob'] = '1999-02-01' # 增加元素对'dob': '1999-02-01'
d
{'name': 'jason', 'age': 20, 'gender': 'male', 'dob': '1999-02-01'}
d['dob'] = '1998-01-01' # 更新键'dob'对应的值
d.pop('dob') # 删除键为'dob'的元素对
'1998-01-01'
d
{'name': 'jason', 'age': 20, 'gender': 'male'}
s = {1, 2, 3}
s.add(4) # 增加元素4到集合
s
{1, 2, 3, 4}
s.remove(4) # 从集合中删除元素4
s
{1, 2, 3}
注意,集合的 pop() 操作是删除集合中最后一个元素,但集合本身是无序的,无法知道会删除哪个元素,因此这个操作得谨慎使用。
5.对字典或集合进行排序
对于字典,我们通常会根据键或值,进行升序或降序排序:
d = {'b': 1, 'a': 2, 'c': 10}
# 利用匿名函数传参进行排序
d_sorted_by_key = sorted(d.items(), key=lambda x: x[0]) # 根据字典键升序排序
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1]) # 根据字典值升序排序
d_sorted_by_key # sorted()返回了一个列表,列表中的每个元素,是由原字典的键和值组成的元组
[('a', 2), ('b', 1), ('c', 10)]
d_sorted_by_value
[('b', 1), ('a', 2), ('c', 10)]
# 使用operator.itemgetter函数
import operator
d_sorted_by_key = sorted(d.items(), key = operator.itemgetter(0))
d_sorted_by_value = sorted(d.items(), key= operator.itemgetter(1))
d_sorted_by_key
[('a', 2), ('b', 1), ('c', 10)]
d_sorted_by_value
[('b', 1), ('a', 2), ('c', 10)]
而对于集合,其排序和列表、元组类似,直接调用 sorted(set) 即可,结果会返回一个排好序的列表。
s = {3, 4, 2, 1}
sorted(s) # 对集合的元素进行升序排序
[1, 2, 3, 4]
字典和集合的工作原理
不同于其他数据结构,字典和集合的内部结构都是一张哈希表,所以更加高效,特别是对于查找、添加和删除操作。
- 对于字典而言,这张表存储了哈希值(hash)、键和值这 3 个元素。
- 对集合来说,区别就是哈希表内没有键和值的配对,即只存储了哈希值(hash)和元素值。
1.插入操作
每次向字典或集合中插入一个元素时,Python 会首先根据哈希值,计算这个元素应该插入哈希表的位置,如果哈希表中此位置是空的,那么这个元素就会被插入其中。而如果此位置已被占用,Python 便会比较两个元素的哈希值和键(对于集合则是比较哈希值和单一元素的值)是否相等。
(1)若两者都相等,则表明这个元素已经存在。对于字典,如果值不同,则更新值。
(2)若两者中有一个不相等,这种情况通常是发生哈希冲突(hash collision),意思是两个元素的键不相等,但是哈希值相等。这种情况下,Python 便会继续寻找表中空余的位置,直到找到位置为止。
不难理解,哈希冲突的发生,往往会降低字典和集合操作的速度。因此,为了保证其高效性,字典和集合内的哈希表,通常会保证其至少留有 1/3 的剩余空间。随着元素的不停插入,当剩余空间小于 1/3 时,Python 会重新获取更大的内存空间,扩充哈希表。不过,这种情况下,表内所有的元素位置都会被重新排放。虽然哈希冲突和哈希表大小的调整,都会导致速度减缓,但是这种情况发生的次数极少。所以,平均情况下,这仍能保证插入、查找和删除的时间复杂度为 O(1)。
2.查找操作
和前面的插入操作类似,Python 会根据哈希值,找到其应该处于的位置;然后,比较哈希表这个位置中元素的哈希值和键,与需要查找的元素是否相等。如果相等,则直接返回;如果不等,则继续查找,直到找到空位或者抛出异常为止。
3.删除操作
Python 会暂时对这个位置的元素,赋于一个特殊的值,等到重新调整哈希表的大小时,再将其删除。
使用场景
字典和集合由于内部的哈希表存储结构,保证了其查找、插入、删除操作的高效性。所以,字典和集合通常运用在对元素的高效查找、去重等场景。
举个例子,假设某电商企业的后台,存储了每件产品的 ID、名称和价格。现在的需求是,给定某件商品的 ID,我们要找出其价格。如果我们用列表来存储这些数据结构,并进行查找,相应的代码如下:
def find_product_price(products, product_id):
for id, price in products:
if id == product_id:
return price
return None
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150)
]
print('The price of product 432314553 is {}'.format(find_product_price(products, 432314553)))
# 输出
The price of product 432314553 is 30
假设列表有 n 个元素,而查找的过程要遍历列表,那么时间复杂度就为 O(n)。即使我们先对列表进行排序,然后使用二分查找,也需要 O(logn) 的时间复杂度,更何况,对列表进行排序还需要 O(nlogn) 的时间。
但如果我们用字典来存储这些数据,那么查找就会非常便捷高效,只需 O(1) 的时间复杂度就可以完成。原因也很简单,刚刚提到过的,字典的内部组成是一张哈希表,可以直接通过键的哈希值,找到其对应的值。
products = {
143121312: 100,
432314553: 30,
32421912367: 150
}
print('The price of product 432314553 is {}'.format(products[432314553]))
# 输出
The price of product 432314553 is 30
我们再来看,如果现在需求变成,要找出这些商品有多少种不同的价格。如果还是选择使用列表,那么,在最差情况下,A和B都要执行 n 次,需要 O(n2) 的时间复杂度。
# list version
def find_unique_price_using_list(products):
unique_price_list = []
for _, price in products: # A
if price not in unique_price_list: # B
unique_price_list.append(price)
return len(unique_price_list)
# 语句 “if x in list” 虽然表面上是条件语句,但是内部其实是循环,因为判断一个元素在不在列表里,必须得遍历一遍,时间复杂度是O(n)
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_list(products)))
# 输出
number of unique price is: 3
但如果我们选择使用集合这个数据结构,由于集合是高度优化的哈希表,其添加和查找某个元素只需 O(1) 的复杂度,并且里面的元素不能重复,那么,总的时间复杂度就只有 O(n)。
# set version
def find_unique_price_using_set(products):
unique_price_set = set()
for _, price in products:
unique_price_set.add(price)
return len(unique_price_set)
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_set(products)))
# 输出
number of unique price is: 3
参考
《Python核心技术与实战》
Python3.6 引入字典有序性,Python3.7后字典有序性已经可以依赖了:https://stackoverflow.com/questions/39980323/are-dictionaries-ordered-in-python-3-6















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









