







前言
由于pytesseract提取图片的准确度太低,不足以提取代码以进行后续的检查,所以要提高图片识别的准确度。
一、图片二值化处理
对一个图片进行处理,使其更加容易被识别。
处理过程中发现生成的文件很小,没有什么内容,说明识别的过程出了问题。
后来使用cv2.threshold函数处理,可以把一个图片相对清楚地显示出来,但是要使不同的图片显示地更加清晰,要对应不同的阈值;
发现阈值的确定和图片的底色有关系。
对图片进行灰度处理,效果有提升但不明显:
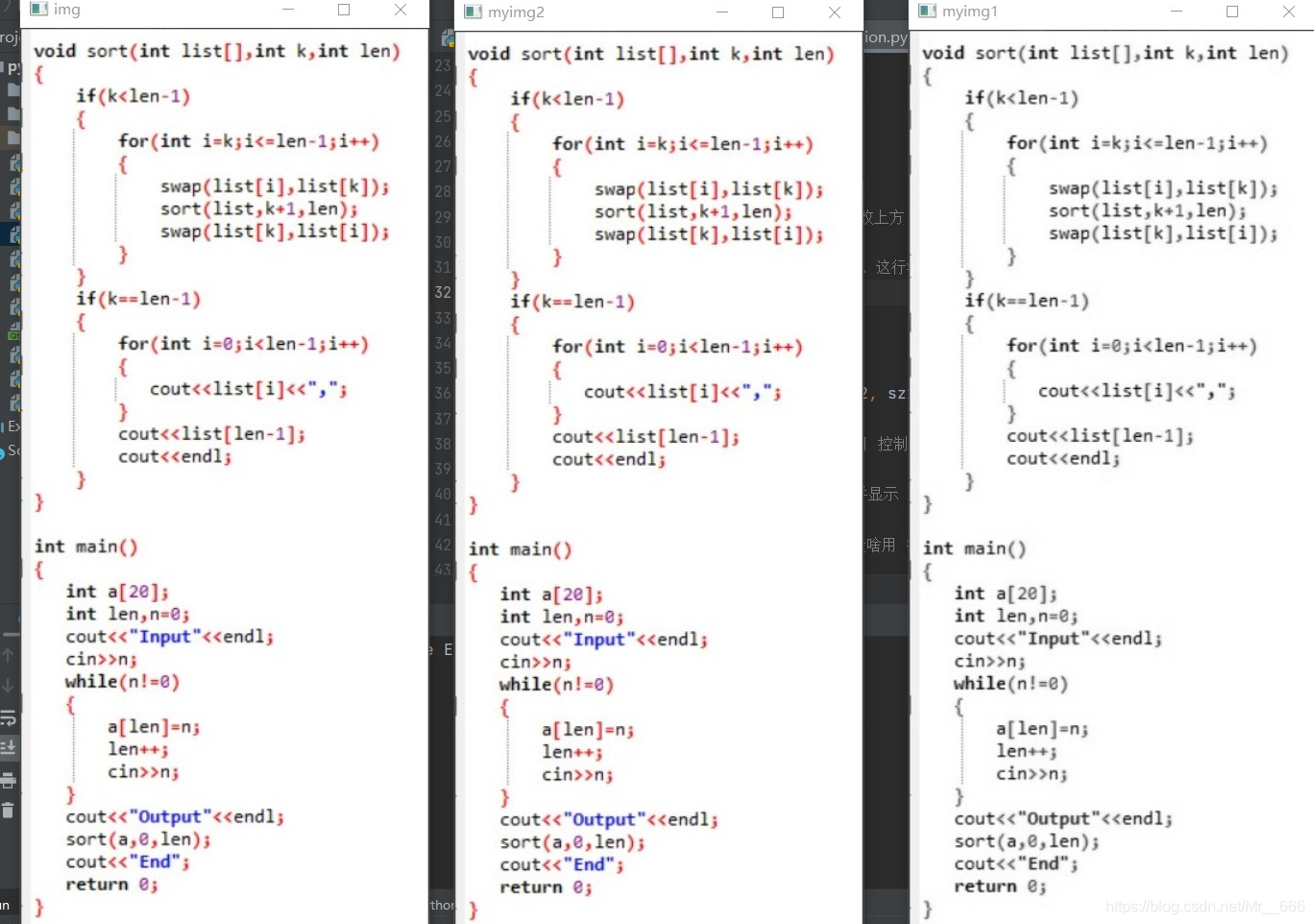
二、样本训练
即丰富tesseract的语言库,使其更加熟悉我所要提取的内容(代码),进而提高识别的准确度。
需要下载jTessBoxEditor。
使用jTessBoxEditor.exe,选择样本图片,生成tif文件;
用管理员模式打开命令行输入指令:
tesseract.exe a.tif b batch.nochop makebox
a.tif为刚才生成的tif文件,生成文件b.box;
再用jTessBoxEditor.exe打开box文件进行调试:
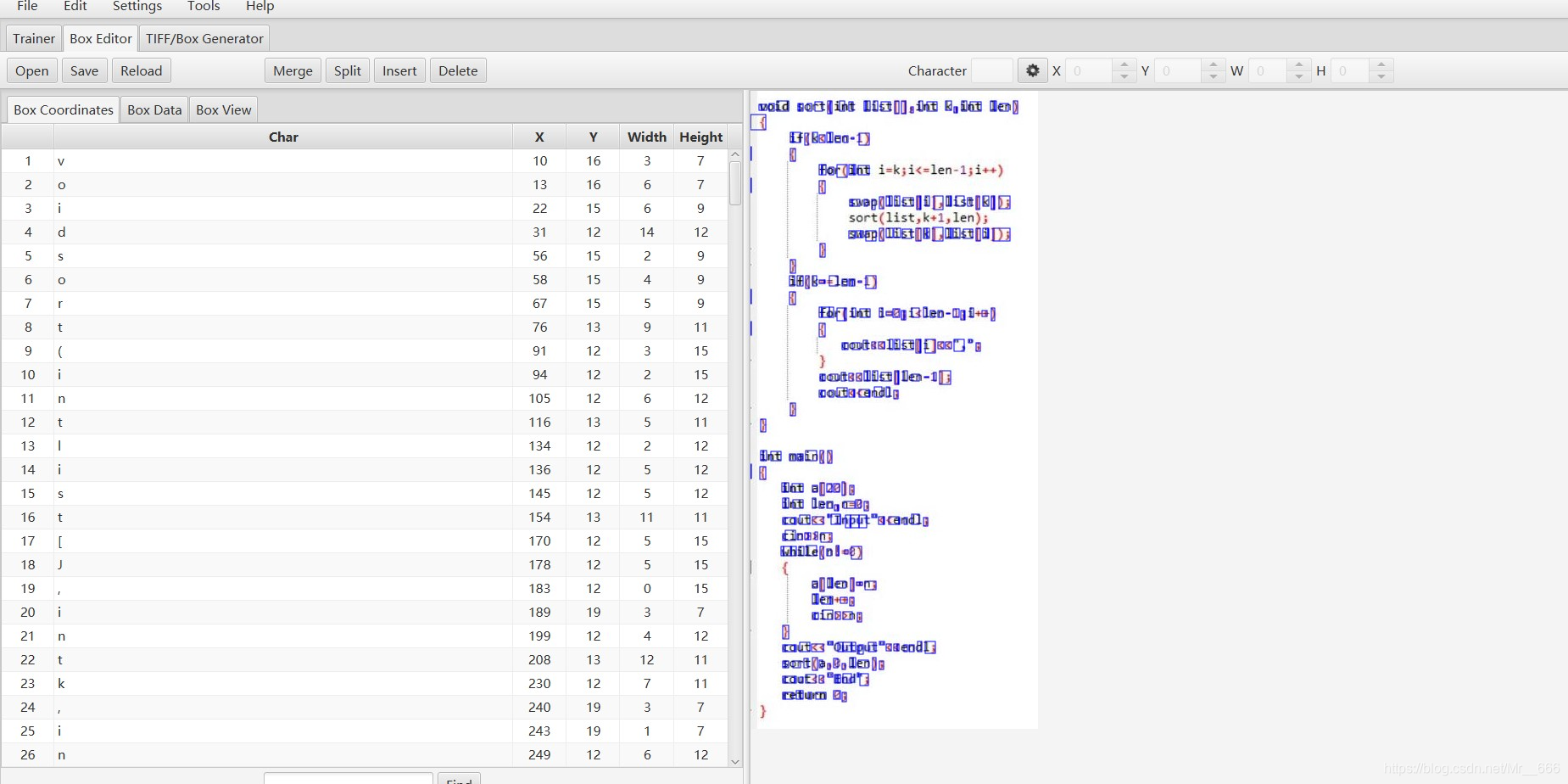
需要手动调整每一个字符,过程十分繁琐;
修改完后保存tif文件;
创建字体特征文件;
再创建批处理文件,进而形成语言文件;
然而,执行批处理文件的过程中发生了错误;
这样处理下来效率很低。
总结
通过样本训练提高pytesseract识别准确率很麻烦,而且可能不太适合本项目,因为同学们提交上来的代码截图会有很多除代码内容以外的格式差别,很难在一个通用的水平下训练文字库提高识别度。

















 3564
3564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









