






案例引入:
实验任务:

代码实现:
注意:我以项目的形式编写此代码,编译环境为VS2022,代码移植可能会导致错误
mystring.h:存放结构体以及函数声明
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#include<string.h>
#define MAXSIZE 1024
typedef struct string
{
char str[MAXSIZE];
int curSize;
}string;
//给定一个字符串,创建一个顺序表
string* createString(const char* str);
//遍历串
void traverseString(string* pstr);
//在给定串中插入,
void insertString(string* pstr, char* str, int pos);
//区间删除
void deleteString(string* pstr, int start, int end);
//是否为空
bool isEmpty(string* pstr);
//当前个数
int lenString(string* pstr);
//匹配算法
int bfString(string* mainStr, string* subStr);
void nextArray(string* pstr, int* next);
int kmpString(string* mainStr, string* subStr);
//病毒检测实现
void virusDetection(void);
void getCirculation(string* pstr);mystring.c:书写相关的代码实现
#include "mystring.h"
//给定一个字符串,创建一个顺序表
string* createString(const char* str)
{
//创建内存
string* pstr = (string*)calloc(1, sizeof(string));
assert(pstr);
//初始化
int count = 0;
//拷贝字符串
while (str[count]!= '\0')
{
pstr->str[count] = str[count];
count++;
}
//最后的\0
pstr->str[count] = str[count];
//记录长度
pstr->curSize = count;
return pstr;
}
//遍历串
void traverseString(string* pstr)
{
for (int i = 0; i < pstr->curSize; i++)
{
printf("%c", pstr->str[i]);
}
printf("\n");
}
//在给定串中的指定位置插入,这里的位置是数组的下标
void insertString(string* pstr, const char* str, int pos)
{
int len = strlen(str);
//判断序号的有效性
if (pos > MAXSIZE || pos < 0)
{
printf("无效位置\n");
return;
}
//判断是否溢出
if (len + pstr->curSize > MAXSIZE)
{
printf("数据溢出,无法插入\n");
return;
}
//如果插入位置在字符串 \0的后面
//那么选择直接将该字符串与原串相连接
if (pos > pstr->curSize)
{
for (int i = 0; i < len; i++)
{
pstr->str[pstr->curSize++] = str[i];
}
}
//一般情况:pos在串的内部
else
{
//将pos之后的串向后挪len个位置
for (int i = pstr->curSize; i >= pos; i--)
{
//这里画图理解
pstr->str[len + i] = pstr->str[i];
}
//插入新的元素
for (int i = 0; i < len; i++)
{
pstr->str[pos + i] = str[i];
pstr->curSize++;
}
}
}
//区间的删除,给出区间(数组下标)
void deleteString(string* pstr, int start, int end)
{
if (pstr->curSize == 0)
{
printf("空字符串\n");
return;
}
//注:这里对于区间的合法性判断可以找反面
//区间的合法性初步判断
if (start > MAXSIZE || end > MAXSIZE || start < 0 || end < 0)
{
printf("无效区间\n");
return;
}
//区间合法性再次判断
if (start > pstr->curSize)
{
printf("无效区间\n");
return;
}
//如果右区间超过字符串长度,那么将其赋值为字符串长度-1
if (end > pstr->curSize - 1)
{
end = pstr->curSize - 1;
}
//计算删除的元素个数
int len = end - start + 1;
//开始删除,这里是数组的伪删除
for (int i = start, j = end+1; j < pstr->curSize; i++, j++)
{
pstr->str[i] = pstr->str[j];
}
pstr->curSize -= len;
pstr->str[pstr->curSize] = '\0';
}
//是否为空
bool isEmpty(string* pstr)
{
return pstr->curSize == 0;
}
//当前个数
int lenString(string* pstr)
{
return pstr->curSize;
}
//BF算法(Brute force暴力匹配)
int bfString(string* mainStr, string* subStr)
{
//参数说明:
//index:记录开始比较的起始位置
//i,j分别遍历主串和字串,判断是否相等
int index, i, j;
i = j = index = 0;
//长度合法性
if (mainStr->curSize < subStr->curSize)
{
printf("长度错误\n");
}
while (index < mainStr->curSize)
{
//如果第一个字符相同,那么一直向后比较
if (mainStr->str[index] == subStr->str[j])
{
//开始比较过程
i = index;
while (j < subStr->curSize)
{
if (mainStr->str[i] == subStr->str[j])
{
i++;
j++;
}
//有一个字符不相等,则退出循环,将j置为0是为了开始下一次匹配
else
{
j = 0;
break;
}
}
//如果j!=0,那么说明字串每一个字符都可以匹配,所以直接返回index即可
if (j != 0)
{
return index;
}
//反之说明没有匹配到,index继续向后
index++;
}
//如果第一个字符不相同,则不会开启匹配过程
else
{
index++;
}
}
//如果上面没有return,那么就说明没有找到,则返回-1
return -1;
}
//kmp算法
//求解next数组(处理第i个不匹配时,如何开始下一次匹配的问题)
void nextArray(string* subStr, int* next)
{
//i在后面走,j在前面走
int i, j;
i = 0, j = -1;
//将第0个置为-1
next[0] = -1;
//求最大的公共前缀和后缀串长度
while (i < subStr->curSize)
{
if (j == -1 || subStr->str[i] == subStr->str[j])
{
i++;
j++;
next[i] = j;
}
else
{
//重置j的值
j = next[j];
}
}
}
//开始匹配(移位过程)
int kmpString(string* mainStr, string* subStr)
{
//先判断长度的合法性
if (mainStr->curSize < subStr->curSize)
{
printf("长度错误\n");
return -1;
}
//创建i,j分别遍历主串和子串
int i, j;
i = j = 0;
//根据元素个数动态申请内存
//这里为何要加1呢?多申请一个(因为上面i++之后对next进行了赋值,导致数组下标溢出)
int *next=(int*)malloc(subStr->curSize*sizeof(int)+1);
//获取next数组
nextArray(subStr,next);
//开始匹配操作
while (i < mainStr->curSize && j < subStr->curSize)
{
if (j == -1 || mainStr->str[i] == subStr->str[j])
{
i++;
j++;
}
else
{
j = next[j];
}
//结束判断
if (j == subStr->curSize)
{
return i - j;
}
}
//free(next);
return -1;
}
//样本数量
#define sampleSize 50
//病毒DNA最大长度
#define virusMaxSize 20
//人的DNA最大长度
#define peopleMaxSize 500
//注:在结构体声明中,定义了MAXSIZE为char的最大长度,这里的病毒和人DNA不得超过MAXSIZE
//将字符串第一个字符移动到最后一个
void getCirculation(string* pstr)
{
//先保存第一个字符
char temp = pstr->str[0];
//后续的字符都整体向前移动
for (int i = 1; i < pstr->curSize; i++)
{
pstr->str[i - 1] = pstr->str[i];
}
//将最后一个字符改为第一个字符
pstr->str[pstr->curSize - 1] = temp;
}
void virusDetection(void)
{
//定义两个指针数组来分别来接受病毒的DNA和人的DNA序列
string* virus[sampleSize];
string* people[sampleSize];
//count用来记录输入的样本数量,以便于后续处理
int count = 0;
for (int i = 0;; i++)
{
//读取数据
char virus_temp[virusMaxSize];
char people_temp[peopleMaxSize];
scanf("%s %s", virus_temp, people_temp);
count++;
//创建结构体
virus[i] = createString(virus_temp);
people[i] = createString(people_temp);
//清楚缓存区字符
while (getchar() != '\n');
//设置结束条件
if (!strcmp(virus[i]->str, "0") && !strcmp(people[i]->str, "0"))
{
break;
}
}
//最后的0不算是样本
count--;
//数据读取完成后开始检测
/*由于病毒的DNA是环状的,这里选择创建一个新的数组,将环状的DNA变为顺序的*/
//这里数组大小为病毒序列长度,因为是环状的,可以自己尝试找找规律,会得到virusMaxSize个不同的序列
for (int i = 0; i < count; i++)
{
//赋值变量
int flag = -1;
//virus->curSize是病毒实际的长度
//此步骤是获取一个病毒DNA的所有顺序DNA序列
for (int j = 0; j < virus[i]->curSize; j++)
{
//循环一次,得到一个不同的序列
getCirculation(virus[i]);
//查找一次(这里也可以用bf算法)
int end = kmpString(people[i], virus[i]);
//如果查到了,那么说明已经感染,则进行下一个样本的比较
if (end != -1)
{
printf("YES\n");
flag = 1;
break;
}
}
//判断是否 一个样本中,查找完对应的所有的病毒序列,还没有查到
if (flag == -1)
{
printf("NO\n");
}
}
}最后就是测试了,创建test.c用于函数测试
#include"mystring.h"
int main()
{
virusDetection();
return 0;
}输入样例:
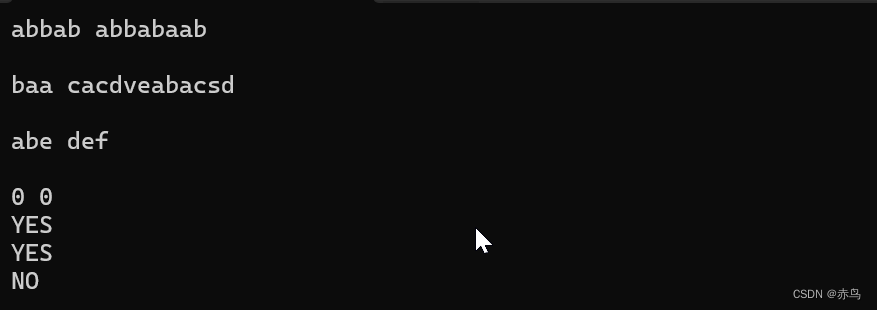
abbab abbabaab
baa cacdveabacsd
abe def
0 0
输出:
代码中的难点在于kmp算法的实现,建议阅读《大话数据结构》,再看B站的视频加深理解,一个讲的很好的视频:BV1jb411V78H
如有错误,请在评论区指正,谢谢!!















 6081
6081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









