









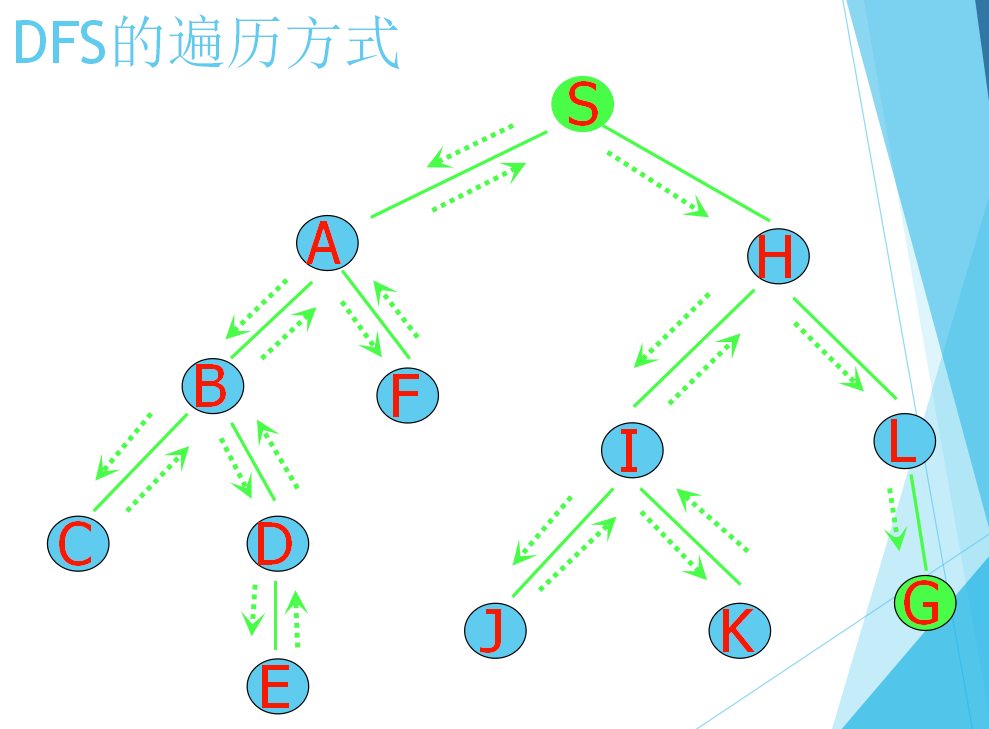
DFS(depth first search):深度优先搜索,即一种有一定策略的枚举
核心:递归
特点:
1. 一搜到底,不通则返
2. 平等遍历,只看方向
3. 只求可行,不求最优
4. 效率过低
DFS伪代码:
depthFirstSearch(v)
{
Label vertex v as reached.
for(each unreached vertex u adjacent from v)
depthFirstSearch(u);
} DFS基本思想:
从初始状态S开始,利用规则生成搜索树下一层任一个结点,检查是否出现目标状态G,若未出现,以此状态利用规则生成再下一层任一个结点,再检查是否为目标节点G,若未出现,继续以上操作过程,一直进行到叶节点(即不能再生成新状态节点),当它仍不是目标状态G时,回溯到上一层结果,取另一可能扩展搜索的分支。生成新状态节点。若仍不是目标状态,就按该分支一直扩展到叶节点,若仍不是目标,采用相同的回溯办法回退到上层节点,扩展可能的分支生成新状态,…,一直进行下去,直到找到目标状态G为止。
DFS基本框架:
DFS(dep,…) //dep代表目前DFS的深度
{
if (找到解||走不下去了)
{
…
return;
}
枚举下一种情况,DFS(dep+1,…)
}
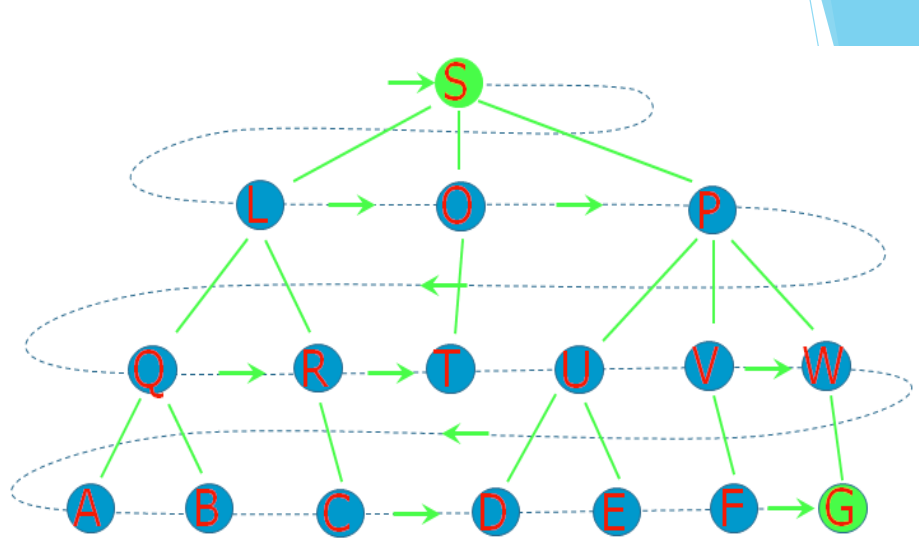
BFS(breadth first search):广度优先搜索,按层次的顺序来遍历搜索树
核心:找邻接的符合条件的点,一层一层的拓开。
BFS特点:
若所有边的长度相等,BFS算法是最佳解——亦即它找到的第一个解,距离根节点的边数目一定最少;但对一般的图来说,BFS并不一定回传最佳解。这是因为当图形为加权图(亦即各边长度不同)时,BFS仍然回传从根节点开始,经过边数目最少的解;而这个解距离根节点的距离不一定最短。这个问题可以使用考虑各边权值,BFS的改良算法——Dijkstra算法来解决。然而,若非加权图形,则所有边的长度相等,BFS就能找到最近的最佳解。
BFS伪代码:
breadthFirstSearch(v)
{
Label vertex v as reached.
Initialize Q to be a queue with only v in it.
while(Q is not empty)
{
Delete a vertex w from the queue.
Let u be a vertex (if any) adjacent from w.
while(u != NULL)
{
if(u has not been labeled)
{
Add u to the queue.
Label u as reached.
}
u = next vertex that is adjacent from w.
}
}
}BFS基本步骤:
1.使用结构体(或者普通的数据类型)存储点,使起始点入队;
2.先让队列顶部的点出队,判断该点是否符合要求,若不符合要求,从该点向外部 的可行方向进行延伸,同时使用vis数组标记这些点的访问情况;若该点符合要求,直接return相关信息;
3.依次判断队列顶部的点,直至队列被清空;
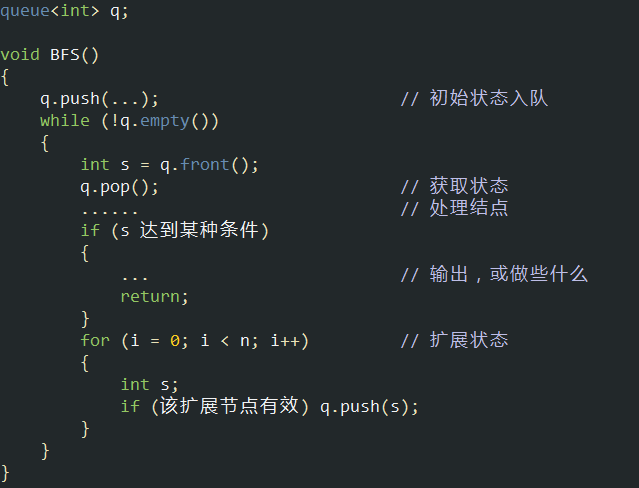
BFS基本框架:
比较分析:
除综上对外, 可以验证dfs和bfs有相同的时间和空间复杂性。不过,使dfs占用空间最大(栈递归空间)的实例却是使bfs占用空间最小(队列空间)的实例,而使bfs占用空间最大的实例确实使dfs占用空间最小的实例。















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









