







(这篇文章是我在微信公众号上发表的一篇文章)
这次博主和大家谈一谈信息熵。在大家学习数据挖掘算法中的决策树时,会知道决策树是通过信息熵来判读哪个特征是最适合做当前的根结点的。当然信息熵还可以被应用于压缩领域,通过信息熵可以知道文件的压缩下限。
那么到底什么是信息熵呢?首先提到熵,我们可能想的是在中学时代我们物理中的热力学的一个概念——通过熵来表示不稳定性。香农(本文封面是他的照片)把熵的概念引入到信息学当中,用来表示信息的不确定性,也就是信息熵越高,不确定性就越大,所需要的信息觉越多。网上常用世界杯32支足球队的例子来说明信息的度量问题。要知道世界杯32强哪支球队夺冠需要多少信息。如果获胜的概率相同的话我们需要的信息认为是5比特。那问什么呢?
对二进制比较熟悉的童鞋可能知道5比特正好可以表示32种状态。如果给32支球队按0到31编上号,那么00000是第0号球队而11111是第31号球队,正好需要5位也就是5比特就可以表示0到31号球队,也就是0到31号球队哪支球队获胜的32条状态。
但是这是在我们不知道这32支球队都是哪支弱哪支强的情况下的信息熵,而如果告诉了我们队名(也就是获得了一些信息)那么信息熵就会下降,也就是”哪支球队会夺冠“需要的信息就少了。因为我们知道像德国,巴西这些国家队比日本、韩国更有可能夺冠。这了可以看出我们其实可以用概率来表示需要的信息。当一个事件的概率是1的时候我们不需要任何信息,而一个事件概率是0的时候我们需要无穷的信息。事件的概率越大需要的信息越少,也就是信息熵是关于概率单调递减的。而两个独立事件所需要的信息是应该相加的。
香农给出的信息熵公式如下
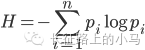
其中H表示信息熵,p表示某个事件的概率。
感兴趣的同学可以去证明一下。
后记:
博主不是信号专业出身可能还有不足之处,如果有感兴趣的童鞋可以去看一想吴军先生的《数学之美》这本书用了一章对信息熵做了通俗易懂的讲解。(大神们可以去看看香农的《信息论》)
接下来几篇文章博主可能会和大家聊一聊推荐系统。















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









