






word embedding
1-of-N encoding

缺陷:无法表征单词间的词义关系,如无法表示cat和dog都是动物,所以应该更接近。
Word Class
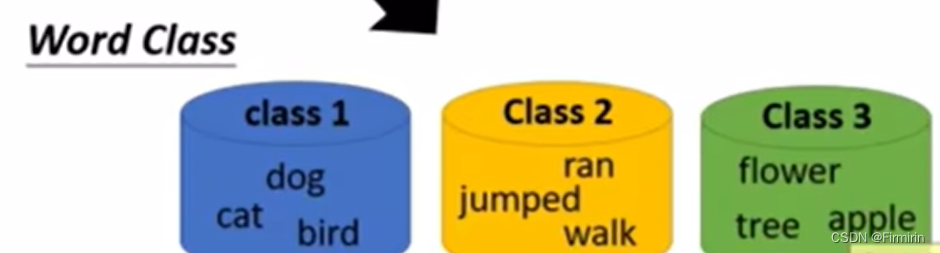
缺陷:太粗糙了,例如dog和cat都是哺乳动物,应该和bird有所不同。
Word Embedding
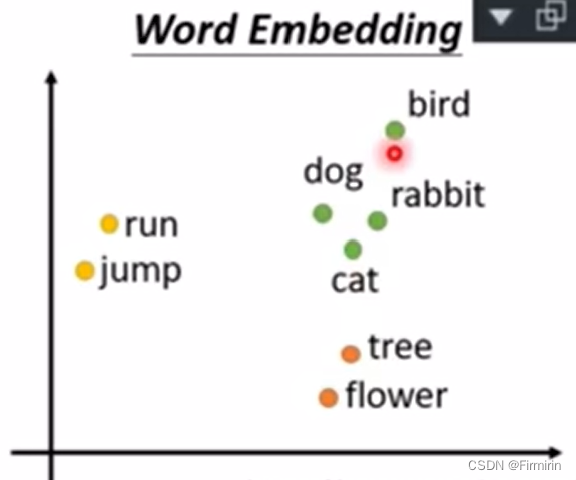
使用一个多维向量表示一个词汇,每个维度就是一个可分类的维度,例如是否为动物,是否为哺乳类。
一词多义的编码
一个词可能有多种语义,那给如何对应embedding?
传统做法1:一个词对应一个embedding
传统做法2:查字典,每个意思对应一种embedding
但实际生活中一个词的语义不止词典中可以查到的。
Contextualized Word Embedding
每个word token都有一个embedding
ELMO(embedding from language model)
RNN-based model training from lots of sentences
预测下一个token
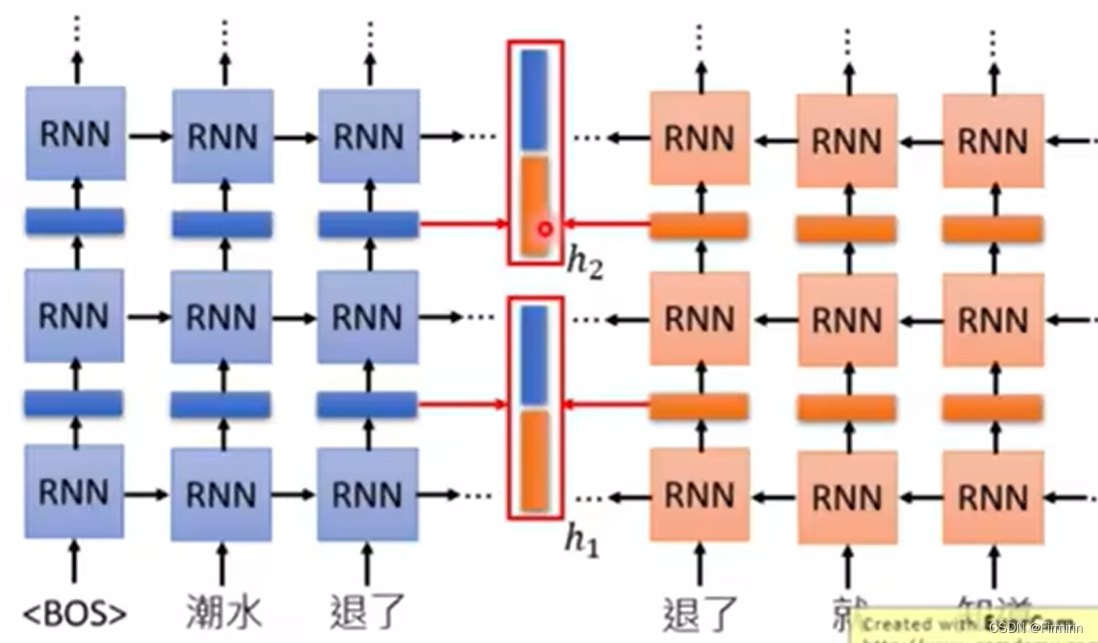
应该选哪一层的embedding?全都用
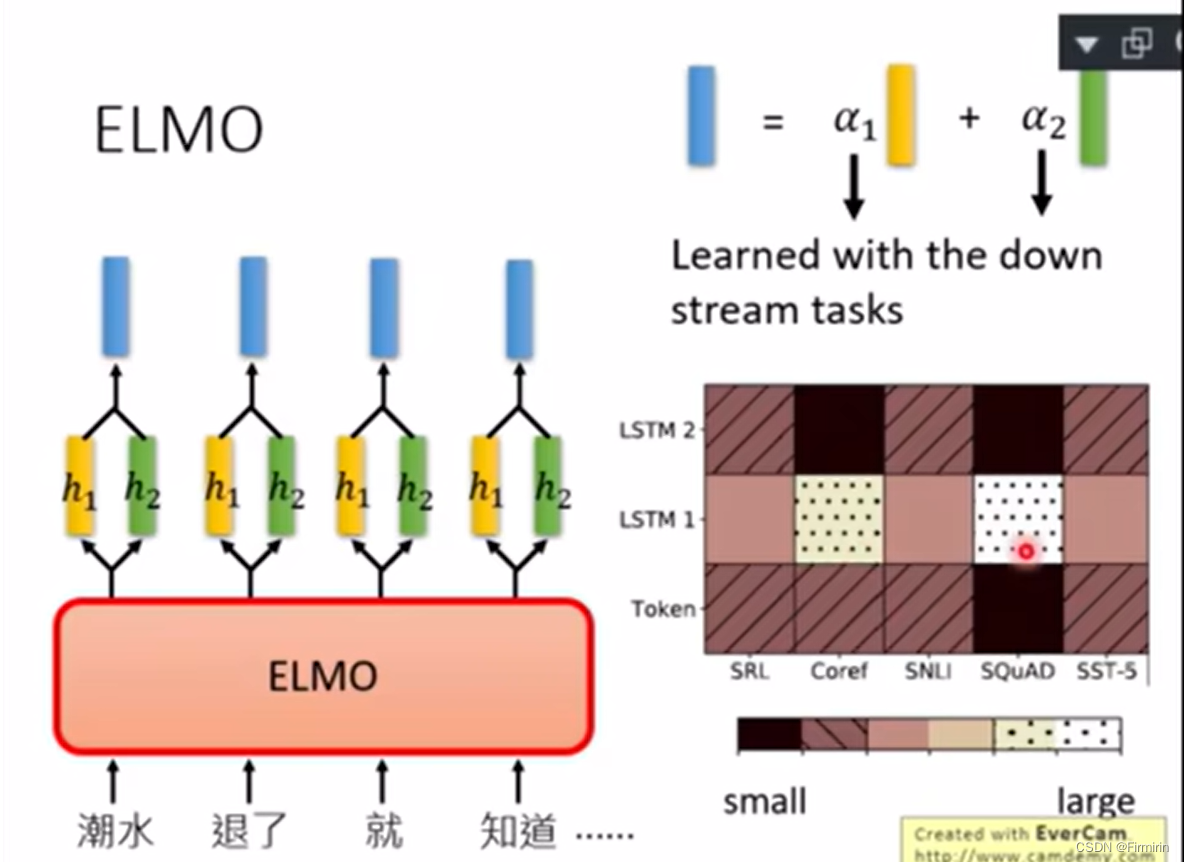
α1α2是学出来的,通过下游任务学习不同的权重
Bert
Bidirectional Encoder Representation from Transformer
training
下游任务
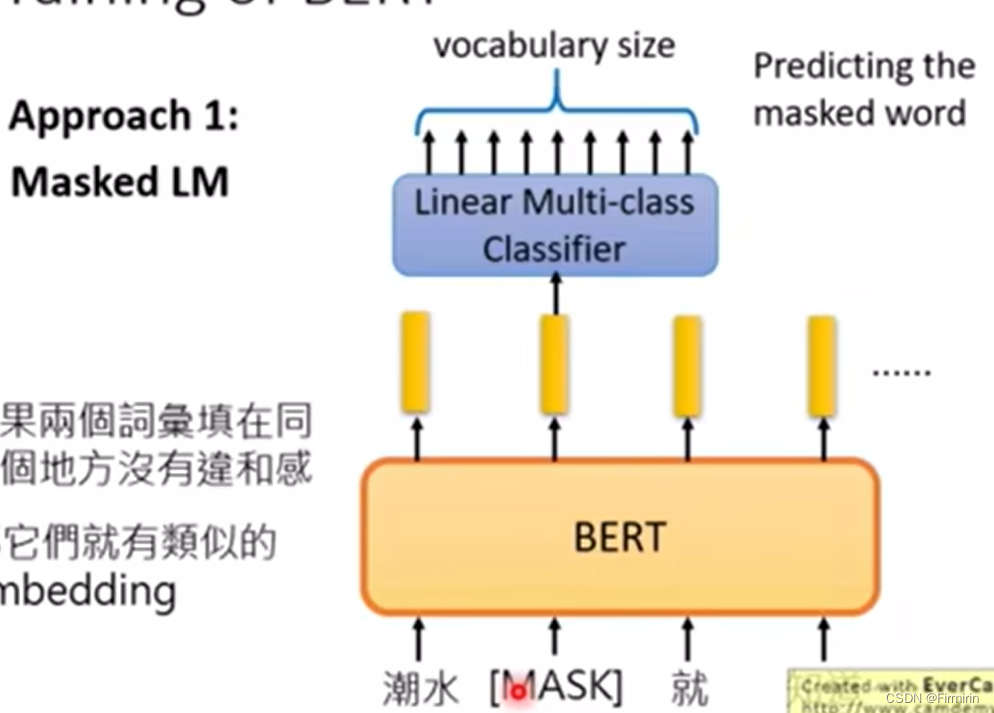
approach1
遮住部分词,预测这个词
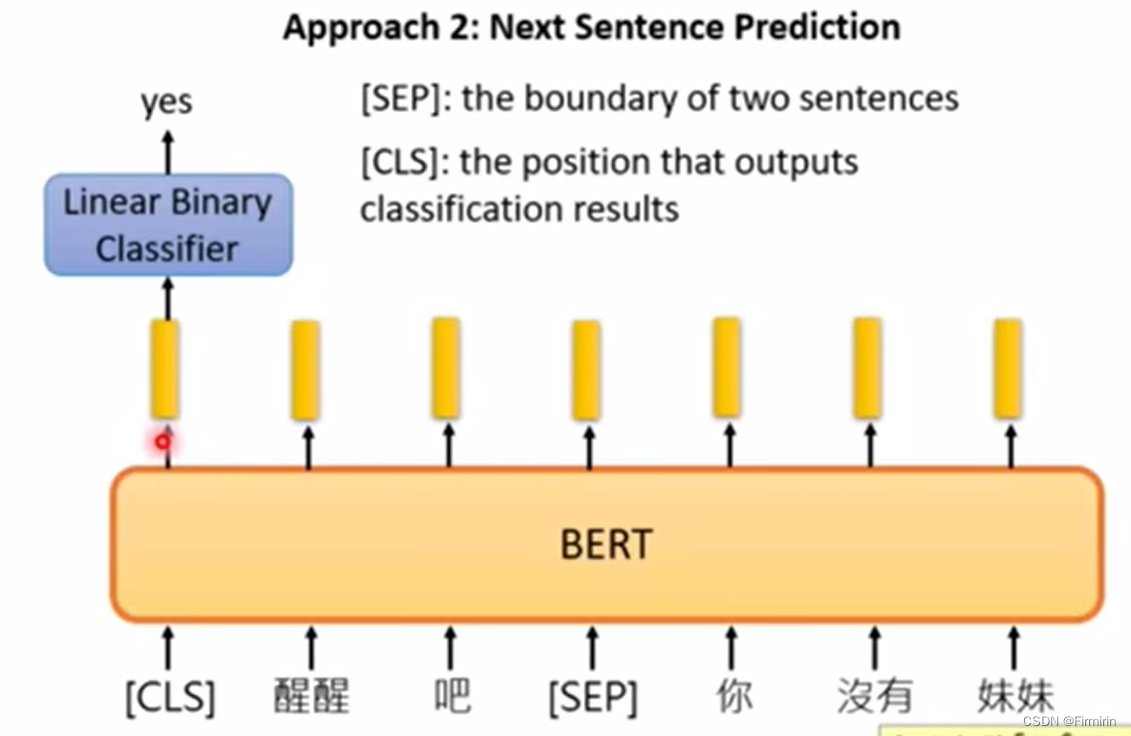
approach2
给两个句子,bert预测这两个句子是否是连在一起的
使用特殊符号SEP表示两个句子是否相连
两个方法是同时使用的。
How to use
case1 句子分类
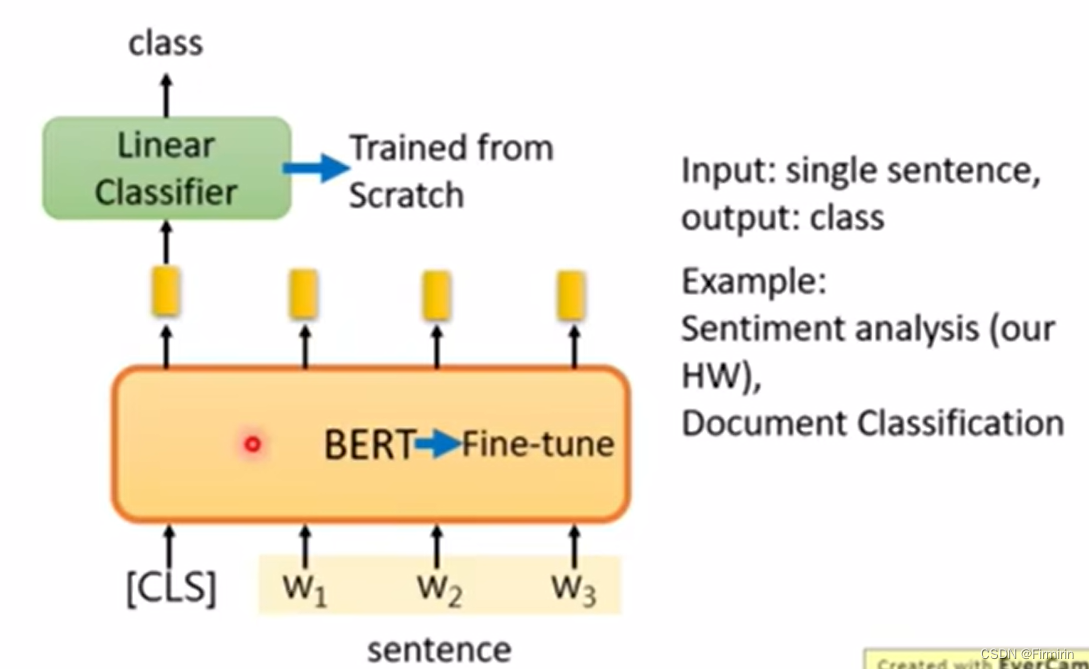
在下游任务中,分类头从头训练,bert微调
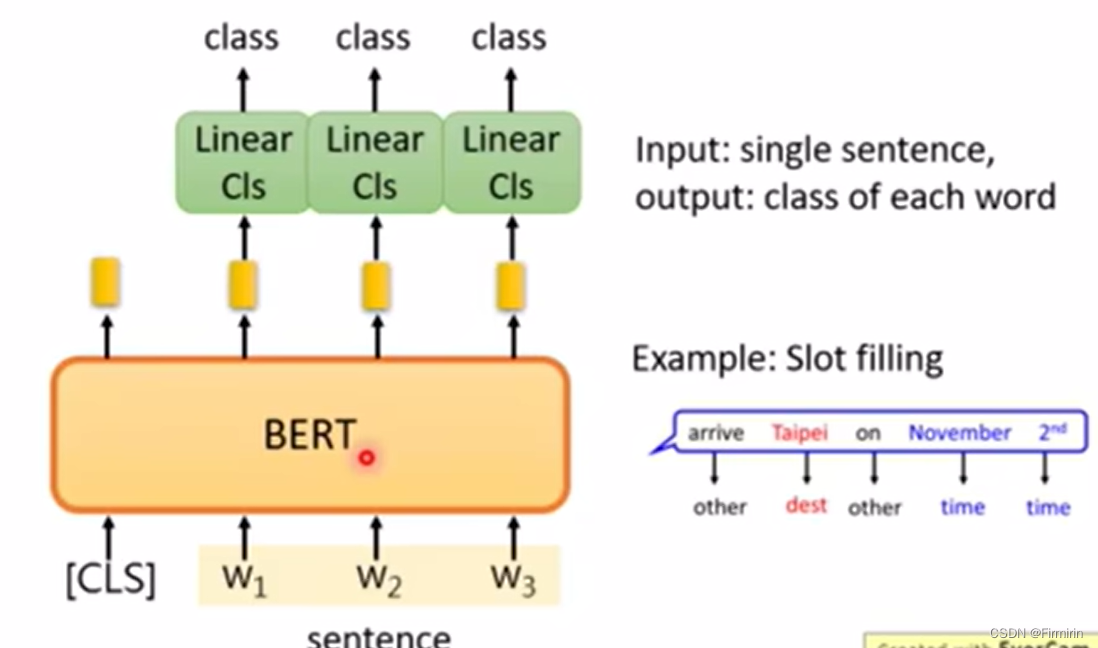
Case2 句子中的词汇分类
Case3
给定两个句子(前提和假设),判断这个逻辑推理是否正确
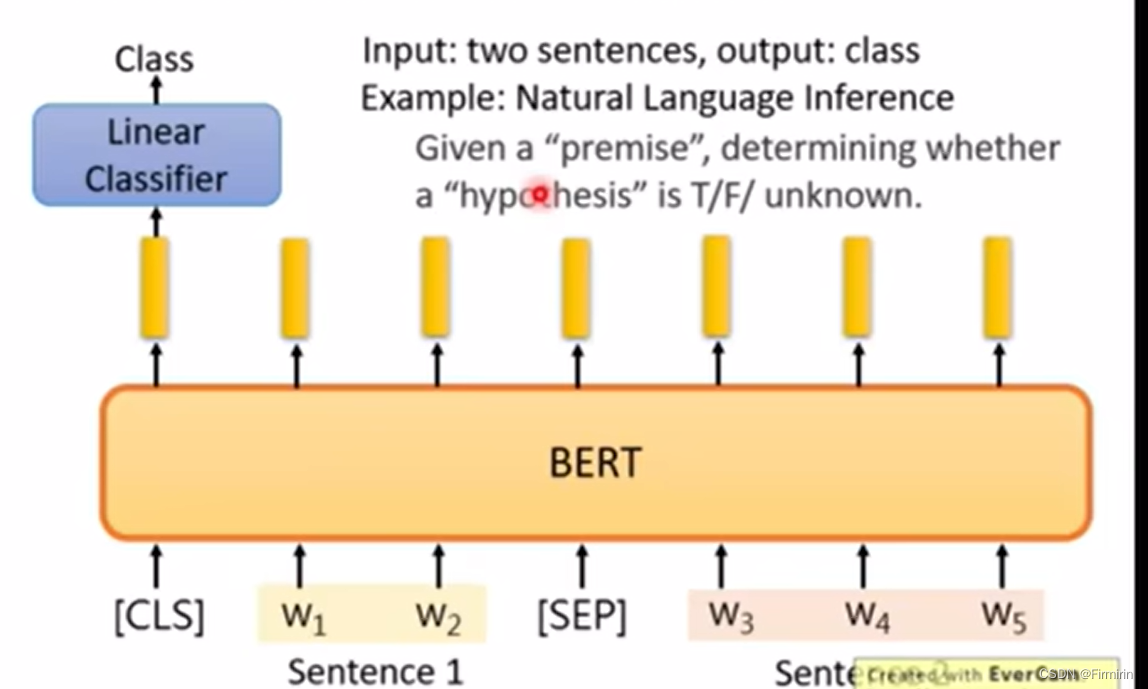
Case4

输入一篇文章D和问题Q,输出正确答案在D中出现的位置(必然在文中出现过)
具体实现:
两个token分别表征正确答案出现位置的左边界和右边界,计算作者两个token和文章对应token的点乘结果,再取softmax结果,最高结果对应的位置的范围是所求结果(可能存在左>右,此时认为该任务无解)
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









