







 本文探讨了如何通过使用Bert模型进行文本嵌入,并结合Faiss索引技术解决文本相似度计算的问题,特别关注了如何选择合适的模型和调整参数以提高相似度匹配的准确性。作者分享了两个实际案例,一个是地址相似度匹配,另一个是使用GPU加速处理大量文本数据。
本文探讨了如何通过使用Bert模型进行文本嵌入,并结合Faiss索引技术解决文本相似度计算的问题,特别关注了如何选择合适的模型和调整参数以提高相似度匹配的准确性。作者分享了两个实际案例,一个是地址相似度匹配,另一个是使用GPU加速处理大量文本数据。
目录
背景
想要求两个文本的相似度,就单纯相似度,不要语义相似度,直接使用 bert 先 embedding 然后找出相似的文本,效果都不太好,试过 bert-base-chinese,bert-wwm,robert-wwm 这些,都有一个问题,那就是明明不相似的文本却在结果中变成了相似,真正相似的有没有,
例如:手机壳迷你版,与这条数据相似的应该都是跟手机壳有关的才合理,但结果不太好,明明不相关的,余弦相似度都能有有 0.9 以上的,所以问题出在 embedding 上,找了适合做 embedding 的模型,再去计算相似效果好了很多,合理很多。
之前写了一篇 bert+np.memap+faiss文本相似度匹配 topN-CSDN博客 是把流程打通,现在是找适合文本相似的来操作。
模型:
bge-small-zh-v1.5
bge-large-zh-v1.5
embedding
数据弄的几条测试数据,方便看那些相似
我用 bge-large-zh-v1.5 来操作,embedding 代码,为了知道 embedding 进度,加了进度条功能,同时打印了当前使用 embedding 的 bert 模型输出为度,这很重要,会影响求相似的 topk
import numpy as np
import pandas as pd
import time
from tqdm.auto import tqdm
from transformers import AutoTokenizer, AutoModel
import torch
class TextEmbedder():
def __init__(self, model_name="./bge-large-zh-v1.5"):
# self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 自己电脑跑不起来 gpu
self.device = torch.device("cpu")
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name).to(self.device)
self.model.eval()
# 没加进度条的
# def embed_sentences(self, sentences):
# encoded_input = self.tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# with torch.no_grad():
# model_output = self.model(**encoded_input)
# sentence_embeddings = model_output[0][:, 0]
# sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
#
# return sentence_embeddings
# 加进度条
def embed_sentences(self, sentences):
embedded_sentences = []
for sentence in tqdm(sentences):
encoded_input = self.tokenizer([sentence], padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = self.model(**encoded_input)
sentence_embedding = model_output[0][:, 0]
sentence_embedding = torch.nn.functional.normalize(sentence_embedding, p=2)
embedded_sentences.append(sentence_embedding.cpu().numpy())
print('当前 bert 模型输出维度为,', embedded_sentences[0].shape[1])
return np.array(embedded_sentences)
def save_embeddings_to_memmap(self, sentences, output_file, dtype=np.float32):
embeddings = self.embed_sentences(sentences)
shape = embeddings.shape
embeddings_memmap = np.memmap(output_file, dtype=dtype, mode='w+', shape=shape)
embeddings_memmap[:] = embeddings[:]
del embeddings_memmap # 关闭并确保数据已写入磁盘
def read_data():
data = pd.read_excel('新建 XLSX 工作表.xlsx')
return data['addr'].to_list()
def main():
# text_data = ["这是第一个句子", "这是第二个句子", "这是第三个句子"]
text_data = read_data()
embedder = TextEmbedder()
# 设置输出文件路径
output_filepath = 'sentence_embeddings.npy'
# 将文本数据向量化并保存到内存映射文件
embedder.save_embeddings_to_memmap(text_data, output_filepath)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start)求最相似的 topk
使用 faiss 索引需要设置 bert 模型的维度,所以我们前面打印出来了,要不然会报错,像这样的:
ValueError: cannot reshape array of size 10240 into shape (768)所以 print('当前 bert 模型输出维度为,', embedded_sentences[0].shape[1]) 的值换上去,我这里打印的 1024
index = faiss.IndexFlatL2(1024) # 假设BERT输出维度是768
# 确保embeddings_memmap是二维数组,如有需要转换
if len(embeddings_memmap.shape) == 1:
embeddings_memmap = embeddings_memmap.reshape(-1, 1024)完整代码
import pandas as pd
import numpy as np
import faiss
from tqdm import tqdm
def search_top4_similarities(index_path, data, topk=4):
embeddings_memmap = np.memmap(index_path, dtype=np.float32, mode='r')
index = faiss.IndexFlatL2(768) # 假设BERT输出维度是768
# 确保embeddings_memmap是二维数组,如有需要转换
if len(embeddings_memmap.shape) == 1:
embeddings_memmap = embeddings_memmap.reshape(-1, 768)
index.add(embeddings_memmap)
results = []
for i, text_emb in enumerate(tqdm(embeddings_memmap)):
D, I = index.search(np.expand_dims(text_emb, axis=0), topk) # 查找前topk个最近邻
# 获取对应的 nature_df_img_id 的索引
top_k_indices = I[0][:topk] #
# 根据索引提取 nature_df_img_id
top_k_ids = [data.iloc[index]['index'] for index in top_k_indices]
# 计算余弦相似度并构建字典
cosine_similarities = [cosine_similarity(text_emb, embeddings_memmap[index]) for index in top_k_indices]
top_similarity = dict(zip(top_k_ids, cosine_similarities))
results.append((data['index'].to_list()[i], top_similarity))
return results
# 使用余弦相似度公式,这里假设 cosine_similarity 是一个计算两个向量之间余弦相似度的函数
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def main_search():
data = pd.read_excel('新建 XLSX 工作表.xlsx')
data['index'] = data.index
similarities = search_top4_similarities('sentence_embeddings.npy', data)
# 输出结果
similar_df = pd.DataFrame(similarities, columns=['id', 'top'])
similar_df.to_csv('similarities.csv', index=False)
# 执行搜索并保存结果
main_search()结果查看
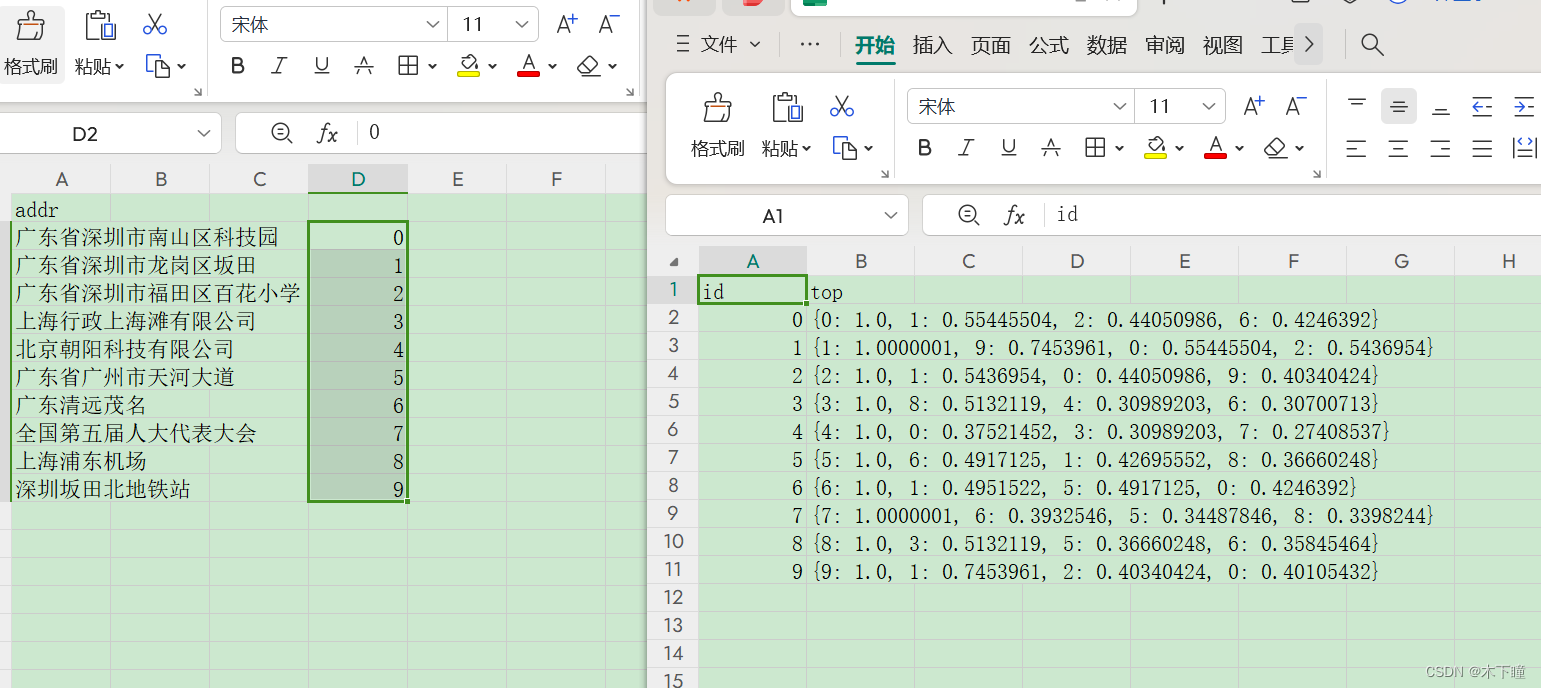
看一看到余弦数值还是比较合理的,没有那种明明不相关但余弦值是 0.9 的情况了,这两个模型还是可以的
实际案例
以前做过一个地址相似度聚合的,找出每个地址与它相似的地址,最多是 0-3 个相似的地址(当时人工验证过的,这里直接说明)
我们用 bge-small-zh-v1.5 模型来做 embedding,这个模型维度是 512,数据是店名id,地址两列
embedding 代码:
import numpy as np
import pandas as pd
import time
from tqdm.auto import tqdm
from transformers import AutoTokenizer, AutoModel
import torch
class TextEmbedder():
def __init__(self, model_name="./bge-small-zh-v1.5"):
# self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 自己电脑跑不起来 gpu
self.device = torch.device("cpu")
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name).to(self.device)
self.model.eval()
# 没加进度条的
# def embed_sentences(self, sentences):
# encoded_input = self.tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# with torch.no_grad():
# model_output = self.model(**encoded_input)
# sentence_embeddings = model_output[0][:, 0]
# sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
#
# return sentence_embeddings
def embed_sentences(self, sentences):
embedded_sentences = []
for sentence in tqdm(sentences):
encoded_input = self.tokenizer([sentence], padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = self.model(**encoded_input)
sentence_embedding = model_output[0][:, 0]
sentence_embedding = torch.nn.functional.normalize(sentence_embedding, p=2)
embedded_sentences.append(sentence_embedding.cpu().numpy())
print('当前 bert 模型输出维度为,', embedded_sentences[0].shape[1])
return np.array(embedded_sentences)
def save_embeddings_to_memmap(self, sentences, output_file, dtype=np.float32):
embeddings = self.embed_sentences(sentences)
shape = embeddings.shape
embeddings_memmap = np.memmap(output_file, dtype=dtype, mode='w+', shape=shape)
embeddings_memmap[:] = embeddings[:]
del embeddings_memmap # 关闭并确保数据已写入磁盘
def read_data():
data = pd.read_excel('data.xlsx')
return data['address'].to_list()
def main():
# text_data = ["这是第一个句子", "这是第二个句子", "这是第三个句子"]
text_data = read_data()
embedder = TextEmbedder()
# 设置输出文件路径
output_filepath = 'sentence_embeddings.npy'
# 将文本数据向量化并保存到内存映射文件
embedder.save_embeddings_to_memmap(text_data, output_filepath)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start)
求 embeddgin 是串行的,要想使用 gpu ,可以需修改 embed_sentences 函数:
def embed_sentences(self, sentences, batch_size=32):
inputs = self.tokenizer(sentences, padding=True, truncation=True, return_tensors='pt').to(self.device)
# 计算批次数量
batch_count = (len(inputs['input_ids']) + batch_size - 1) // batch_size
embeddings_list = []
with tqdm(total=len(sentences), desc="Embedding Progress") as pbar:
for batch_idx in range(batch_count):
start = batch_idx * batch_size
end = min((batch_idx + 1) * batch_size, len(inputs['input_ids']))
current_batch_input = inputs[start:end]
with torch.no_grad():
model_output = self.model(**current_batch_input)
sentence_embeddings = model_output[0][:, 0]
embedding_batch = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1).cpu().numpy()
# 将当前批次的嵌入向量添加到列表中
embeddings_list.extend(embedding_batch.tolist())
# 更新进度条
pbar.update(end - start)
# 将所有批次的嵌入向量堆叠成最终的嵌入矩阵
embeddings = np.vstack(embeddings_list)
return embeddings求 topk 的,我们求 top4 就可以了
import pandas as pd
import numpy as np
import faiss
from tqdm import tqdm
def search_top4_similarities(data_target_embedding, data_ori_embedding, data_target, data_ori, topk=4):
target_embeddings_memmap = np.memmap(data_target_embedding, dtype=np.float32, mode='r')
ori_embeddings_memmap = np.memmap(data_ori_embedding, dtype=np.float32, mode='r')
index = faiss.IndexFlatL2(512) # BERT输出维度
# 确保embeddings_memmap是二维数组,如有需要转换
if len(target_embeddings_memmap.shape) == 1:
target_embeddings_memmap = target_embeddings_memmap.reshape(-1, 512)
if len(ori_embeddings_memmap.shape) == 1:
ori_embeddings_memmap = ori_embeddings_memmap.reshape(-1, 512)
index.add(target_embeddings_memmap)
results = []
for i, text_emb in enumerate(tqdm(ori_embeddings_memmap)):
D, I = index.search(np.expand_dims(text_emb, axis=0), topk) # 查找前topk个最近邻
# 获取对应的 nature_df_img_id 的索引
top_k_indices = I[0][:topk] #
# 根据索引提取 nature_df_img_id
top_k_ids = [data_target.iloc[index]['store_id'] for index in top_k_indices]
# 计算余弦相似度并构建字典
cosine_similarities = [cosine_similarity(text_emb, target_embeddings_memmap[index]) for index in top_k_indices]
top_similarity = dict(zip(top_k_ids, cosine_similarities))
results.append((data_ori['store_id'].to_list()[i], top_similarity))
return results
# 使用余弦相似度公式,这里假设 cosine_similarity 是一个计算两个向量之间余弦相似度的函数
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def main_search():
data_target = pd.read_excel('data.xlsx')
data_ori = pd.read_excel('data.xlsx')
data_target_embedding = 'sentence_embeddings.npy'
data_ori_embedding = 'sentence_embeddings.npy'
similarities = search_top4_similarities(data_target_embedding, data_ori_embedding, data_target, data_ori)
# 输出结果
similar_df = pd.DataFrame(similarities, columns=['id', 'top'])
similar_df.to_csv('similarities.csv', index=False)
def format_res():
similarities_data = pd.read_csv('similarities.csv')
ori_data = pd.read_excel('data.xlsx')
target_data = pd.read_excel('data.xlsx')
res = pd.DataFrame()
for index, row in similarities_data.iterrows():
ori_id = row['id']
tops = row['top']
tmp_ori_data = ori_data[ori_data['store_id'] == ori_id]
tmp_target_data = target_data[target_data['store_id'].isin(list(eval(tops).keys()))]
res_tmp = pd.merge(tmp_ori_data, tmp_target_data, how='cross')
res = pd.concat([res, res_tmp])
print(f'进度 {index + 1}/{len(similarities_data)}')
res.to_excel('format.xlsx', index=False)
# 执行搜索并保存结果
# main_search()
# 格式化
format_res()
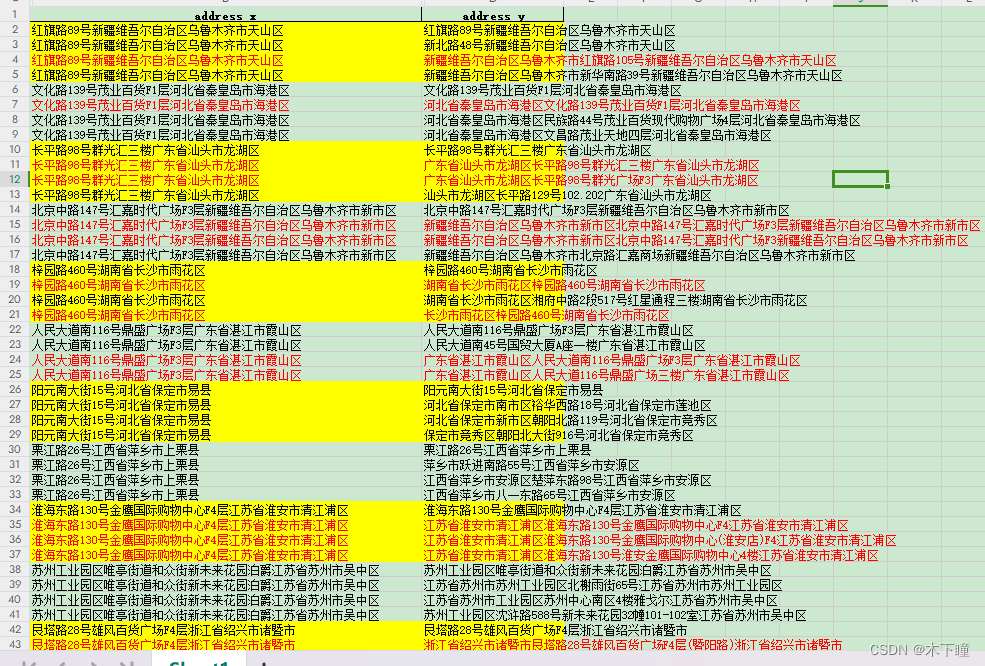
在这里我们把原始数据当两份使用,一份作为目标数据,一份原始数据,要原始数据的每一个地址在目标数据中找相似的
最后为了人工方便查看验证,数据格式化了,开始我说了,这数据结果每个地址跟它相似的有 0-3 条,黄色的每一组,红色的是真正相似的,从结果上来看,还是符合预期的
代码链接:
链接:https://pan.baidu.com/s/1S951j1TNoN9XbRA286jU-w
提取码:nb4b

















 3356
3356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









