







A0 论文阅读笔记
现有的 VLA 因缺乏空间位置理解直接生成动作,导致擦拭白板、堆叠物体等复杂任务表现欠佳。而 SpatialVLA,Any-point Trajectory Modeling,RoboPoint,Track2Act 等基于点的方法侧重轨迹建模,General Flow,Im2Flow2Act 基于流的方法侧重稠密空间表征,计算成本高,具身依赖性强。
A
0
A_0
A0 提出以物体为中心的"具身无关可供性表征",仅预测待操作物体的接触点及轨迹。该设计使方法具备跨平台泛化能力,仅需少量标注数据微调即可实际部署。

Affordance 能在复杂环境中实现结构化动作选择,基于 Heatmap 的方法能定位但计算成本高;基于边界框和关键点的方法效率和精度都好。
A
0
A_0
A0 的 Affordance 区别于 RoboBrain 和 Robopoint 的是,他是一个接触点而不是接触区域。
A 0 A_0 A0 其核心创新在于将任务分解为高层空间可操作性推理与底层动作执行,通过跨平台的具身无关可操作性表示(Embodiment-Agnostic Affordance Representation)预测物体中心的接触点与轨迹,实现多机器人系统的泛化能力。

采用 DROID-2k、HOI4D-22k、ManiSkill-5k 按照 8:2 划分作为数据集
具身无关数据表示:
R
=
R
R
∪
R
H
∪
R
C
=
{
(
I
,
L
,
C
,
T
)
∣
C
=
(
c
0
2
D
)
,
T
=
(
t
0
2
D
,
t
1
2
D
,
t
2
2
D
,
…
…
)
}
\mathcal{R}=\mathcal{R}_R \cup \mathcal{R}_H \cup \mathcal{R}_C =\{(I,L,C,T)|C=(c_0^{2D}),T=(t_0^{2D},t_1^{2D},t_2^{2D},……)\}
R=RR∪RH∪RC={(I,L,C,T)∣C=(c02D),T=(t02D,t12D,t22D,……)} (以物体为中心的图像——当前帧,一组二维 waypoint——接触点、接触后的轨迹)
- 视觉编码器:使用预训练的 SigLiP(400M) 提取图像特征,将 I t − 1 I_{t-1} It−1 和 I t I_t It 分别编码为 token 序列。
- 文本编码器:使用预训练的 Qwen2.5-7B 提取语言指令的 token。
- 运动信息增强: 通过计算当前帧与前一帧 token 的差值 I m = I t i − I t − 1 i I^m=I_t^i-I_{t-1}^i Im=Iti−It−1i,并与当前帧 token 拼接( o t = c o n c a t ( [ I t i , I m i ] , d i m = 1 ) o_t=concat([I_t^i,I_m^i],dim=1) ot=concat([Iti,Imi],dim=1)),增强模型对物体运动的感知。
模型以带噪声的轨迹点坐标和扩散步长为输入,通过帧间差分增强运动感知,结合位置编码和层级特征交互,最终通过 MLP 解码器输出去噪后的未来T步轨迹点。训练分为两阶段:预训练阶段聚焦单点定位(起始点),微调阶段扩展至多步轨迹预测,均采用MSE损失监督坐标生成,并通过ODE求解器加速推理。
预训练仅预测起始点
x
t
x_t
xt:
L
p
(
θ
)
=
1
n
∑
i
=
1
n
(
(
x
t
0
)
i
−
(
f
θ
(
k
,
x
t
k
,
I
t
,
ℓ
)
)
i
)
2
.
\mathscr{L}_p(\theta)=\frac{1}{n}\sum_{i=1}^n((x_t^0)_i-(f_\theta(k,x_t^k,I_t,\ell))_i)^2.
Lp(θ)=n1i=1∑n((xt0)i−(fθ(k,xtk,It,ℓ))i)2.
微调阶段适配具体机器人任务,预测完整轨迹:
L
p
(
θ
)
=
1
n
∑
i
=
1
n
(
(
x
t
:
t
+
T
0
)
i
−
(
f
θ
(
k
,
x
t
:
t
+
T
k
,
I
t
−
1
:
t
,
ℓ
)
)
i
)
2
.
\mathscr{L}_p(\theta)=\frac{1}{n}\sum_{i=1}^n((x_{t:t+T}^0)_i-(f_\theta(k,x_{t:t+T}^k,I_{t-1:t},\ell))_i)^2.
Lp(θ)=n1i=1∑n((xt:t+T0)i−(fθ(k,xt:t+Tk,It−1:t,ℓ))i)2.
ODE 求解器将传统扩散模型的离散去噪过程转化为连续动态系统,通过线性衰减+非线性修正生成轨迹。:
d
x
k
d
k
:
=
f
(
k
)
x
k
+
g
2
(
k
)
2
σ
k
ϵ
θ
(
x
k
,
k
)
,
x
k
∼
N
(
0
,
σ
~
2
I
)
\frac{\mathrm{d}\mathbf{x}^k}{\mathrm{d}k}:=f(k)\mathbf{x}^k+\frac{g^2(k)}{2\sigma_k}\epsilon_\theta(\mathbf{x}^k,k),\mathbf{x}^k\sim\mathcal{N}(0,\tilde{\sigma}^2\boldsymbol{I})
dkdxk:=f(k)xk+2σkg2(k)ϵθ(xk,k),xk∼N(0,σ~2I)
由于模型输出的是 2D 图像坐标系下的归一化坐标
(
u
,
v
)
∈
[
0
,
1
]
2
(u,v)\in[0,1]^2
(u,v)∈[0,1]2,所以基于深度信息和相机内参,通过逆透视变换得到 3D 空间:
X
i
=
D
(
x
i
)
K
−
1
x
i
~
,
i
=
t
+
1
,
t
+
2
,
…
…
,
t
+
T
X_i=D(x_i)K^{-1}\tilde{x_i},\quad i=t+1,t+2,……,t+T
Xi=D(xi)K−1xi~,i=t+1,t+2,……,t+T
参考 MOKA 和 RAM 对于抓取姿态估计,使用 GraspNet 基于局部几何特征生成一组候选抓取姿态
G
\mathcal{G}
G,从候选集中选择与投影接触点
X
t
X_t
Xt 最接近的抓取姿态
G
∗
G^*
G∗:
G
∗
=
arg
m
i
n
∣
∣
G
−
X
t
∣
∣
G^*=\arg min||G-X_t||
G∗=argmin∣∣G−Xt∣∣
由于 waypoint 在脱离接触点后的高度无法直接从单帧深度图获取,引入 VLM 辅助决策,通过 VLM 生成语义标签 at target level 、above target、below target,根据此采样具体数值,结合抓取点
G
∗
G^*
G∗ 和路径点
{
X
t
+
1
,
…
…
,
X
t
+
T
}
\{X_{t+1},……,X_{t+T}\}
{Xt+1,……,Xt+T} ,通过运动规划器生成对应的 SE(3) 路径。
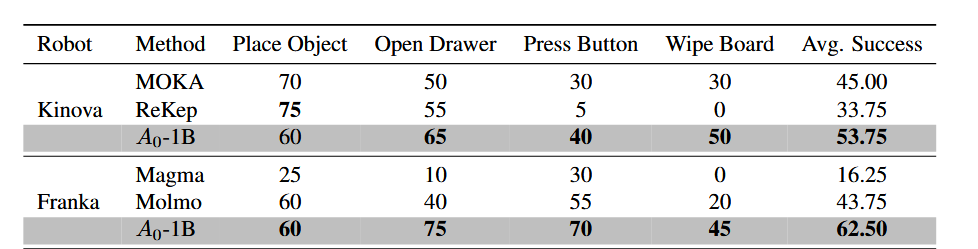
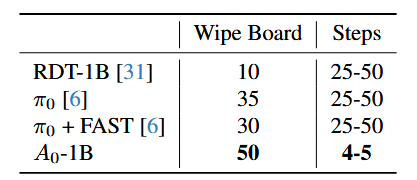
实验结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









