







Deformable 3DGS
3DGS 只能解决静态场景,对于动态场景只能逐帧重建,浪费时间,存储开销大,无连续性;在 3DGS 基础上,引入变形场使高斯分布随时间变化,从而支持动态内容。该方法类似在 4D 空间压缩数据,故事“记录”动态信息,不能让静态场景“变得动态”。(变形场调整适合规则运动)

通过一个 变形场(类似 NeRF) 和三维高斯分布来 解耦运动和几何结构(动态三维高斯分布可以映射到规范空间中)。
输入一组单目动态场景图像,SfM 校准的时间标签、相机姿态和稀疏点云,由此创建一组高斯分布
G
(
x
,
r
,
s
,
σ
)
G(x,r,s,\sigma)
G(x,r,s,σ) 。
给定时间 t 和三维高斯中心 x 作为输入,通过 MLP 产生偏移量将规范空间转换到变形高斯空间:

(
δ
x
,
δ
r
,
δ
s
)
=
F
θ
(
γ
(
s
g
(
x
)
)
,
γ
(
t
)
)
γ
(
p
)
=
(
s
i
n
(
2
k
π
p
)
,
c
o
s
(
2
k
π
p
)
)
k
=
0
L
=
1
\begin{aligned} (\delta x,\delta r, \delta s)=F_\theta(\gamma(sg(x)), \gamma(t)) \\\gamma(p)=(sin(2^k\pi p),cos(2^k\pi p))_{k=0}^{L=1} \end{aligned}
(δx,δr,δs)=Fθ(γ(sg(x)),γ(t))γ(p)=(sin(2kπp),cos(2kπp))k=0L=1
其中
s
g
(
⋅
)
sg(·)
sg(⋅) 为停止梯度,
γ
\gamma
γ 表示位置编码(实验表明:作用于输入可以增强细节)(个人感觉是让规范场和变形场交替迭代优化)
因为 colmap 从数据集中估计的姿态不准确,(显示渲染会放大这种抖动,MLP 因其连续性会缩小这种扰动),本文提出 AST 机制——在训练过程中向时间维度注入线性衰减的高斯噪声,模拟位姿误差的扰动:(使得训练出来的变形场在时域上平滑,减少抖动)
Δ
=
F
θ
(
γ
(
s
g
(
x
)
)
,
γ
(
t
)
+
χ
(
i
)
)
χ
(
i
)
=
N
(
0
,
1
)
⋅
β
⋅
Δ
t
⋅
(
1
−
i
r
)
\begin{aligned} \Delta = \mathcal{F}_\theta(\gamma(sg(x)), \gamma(t)+\chi(i)) \\\chi(i)=\mathbb{N}(0,1)·\beta·\Delta t·(1-\frac{i}{r}) \end{aligned}
Δ=Fθ(γ(sg(x)),γ(t)+χ(i))χ(i)=N(0,1)⋅β⋅Δt⋅(1−ri)
实验结果
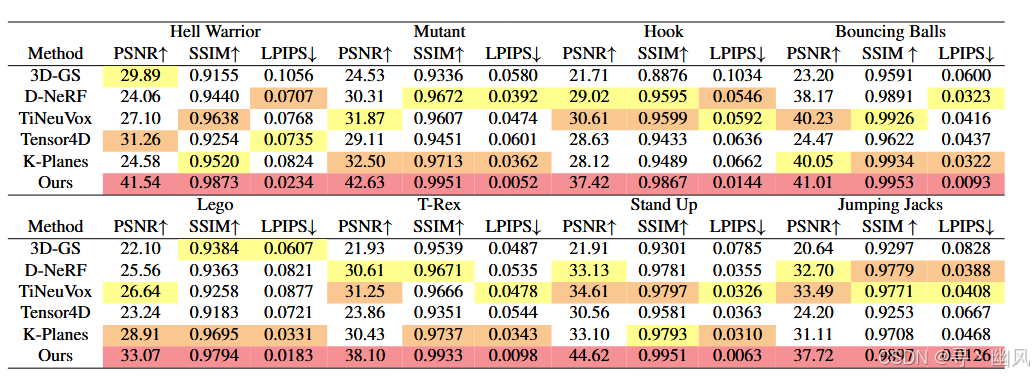
4DGS
解决动态场景的高效建模与实时渲染,避免逐帧独立重建(同 Deformable 3DGS)。但采用 4D 时空体素分解(HexPlane)联合优化高斯,相比于 Deformable 3DGS,适合复杂非刚性运动(质量高),但速度相比会慢一点,开销会增大(处理 4D 体素)。

本文于 Deformable 3DGS 相似,采用了规范空间+变形场的思路,但 4DGS 的变形场是通过学习的方式得到。
输入数据为 4D 数据
(
x
,
y
,
z
,
t
)
(x,y,z,t)
(x,y,z,t) ,初始化一组标准 3D 高斯函数,通过 HexPlane 对高斯函数编码得到时空特征,一个编码的 MLP,3 个解码的 MLP,生成高斯函数的变形值
(
Δ
x
,
Δ
y
,
Δ
z
,
Δ
r
,
Δ
s
)
(\Delta x,\Delta y, \Delta z, \Delta r,\Delta s)
(Δx,Δy,Δz,Δr,Δs) 。
HexPlane
将四维体素分解到
{
(
x
,
y
)
,
(
x
,
z
)
,
(
y
,
z
)
,
(
x
,
t
)
,
(
y
,
t
)
,
(
z
,
t
)
}
\{(x,y),(x,z),(y,z),(x,t),(y,t),(z,t)\}
{(x,y),(x,z),(y,z),(x,t),(y,t),(z,t)} 6 个 2D 平面组合,每个平面用不同分辨率 l 记录格点待编码属性(低分辨率整体,高分辨率细节),对每个平面进行双线性插值编码。
f
h
=
⋃
l
∏
i
n
t
e
r
p
(
R
l
(
i
,
j
)
)
(
i
,
j
)
∈
{
(
x
,
y
)
,
(
x
,
z
)
,
(
y
,
z
)
,
(
x
,
t
)
,
(
y
,
t
)
,
(
z
,
t
)
}
f
d
=
ϕ
d
(
f
h
)
\begin{aligned} &f_h = \bigcup_l \prod interp(R_l(i,j)) \quad (i,j)\in\{(x,y),(x,z),(y,z),(x,t),(y,t),(z,t)\} \\&f_d = \phi_d(f_h) \end{aligned}
fh=l⋃∏interp(Rl(i,j))(i,j)∈{(x,y),(x,z),(y,z),(x,t),(y,t),(z,t)}fd=ϕd(fh)
将每个隐藏元素的双线性插值结果进行分别乘积,然后对每个分辨率进行级联,得到一个
l
∗
h
l*h
l∗h 的特征向量。
l
l
l 代表不同分辨率,
h
h
h 代表编码的维度(位置偏移3+scale偏移3+rotation偏移4)
损失函数:
L
=
∣
I
^
−
I
∣
+
L
t
v
L
T
V
(
P
)
=
1
∣
C
∣
n
2
∑
c
,
i
,
j
(
∣
∣
P
c
i
,
j
−
P
c
i
−
1
,
j
∣
∣
2
2
+
∣
∣
P
c
i
,
j
−
P
c
i
,
j
−
1
∣
∣
2
2
)
\begin{aligned} &\mathcal{L} = |\hat{I}-I|+\mathcal{L}_{tv} \\&\mathcal{L}_{TV}(P)=\frac{1}{|C|n^2}\sum_{c,i,j}(||\boldsymbol{P}_c^{i,j}-\boldsymbol{P}_c^{i-1,j}||_2^2+||\boldsymbol{P}_c^{i,j}-\boldsymbol{P}_c^{i,j-1}||_2^2) \end{aligned}
L=∣I^−I∣+LtvLTV(P)=∣C∣n21c,i,j∑(∣∣Pci,j−Pci−1,j∣∣22+∣∣Pci,j−Pci,j−1∣∣22)
L T V \mathcal{L}_{TV} LTV 从 K-planes 中截取,P 与本文 R 相同。
实验结果
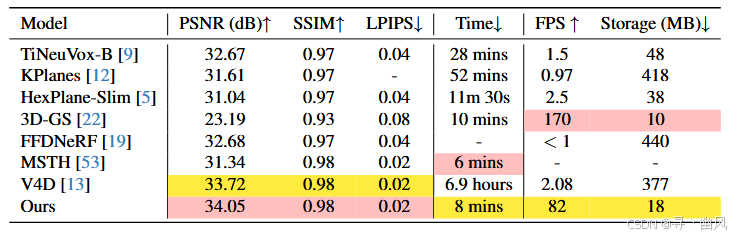
总结
4DGS将四维空间中的特征属性投影到多个二维平面并栅格化,类似数据压缩,但处理稀疏输入如单目视频时,可能因信息不足导致恢复结果有歧义。而deformable 3DGS的MLP模型直接在四维空间压缩数据,对单目视频更友好,效果可能更好。

















 4806
4806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









