






一、实验目的
通过本实验系统掌握聚类内容,了解k-means算法的实验原理以及求解步骤。
二、实验内容
编写matlab程序,对satimage数据集进行k-means聚类,簇个数为k。
三、实验要求
satimage-data.xls文件包含2000条记录,每条记录对应于卫星遥感图片中的一块区域,属于以下类别{red soil,cotton crop,grey soil,damp grey soil,soil with vegetation stubble,very damp grey soil}.每条记录都有36个属性(4光谱波段×9像素),通过距离函数、初始化、k值的设置对satimage数据集进行聚类。
四、算法描述
k-means聚类算法是一种基于距离度量的无监督学习算法,其目的是将数据集分成k个不同的簇。算法基于距离度量,在整个数据集中随机选取k个点作为簇的中心,并将每个点分配到距离其最近的中心所在的簇中。在簇分配完成后,重新计算每个簇的中心点,并继续进行新的簇分配,直到达到停止条件(例如簇中心不再改变)。k-means聚类算法强调最小化簇内平方和(SSE)的优化目标,即最小化每个簇中样本与簇中心的距离平方和。
该算法的优势在于其简单和高效性,但同样存在不足之处,例如需要指定k值,可能会导致产生不理想的聚类。另外,它对初始簇中心的选择和噪声敏感,因此需要进行预处理。
k-means算法步骤如下:
(1)随机选取K个样本为中心
(2)分别计算所有样本到随机选取的K个中心的距离
(3)样本离哪个中心近就被分到哪个中心
(4)计算各个中心样本的均值(最简单的方法就是求样本每个维度的平均值)作为新的中心
(5)重复(2)(3)(4)直到新的中心和原来的中心基本不变化的时候,算法结束
五、调试过程及实验结果
通过设置不同的k值得到不同的分类:
K = 3时
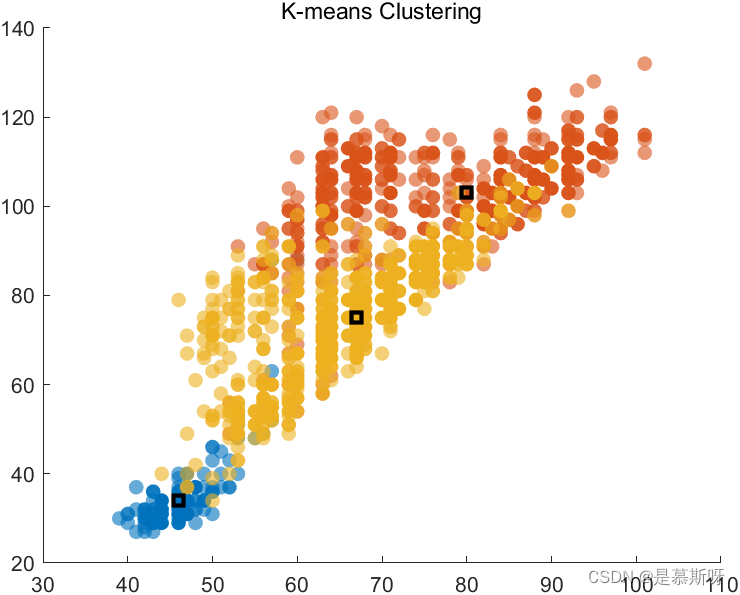 K=4时
K=4时
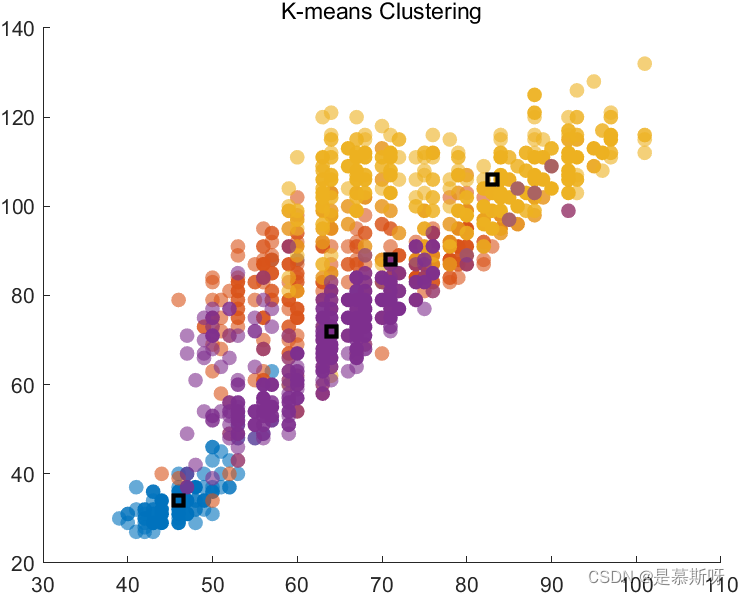
K = 6时
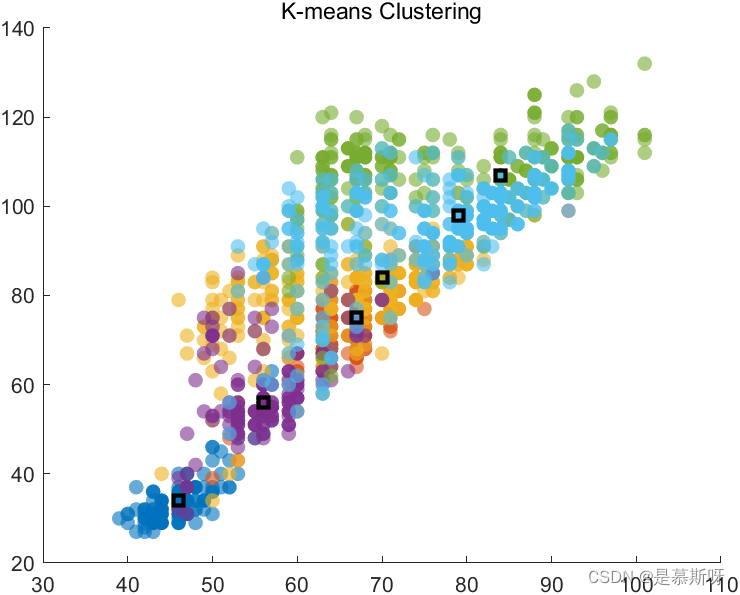
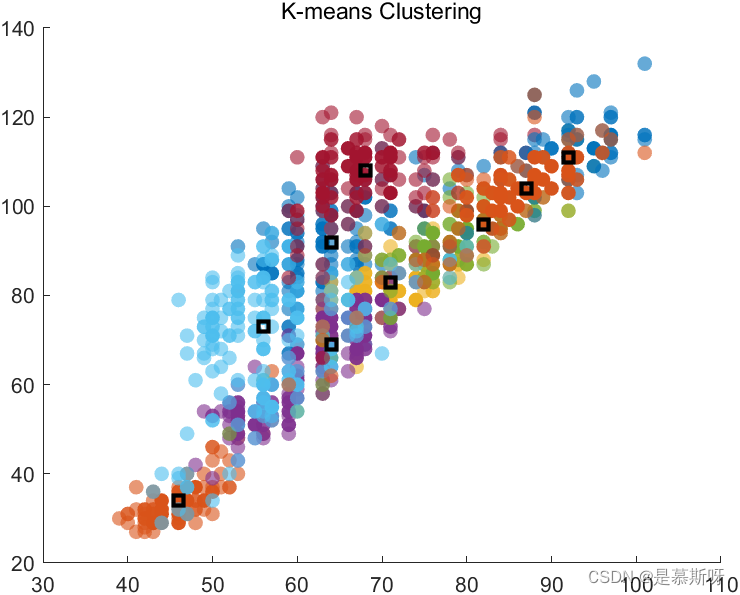
K = 9时
六、关键代码
clc;clear;close;
data = xlsread('D:\hw3-sat\satimage-data.xls');
data = data(:,1:36);
k = 3;
maxIterations = 100; % 最大迭代次数
[index_km,centroids] = kmeans(data,k,'Distance','cityblock','Start','plus','MaxIter', maxIterations);
uniqueLabels = unique(index_km);
C = cell(1,length(uniqueLabels));
for i = 1:length(uniqueLabels)
C(1,i) = {find(index_km == uniqueLabels(i))};
end
for j = 1:k
data_get = data(C{1,j},:);
scatter(data_get(:, 1), data_get(:, 2), 50, 'filled','MarkerFaceAlpha',.6,'MarkerEdgeAlpha',.9);
hold on
end
plot(centroids(:,1),centroids(:,2),'ks','LineWidth',2);
hold on
sc_k = mean(silhouette(data,index_km));
title('K-means Clustering');七、总结
本实验通过设置簇的个数将satimage数据集分为多个类。通过结果可以看到K的设置,可能会导致产生不理想的聚类,比如当K=9时,簇与簇基本都混在了一起,区分度很低;当K=3时,簇与簇就区分的比较明显。
















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









