







复制链接,将正文的html转markdown
由于本人十分的效率低下,有时候免不了有人催更哈
众所周知,懒是人们创新的动力
所以我就写了个抄袭爬虫脚本,把我看的觉得不错的文章,就直接爬过来,然后用微信公众号的格式给大家分享一下~
(主要是有些文章虽然含金量高,但是长得丑啊,就跟你我一样)
当然,分享的内容我不会标注原创,就当是我个人的收藏夹了,也会注明转载链接的
作用
将常规的博客,通过爬虫和字符处理,转换成markdown格式的文本
网上其实有类似工具,包括较为有名的
python的第三方库html2text,也或多或少都有些问题,试用了一下,http://www.atoolbox.net/Tool.php?Id=715最准确吧
所以自己写了一个
用法
python3 blog2md.py
输入想要抄袭收藏的链接以后
然后在终端会输出转换成md格式的结果,同时在相同目录下,会生成blog.md
演示
-
爬取内容是我上一篇原创文章的内容:
Python爬虫–自动获取参考链接的标题–转为markdown格式
-
控制台输出
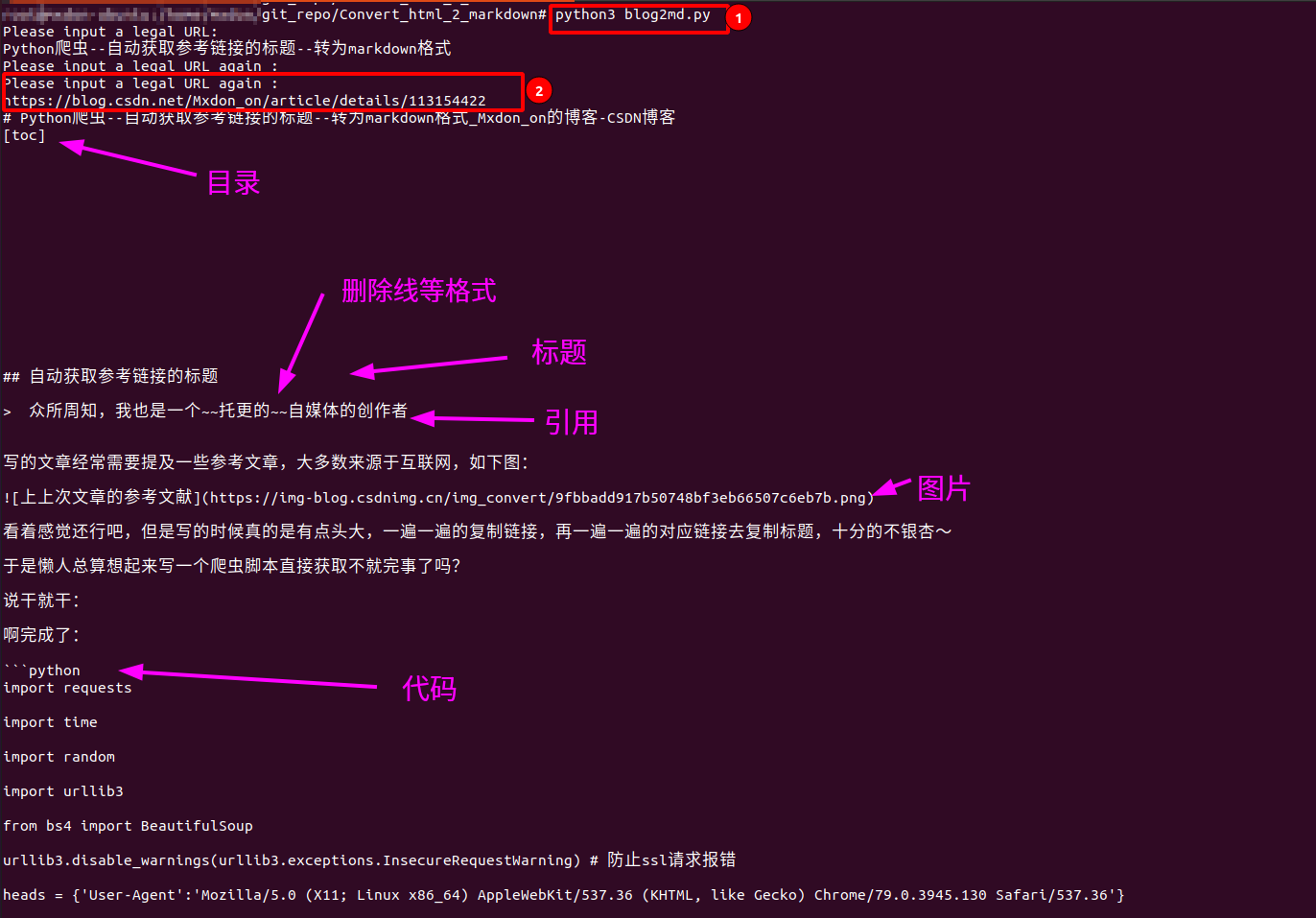
可以看到,该有的格式基本都完成了
- 文件预览
[@path/to/blog2md.py] $ ls
blog2md.py blog.md
此时在相同目录下已经生成了blog.md文件,我们打开一下预览看看效果
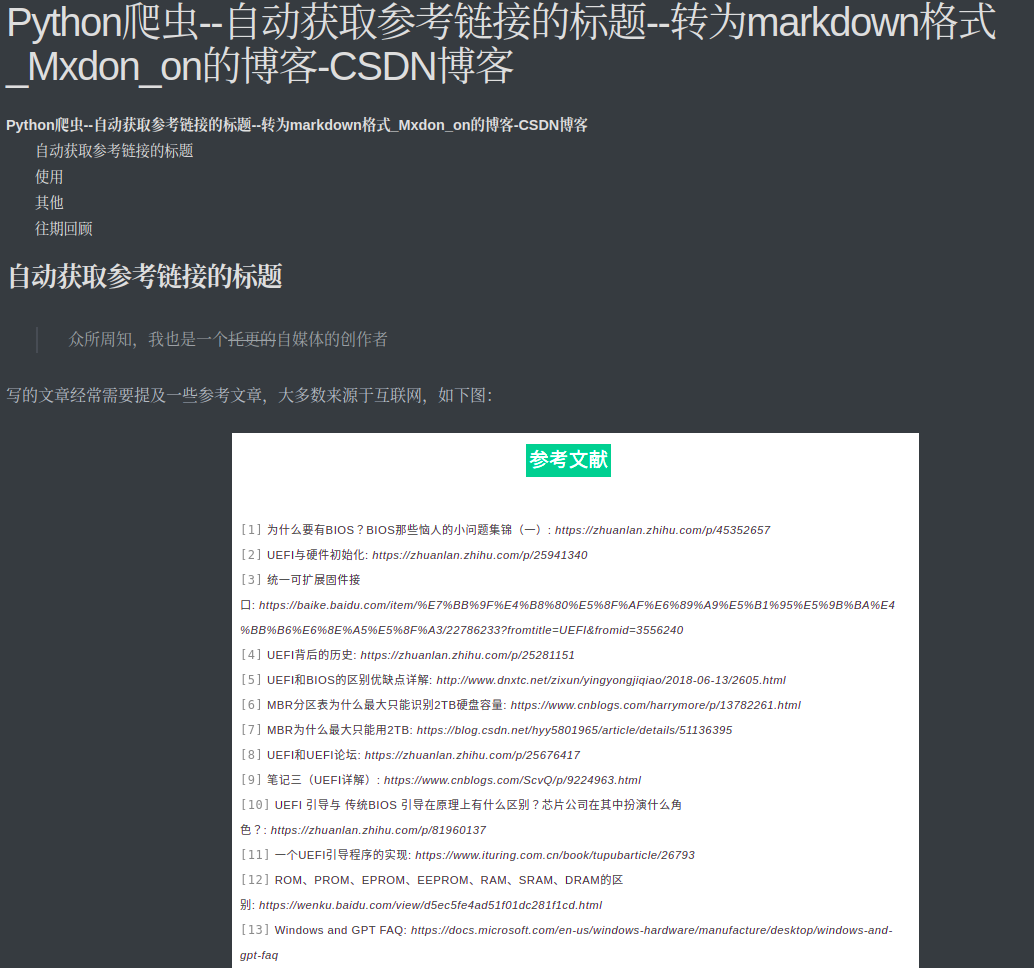
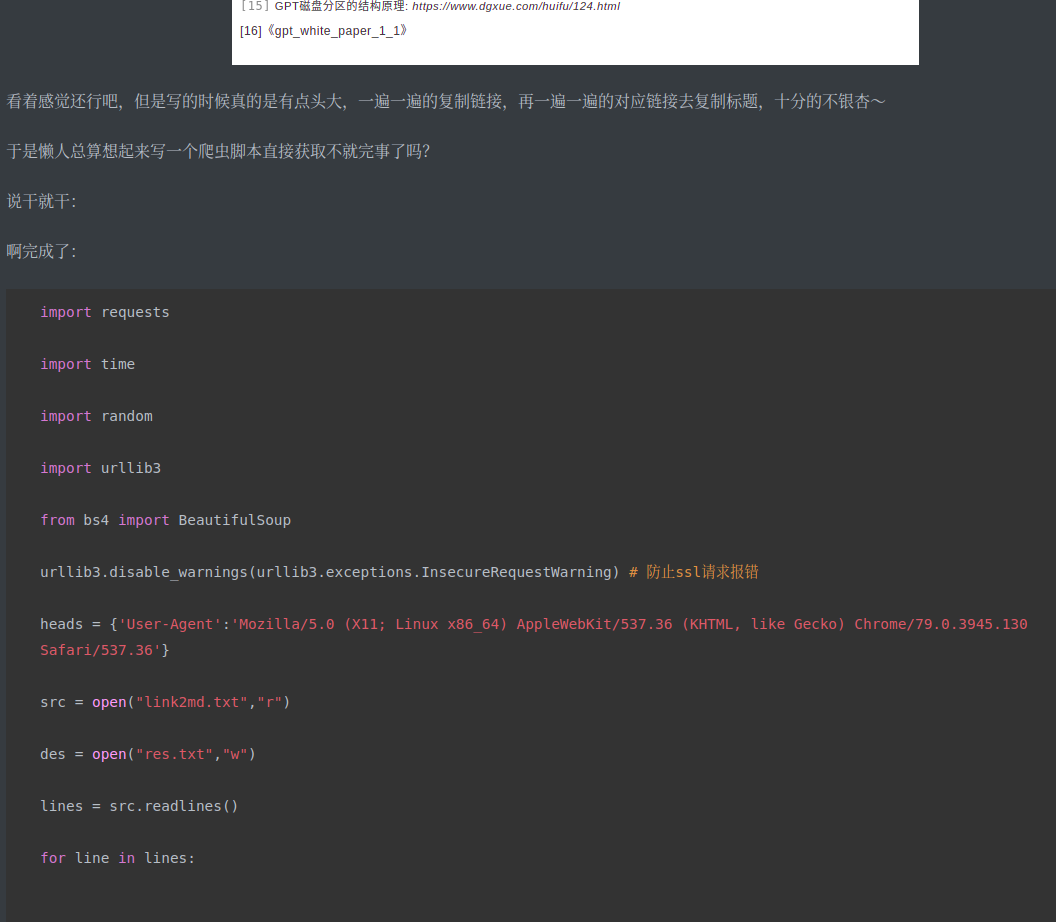
和我自己写的原版一毛一样
已完成功能
- 解决粗体、删除线、斜体等文字
markdown样式 - 解决图片和链接的
markdown显示 - 解决多级标题与网页标题的取舍,以及目录的
toc加入 - 解决行内代码和嵌入在文章的块代码显示的冲突,支持不同语言的块内代码
- 支持知乎文章、
csdn文章、简书和博客园文章,其他的尚未测试 - 支持命令行交互模式
TODO
- 多级引用尚未测试,由不同的
markdown渲染工具决定,会有问题 - 块内代码在一些离谱的格式下会有一点问题,不过暂时不影响使用
- 不支持公式
- 没有封装成图形化
- 多级列表也有一点问题
- 一些网站的图片不支持引用,如CSDN的部分图片,可能需要先解码才可以
- 应该把最终生成的文档,按照标题的名字来重新生成文件,啊就一行代码的事,不想搞了,够我自己用了
- 有些神奇的
空div标签就离谱,一个标签就近百行,然后处理起来也会有点问题,好在情况不多,直接删吧先 - 不支持表格
- 开头会有一些空格,还没整
不过不支持的项,直接用
html标签就可以啦~反正markdown也还是渲染成html
代码
感觉这玩意可能有点用,所以扔在gitee了,有需要的可以改改,然后一起用呀
链接:https://gitee.com/mxdon/funny_repo/tree/master/Convert_html_2_markdown
不过还是放一下源码,不要嫌篇幅长哈(看不全可以左右滑动):
# get title from title
# get content from article
# finish requests while article
# difficult @ filter out the correct content from so many <p>...</p>
# and format different content.
import re
import requests
import time
import random
import urllib3
from bs4 import BeautifulSoup
#def getimg(link):
def run(filename,textString):
src = open(filename,'a')
# Solved
# 1. bold
# 2. img and figcaption
# 3. title and contents
# 4. italics
# 5. code
# 6. nonsense tags
# 7. quote ### multi_quote TODO
# 8. delete
# 9. toc
# 10.link
# 11.p
# 12.add toc
# 13.formula ### TODO
toc_flag = 0
i = 0
l = '- '
quote_flag = 0
code_flag = 0
title_flag = 0
#for line in src.readlines():
for line in textString.split('\n'):
if len(line) ==0:
continue
templine = line
#### replace figcaption
if re.search('</?(?<=figcaption)[^<]*>',templine):
continue
#### replace [toc]
if re.search('(?<=<div)[^<]+?(?=toc)[^<]+?>',templine):
toc_flag = toc_flag + 1
elif re.search('</div>',line):
toc_flag = toc_flag - 1
if toc_flag:
continue
templine = re.sub('<code\s[^<]*inline[^<]*>', '<code>', templine)
code_inline = re.search('(?<=<code>).*(?=</code>)',templine)
if code_inline:
#print('===========' + str(code_inline.group()))
templine = re.sub('</?code>', '`', templine)
if re.search('<code\s[^<]+?>',templine):
code_flag = 1
codetype = re.search('(?<=language-)([^\"]+?)(?=\")',templine)
if codetype:
#titlelevel = re.search('(?<=<h)([0-9])(?=[^<]+?>$)',templine)
#print(titlelevel.group())
#print(codetype.group())
templine = re.sub('<code\s[^<]+?>','```'+str(codetype.group())+"\n",templine).strip()
else:
templine = re.sub('<code\s[^<]+?>','```\n',templine).strip()
templine = re.sub('</?code>','\n```',templine).strip()
#### replace image
try:
full_img = re.search('(?<=<img).*(?=/>)',templine)
#print(full_img.group())
img_name_group = re.search('(?<=alt=\")[^\"]+?(?=\")',str(full_img.group()))
img_group = re.search('(?<=src=\")([^\"]+?)(?=\")',str(full_img.group()))
#print(img.group())
#print(img_name.group())
img_name = str(img_name_group.group())
img = str(img_group.group())
if len(img_name) <= 1 or img_name.startswith('im'):
img_name = ''
else:
img_name = str(img_name_group.group())
templine = re.sub('<img[^<]+?/>','\n+')\n',templine).strip()
except:
templine = re.sub('<img[^<]+?/>','![load img faild]()',templine).strip()
#templine = re.sub('<img[^<]+?/>','+')',templine).strip()
#### replace bold
templine = re.sub('</?strong[^<]*>','**',templine).strip()
templine = re.sub('</?(b>|b\s[^<]*>)','**',templine).strip() # conflict with blockquote
templine = re.sub('</?em[^<]*>','**',templine).strip()
#### replace italics
templine = re.sub('</?i[^<]*>','*',templine).strip()
#### replace delete
templine = re.sub('</?del[^<]*>','~~',templine).strip()
templine = re.sub('</?s>','~~',templine).strip()
#### replace list
#if re.search('<ol[^<]*>',templine):
# i = 1
#elif re.search('</ol[^<]*>',templine):
# i = 0
# l = '- '
if i != 0:
if re.search('<li>',templine):
l = str(i) + '. '
templine = re.sub('<li>',str(i) + '. ',templine).strip()
i = i + 1
templine = re.sub('<li>',l,templine).strip()
templine = re.sub('</li>','\n',templine).strip()
#### replace link
try:
full_link_group = re.search('(?<=<a)[^<]+?(?=href)[^<]+?(?=</a>)',templine)
full_link = str(full_link_group.group())
link_href_group = re.search('(?<=href=\").*(?=\")',full_link)
link_href = str(link_href_group.group())
#print(link_href)
link_text_group = re.search('(?<=>).*',full_link)
link_text = str(link_text_group.group())
#print(link_text)
templine = re.sub('<a[^>]+?>.*</a>','['+link_text+']('+link_href+')',templine).strip()
except:
templine = templine
#### replace p
#lineval = re.sub('<p[^<]*>','',templine).strip()
#if re.search('</p[^<]*>',templine):
#print("")
templine = re.sub('<p[^<]*>','',templine).strip()
templine = re.sub('</p[^<]*>','\n',templine).strip()+'\n'
#### 1. replace quote
if re.search('<blockquote[^<]*>',templine):
quote_flag = quote_flag + 1
print("> ",end="")
#templine = re.sub('<blockquote[^<]*>', '> ', templine).strip()
templine = re.sub('<blockquote[^<]*>', '', templine).strip()
src.write('> ')
elif re.search('</blockquote[^<]*>',templine):
quote_flag = quote_flag - 1
templine = re.sub('</blockquote[^<]*>', '', templine).strip()
if quote_flag:
print(templine,end=" ")
src.write(templine)
continue
#### replace different level title
#templine = re.sub('<h1[^<]*>','# ',templine).strip()
templine = re.sub('<h1[^<]*>','## ',templine).strip()
templine = re.sub('<h2[^<]*>','## ',templine).strip()
templine = re.sub('<h3[^<]*>','### ',templine).strip()
templine = re.sub('<h4[^<]*>','#### ',templine).strip()
templine = re.sub('<h5[^<]*>','##### ',templine).strip()
templine = re.sub('<h6[^<]*>','###### ',templine).strip()
templine = re.sub('</h[0-9].*>','',templine).strip()
if re.search('</?title[^<]*>',templine):
templine = re.sub('</?title[^<]*>','',templine).strip()
#### replace all tags
templine = re.sub('<[^<]+?>', '', templine).strip()
print('# '+templine+'\n[toc]\n')
src.write('# '+templine+'\n[toc]\n')
continue
#### replace all tags
templine = re.sub('</?code>', '`', templine).strip()
templine = re.sub('<[^<]+?>', '', templine).strip()
lineval = templine + '\n'
print(lineval)
if len(lineval) == 0:
continue
else:
src.write(lineval+'\n')
src.close()
if __name__ == '__main__':
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
heads = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
des = open("blog.md","w")
des.write('')
des.close()
#des = open('blog.md','a')
url = input("Please input a legal URL: ")
while not url.startswith('http'):
url = input("Please input a legal URL again : \n")
try:
res = requests.get(url,timeout=30,headers=heads,verify=False)
res.encoding = 'UTF-8'
content = res.text
#print(content)
soup = BeautifulSoup(content,'html.parser')
if 'zhihu.com' in url:
temp_article = soup.find('div',class_='Post-RichTextContainer')
elif 'csdn.net' in url:
temp_article = soup.article
elif 'cnblogs.com' in url:
temp_article = soup.find('div',class_='markdown-here-wrapper')
article = str(temp_article)
except:
print("request error")
exit(1)
try:
title = soup.find('title')
target_head = str(soup.title)
#print("%s\n" % ("# "+title.text+"\n"+"[toc]"))
#title_text = '# '+title.text+'\n[toc]\n'
#des.write("# "+title.text+"\n"+"[toc]\n")
except:
print("===== title not found =====")
h1 = soup.find('h1')
target_head = str(soup.h1)
#print("%s\n" % ("#"+h1.text+"\n"+"[toc]"))
#des.write("# "+h1.text+"\n"+"[toc]\n")
#run(article)
target_text = target_head + article
#print(target_text)
#des.write(article)
#des.close()
run('blog.md',target_text)
#run('blog.md')















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









