






刚写完这个实验作业,顺便来记录一下一些易错的地方:
项目框图:

一、页面预览
先从歌手页爬取到这首歌的相关信息,包括它歌曲、专辑的url。这里要说一下,刚开始在歌曲详情页、播放器页面找了很久都找不到爬取歌曲时长的地方,结果!当我打开歌手页的时候,发现:

这不明摆着的吗???
所以呀,在爬虫之前,一定要先对相关页面有足够的了解!
上面的内容直接用Beautiful Soup4 数据解析就能搜集到。
二、其他信息
歌词:进入详情页爬取
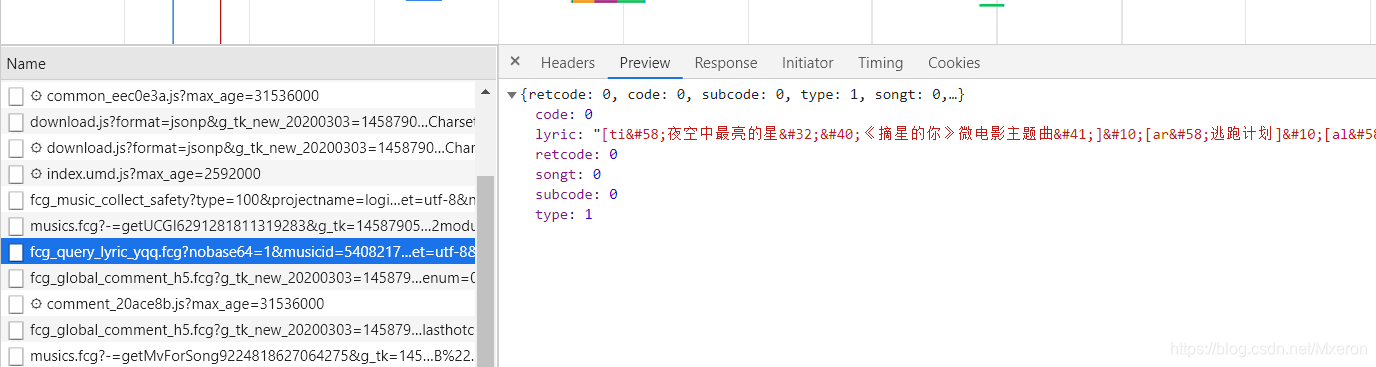

通过抓包,发现是个ajax请求,点开注意一下url和请求方式、返回数据类型即可。
注意:这里有个问题困扰了很久!!
你会发现对歌词的url进行请求时:
new_url='https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg?nobase64=1&musicid=5408217&-=jsonp1&g_tk_new_20200303=1458790511&g_tk=1458790511&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
如果你只添加了headers,它是不会返回正确的数据的(会告诉你请求失败),这是为什么呢?
我在网上搜索后发现,原来是存在反爬虫,需要再添加referer!
Referer是HTTP请求Header的一部分,当浏览器向Web服务器发送请求的时候,请求头信息一般需要包含Referer。该Referer会告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。
Referer作用是什么?
1)防盗链
比如办事通服务器只允许网站访问自己的静态资源,那服务器每次都需要判断Referer的值是否是zwfw.yn.gov.cn,如果是就继续访问,不是就拦截。
2)防止恶意请求
比如静态请求是.html结尾的,动态请求是.shtml,那么所有的*.shtml请求,必须 Referer为我自己的网站才可以访问,这就是Referer的作用。
(有些网站没有Referer直接写一个UA伪装就可以获取数据)
正确书写形式:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.82 Safari/537.36',
'Referer': 'https://y.qq.com/n/yqq/song/001NmPTG1fVsUw.html'
}
Referer填写的就是你要访问(请求的)那个网页,或者是包含你想发送请求内容的那个页面。
举个例子:
我们想要获取歌词,歌词在:
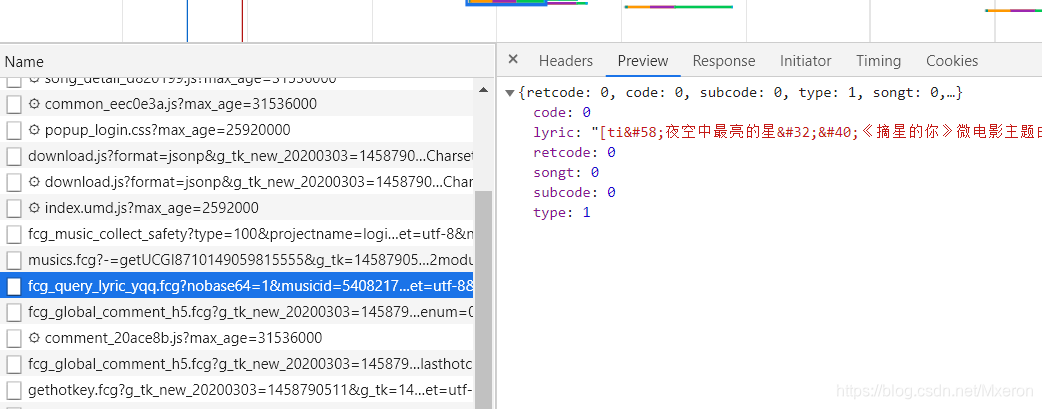
这个页面的蓝色标识的url中,我们想对这个蓝标的url发送请求时,就必须加上Referer:https://y.qq.com/n/yqq/song/001NmPTG1fVsUw.html,加上后就可以正常请求数据了。
评论:
点击之后都是局部网页刷新,所以直接抓包找xhr即可。
注意:
刚开始进去的页面,如果你不点第二页或者加载更多,它只有一个这个:
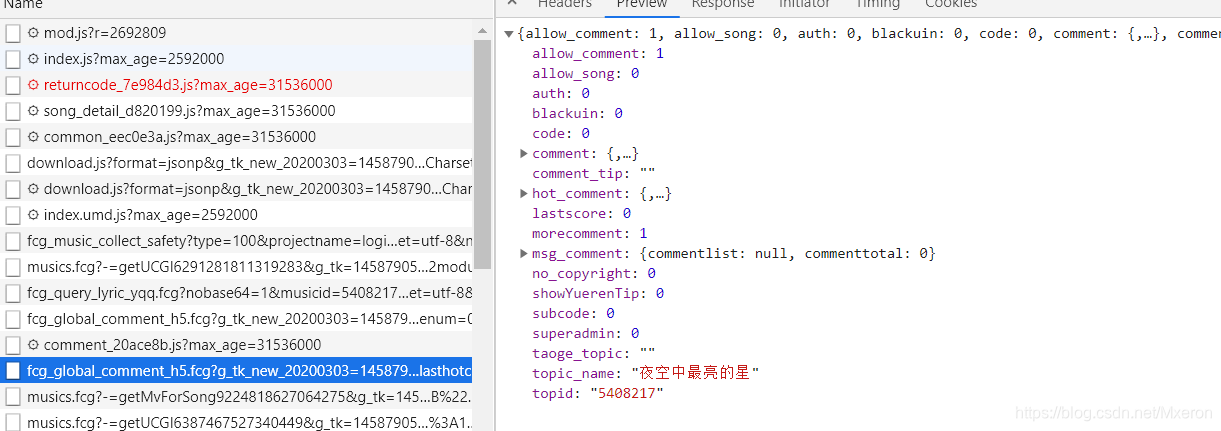
可以看到里面包含了热门评论、普通评论,但很明显这并不方便我们爬取数据,所以再我点击之后发现,果然又多了几个xhr:
这个是最新评论:
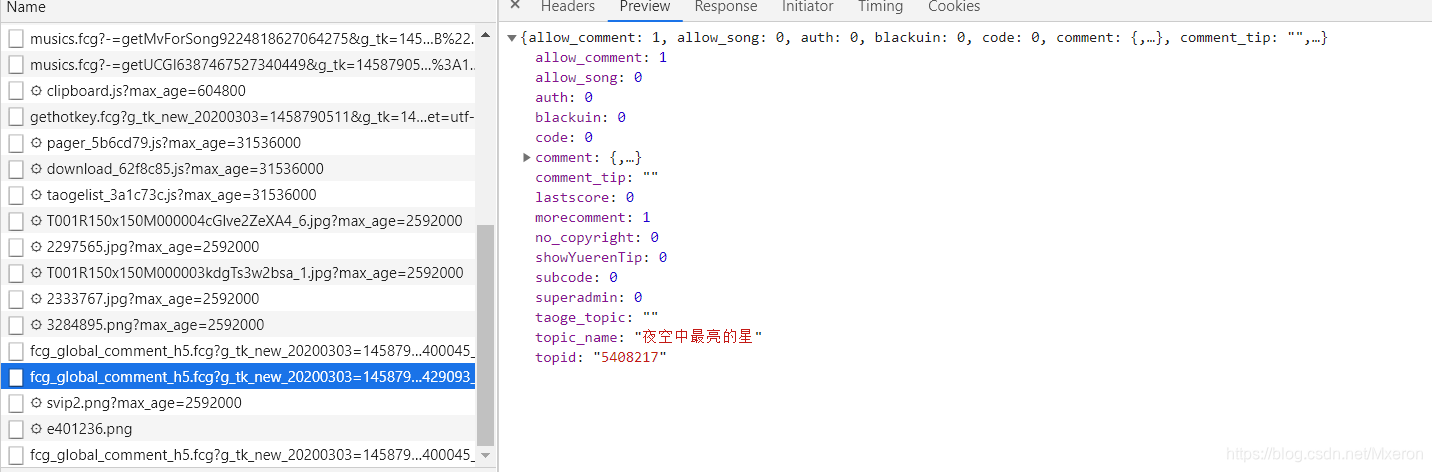
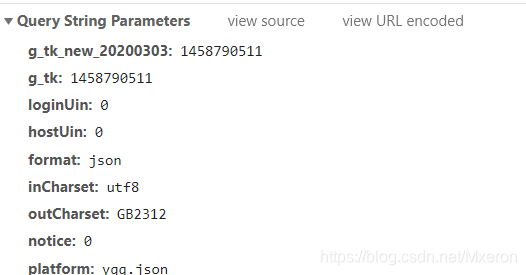
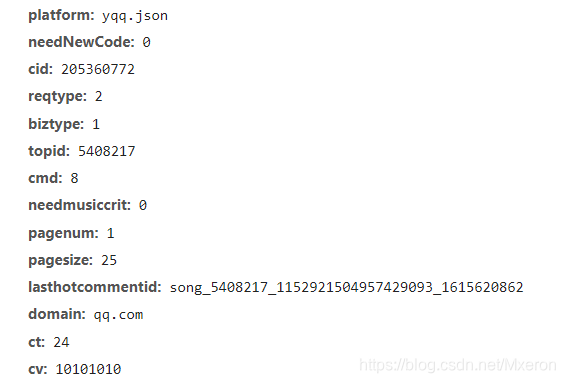
这里同样需要注意一下请求方式和返回数据类型,更重要的是查看它需要的参数!!(用于遍历获取更多的评论),这里最重要的就是pagenum和pagesize(顾名思义)。
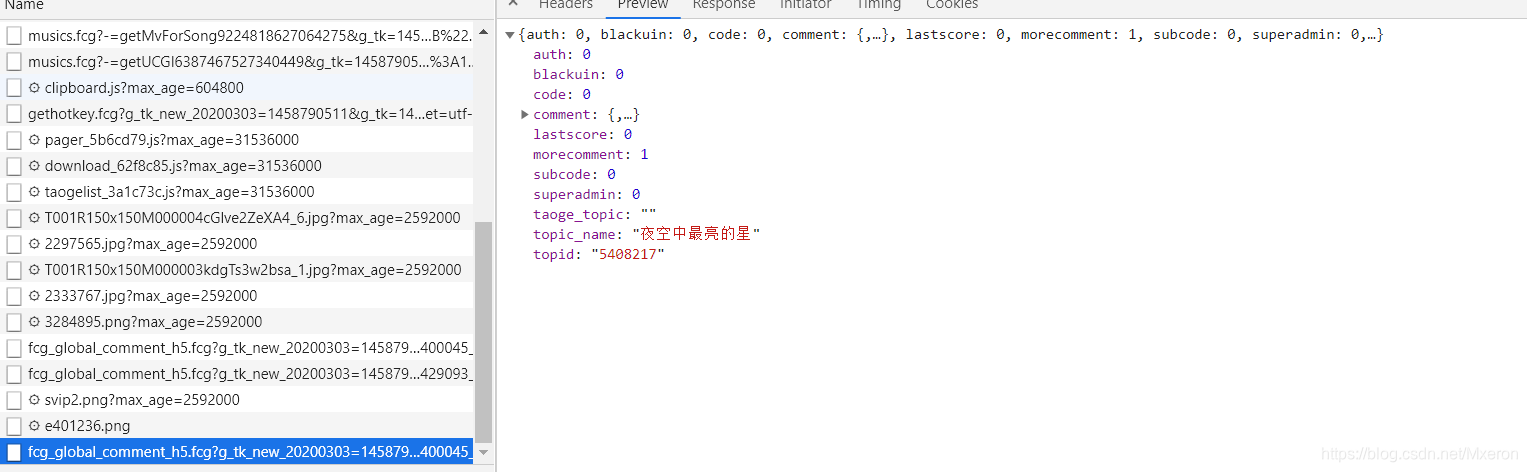
这个是热门评论,跟上面获取最新评论一样。
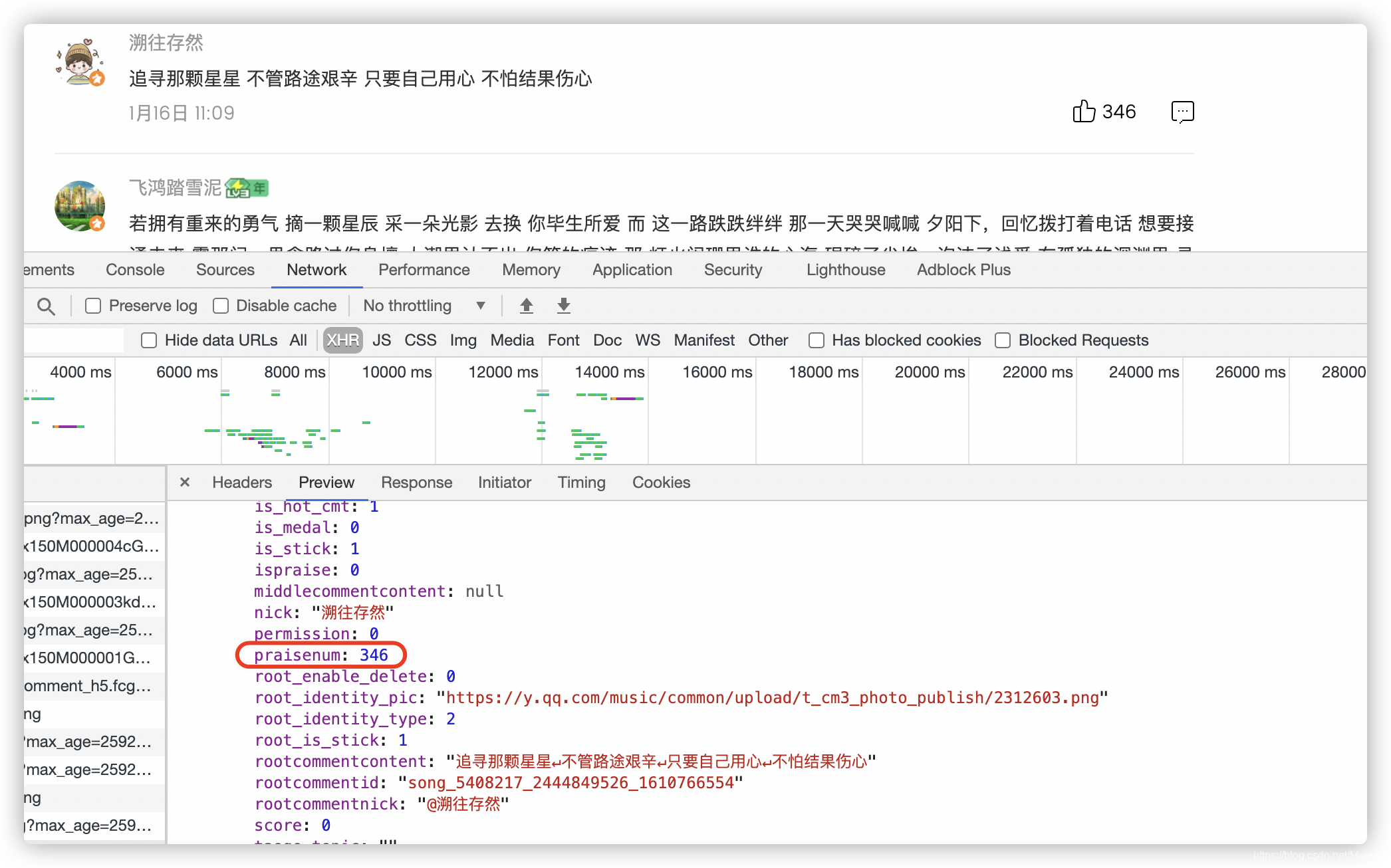
下面显示的是点赞数的获取:
三、一些小细节
1、字典的读取
total_Dict['评论Id'].append(i.get('commentid', 'NULL'))
在获取字典中的信息时,最好这么写,因为你不知道里面到底有没有数据。
2、用字典存储数据时,要先对键进行初始化,之后再用.append加入值(实现一键多值)。
total_Dict={'评论Id':[],'发布时间':[],'用户名':[],'评论内容':[]}
3、10位秒级,要把这个时间转换成我们方便看的时间:
# 要将10位秒时间转成正常形式
tupTime = time.localtime(int(i.get('time')))
temp_time = time.strftime('%Y-%m-%d %H:%M:%S', tupTime)
4、编码形式,最好用utf_8_sig,如果用gbk可能有些特殊符号无法解码,导致报错,用utf-8中文会乱码。

total_Dict.to_csv('最新评论.csv',encoding='utf_8_sig')
5、多协程队列爬虫:
主要部分:
monkey.patch_all()(帮助程序实现异步,要放在最前面)
work=Queue()
work.put_nowait()(将数据放入队列)
while not work.empty()(如果队列不为空继续循环)
work.get_nowait() (获取队列中信息)
# 创建空任务列表
task_list = []
# 这里代表使用多少个协程(开的越多速度越快,并且能够很好地支持高并发)
for k in range(3):
# 用gevent.spawn()函数创建执行get_info()函数的任务
task = gevent.spawn(get_info)
# 往任务列表添加任务
task_list.append(task)
# 用gevent.joinall方法,执行任务列表里的所有任务,就是让爬虫开始爬取网站
gevent.joinall(task_list)
6、html编码
在获取歌词时:

发现有一些类似&#的不明编码,处理方式:
1、正则表达式提取内容
2、html.unescape()
import HTMLParser
music_lyric=html.unescape(music_lyric)
四、源码
from gevent import monkey
monkey.patch_all()
# patch_all()能把程序变成协作式运行,帮助程序实现异步,需要放在最前面
# 利用协程和队列加快爬虫速度
# 上面两个语句必须放在最上面(不然会有Warning)
from gevent.queue import Queue
import gevent
import requests
from bs4 import BeautifulSoup
import html
import time
import pandas as pd
if __name__ == '__main__':
def getMusicInfo():
# 对url进行请求
# 歌曲地址
url = 'https://y.qq.com/n/yqq/singer/001Yxpxc0OaUUX.html#stat=y_new.song.header.singername'
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.82 Safari/537.36'
}
response = requests.get(url=url, headers=headers).text
# 歌曲名、所属专辑、播放时长、播放链接、歌词、评论(日期、内容、点赞数量)
# 使用Beautiful Soup进行 数据解析
# 先实例化
soup = BeautifulSoup(response, 'lxml')
# 先找到大致范围
temp = soup.find('li', mid=5408217)
# 再根据要求缩小范围
song_name = temp.select('div .songlist__songname span a')[0]
song_album = temp.select('div .songlist__album a')[0]
# 获取到了音乐播放链接、歌曲名、所属专辑连接、专辑名
music_url = 'https:' + song_name['href']
music_name = song_name['title']
music_length = temp.select('div .songlist__time')[0].text
album_url = 'https:' + song_album['href']
album_name = song_album['title']
# 再对详情页进行请求
new_url = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg?nobase64=1&musicid=5408217&-=jsonp1&g_tk_new_20200303=1458790511&g_tk=1458790511&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
# 这里要加上Referer(破解反爬)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.82 Safari/537.36',
'Referer': 'https://y.qq.com/n/yqq/song/001NmPTG1fVsUw.html'
}
new_response = requests.get(url=new_url, headers=headers).json()
music_lyric = new_response['lyric']
# 将提取到的歌词内容进行html转义
music_lyric = html.unescape(music_lyric)
# 将歌词存入txt文件
with open('music_lytic.txt', 'w', encoding='gbk') as fp:
fp.write(music_lyric)
musicDF = pd.DataFrame(columns=['歌曲名', '歌曲长度', '所属专辑名', '歌曲链接', '专辑链接'],
data=([[music_name, music_length, album_name, music_url, album_url]]))
print(musicDF)
# 转换成csv格式
musicDF.to_csv('歌曲介绍.csv', encoding='gbk')
# 提取评论(精彩和最新)
# 精彩评论和最新评论区别在于参数不同!
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.82 Safari/537.36'
}
def getAmazedComment():
comment_url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
# 创建队列对象
work = Queue()
for i in range(0, 20):
amazedParams = {
'g_tk_new_20200303': '1458790511',
'g_tk': '1458790511',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'GB2312',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
'cid': '205360772',
'reqtype': '2',
'biztype': '1',
'topid': '5408217',
'cmd': '6',
'needmusiccrit': '0',
'pagenum': i, # 这里代表第几页(作为我们的参数)
'pagesize': '20', # 这里代表每页显示多少内容
'lasthotcommentid': 'song_5408217_2512400045_1484758075',
'domain': 'qq.com',
'ct': '24',
'cv': '10101010'
}
# 放入work队列中
work.put_nowait(amazedParams)
total_Dict = {'评论Id': [], '发布时间': [], '用户名': [], '评论内容': [], '点赞数': []}
def getInfo():
# 这里一共提取了 20*20=400条评论
while not work.empty():
# 精彩评论提取和存储
params = work.get_nowait()
amazedComment_response = requests.get(url=comment_url, params=params, headers=headers).json()
amazedComment_list = amazedComment_response['comment']['commentlist']
for i in amazedComment_list:
# 这里最好使用dict.get()方法,避免某项数据为空时报错
total_Dict['评论Id'].append(i.get('commentid', 'NULL'))
total_Dict['点赞数'].append(i.get('praisenum', 'NULL'))
if i.get('time', 'NULL') != 'NULL':
# 要将10位秒时间转成正常形式
tupTime = time.localtime(int(i.get('time')))
temp_time = time.strftime('%Y-%m-%d %H:%M:%S', tupTime)
total_Dict['发布时间'].append(temp_time)
else:
total_Dict['发布时间'].append('NULL')
total_Dict['用户名'].append(i.get('nick', 'NULL'))
total_Dict['评论内容'].append(i.get('rootcommentcontent', 'NULL'))
# 创建空任务列表
task_list = []
# 这里代表使用多少个协程(开的越多速度越快,并且能够很好地支持高并发)
# 速度还会受很多因素限制
for i in range(3):
# 使用gevent.spawn来让普通函数成为gevent任务
task = gevent.spawn(getInfo())
task_list.append(task)
# 执行任务列表中的所有任务(开始爬取网站)
gevent.joinall(task_list)
print('获取热门评论完成!')
total_Dict = pd.DataFrame(total_Dict)
print(total_Dict)
# 转换成csv格式
total_Dict.to_csv('热门评论.csv', encoding='gbk')
# 获取最新评论
def getNewcomment():
comment_url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
# 创建队列对象
work = Queue()
for i in range(0, 20):
newParams = {
'g_tk_new_20200303': '1458790511',
'g_tk': '1458790511',
'loginUin': '0',
'hostUin': '0',
'format': 'json',
'inCharset': 'utf8',
'outCharset': 'GB2312',
'notice': '0',
'platform': 'yqq.json',
'needNewCode': '0',
'cid': '205360772',
'reqtype': '2',
'biztype': '1',
'topid': '5408217',
'cmd': '8',
'needmusiccrit': '0',
'pagenum': i,
'pagesize': '25',
'lasthotcommentid': 'song_5408217_2631124132_1615512647',
'domain': 'qq.com',
'ct': '24',
'cv': '10101010'
}
# 放入work队列中
work.put_nowait(newParams)
total_Dict = {'评论Id': [], '发布时间': [], '用户名': [], '评论内容': [], '点赞数': []}
def getInfo():
# 这里一共提取了 20*25=500条评论
while not work.empty():
# 精彩评论提取和存储
params = work.get_nowait()
amazedComment_response = requests.get(url=comment_url, params=params, headers=headers).json()
amazedComment_list = amazedComment_response['comment']['commentlist']
for i in amazedComment_list:
total_Dict['评论Id'].append(i.get('commentid', 'NULL'))
total_Dict['点赞数'].append(i.get('praisenum', 'NULL'))
if i.get('time', 'NULL') != 'NULL':
# 要将10位秒时间转成正常形式
tupTime = time.localtime(int(i.get('time')))
temp_time = time.strftime('%Y-%m-%d %H:%M:%S', tupTime)
total_Dict['发布时间'].append(temp_time)
else:
total_Dict['发布时间'].append('NULL')
total_Dict['用户名'].append(i.get('nick', 'NULL'))
total_Dict['评论内容'].append(i.get('rootcommentcontent', 'NULL'))
# 创建空任务列表
task_list = []
# 这里代表使用多少个协程(开的越多速度越快,并且能够很好地支持高并发)
# 速度还会受很多因素限制
for i in range(3):
# 使用gevent.spawn来让普通函数成为gevent任务
task = gevent.spawn(getInfo())
task_list.append(task)
# 执行任务列表中的所有任务(开始爬取网站)
gevent.joinall(task_list)
print('获取最新评论完成!')
total_Dict = pd.DataFrame(total_Dict)
print(total_Dict)
# 转换成csv格式
# 这里不能用gbk编码,会报错,用utf_8_sig是比较保守的!(utf-8会中文乱码)
total_Dict.to_csv('最新评论.csv', encoding='utf_8_sig')
# 测试
getMusicInfo()
getAmazedComment()
getNewcomment()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











