







 本文详细阐述了JVM的基础知识,包括类加载器的工作原理、类加载过程、垃圾回收机制中的新生代、老年代和永久代、不同垃圾回收算法以及主流垃圾回收器如Serial+SerialOld、ParallelScavenge+ParallelOld、ParNew+CMS和G1的特性。
本文详细阐述了JVM的基础知识,包括类加载器的工作原理、类加载过程、垃圾回收机制中的新生代、老年代和永久代、不同垃圾回收算法以及主流垃圾回收器如Serial+SerialOld、ParallelScavenge+ParallelOld、ParNew+CMS和G1的特性。
JVM相关基础知识
一、JVM基础
1、java从编译到执行
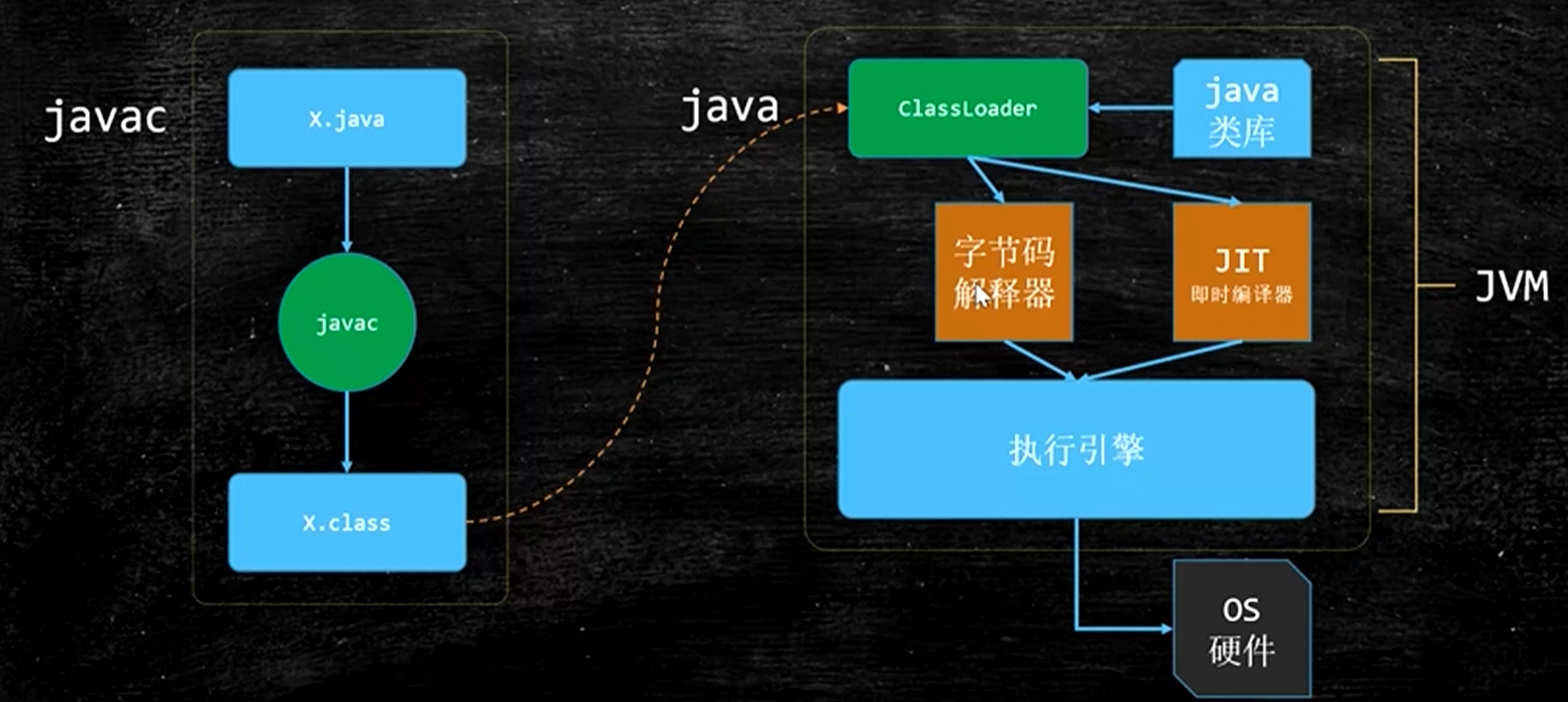
- 一个x.java文件通过执行javac变为x.class文件,然后被ClassLoader加载到内存中,通过java类库中的一部分类(如:Object,String等)也会被加载到内存中。
- Java即是编译型的,也是解释型语言,即混合型语言。常用代码会被JIT即时编译,提高效率。总的来说Java更接近解释型语言。
- Java是跨平台语言,JVM是跨语言平台(只要是.class文件就能执行)。
- JDK是Java开发工具包;JRE是Java运行环境;JVM是Java虚拟机。JDK包含JRE,JRE包含JVM。
二、类加载器
1、类的加载
1.1 类加载过程
loading (加载) —> linking(验证 —> 准备 —> 解析) —> initializing(初始化)
- 加载:将java文件编译成class文件。
- 验证:校验class文件是否符合class文件的规范。
- 准备:为静态变量分配空间,则在此阶段分配
默认值。 - 解析:将常量池中的符号引用替换为直接引用的过程。(有一部分符号引用会在使用时转换为直接引用)
- 初始化:执行初始化方法的过程。加载静态代码块,为静态成员变量分配
初始值等。
1.2 什么情况下会对类进行初始化?
- jvm执行new指令时。
- 初始化一个类,但其父类未被初始化时,会优先初始化父类。
- 虚拟机启动时,用户需要定义一个执行的主类即main()方法,会优先初始化此类。
- 首次访问此类的静态变量或者静态方法时
- 使用java.lang.reflect包下的方法进行反射调用如Class.forName()方法等
1.3 new 一个对象的过程是怎样的?
如:T t = new T();
- 类的加载
- 申请内存(赋默认值)
- 调用构造方法(赋初始值)
- 指针指向内存(赋值给t)
这里需要注意,在没有volatile的情况下,3和4可能会发生指令重排序,即t先指向内存,后赋初始值。
可能会导致另一个线程拿到的值为默认值而非正确的初始化的值。(单例模式为什么要用volatile修饰)
2、双亲委派模型
2.1 模型组成
- 启动类加载器:c++实现
- 扩展类加载器
- 应用程序类加载器
- 自定义加载器

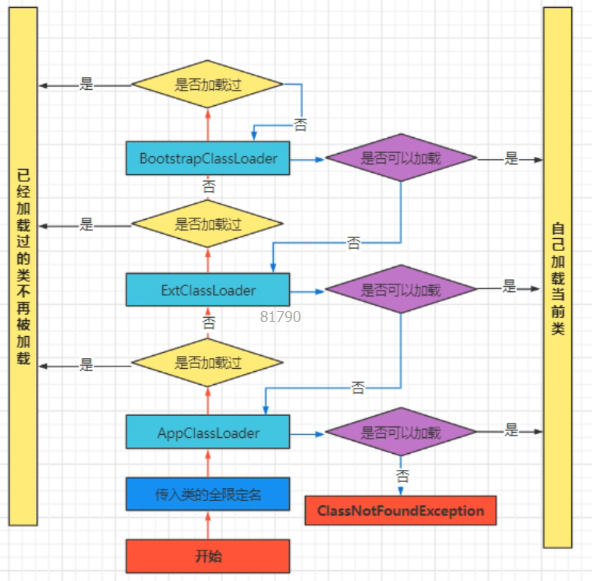
2.2 工作原理
当一个类需要被加载的时候,它不会直接执行类加载,而是先把这个请求委托给父类加载器,直到把这个请求传递到启动类加载器。如果父类加载器无法完成此次类加载,则会让其子类尝试执行类加载。
2.3 优点
- 避免类的重复加载。
避免Java的核心API被篡改。
2.4.类加载器的加载过程源码
在loadClass中,会通过类似递归的方式自底向上地检查父加载器是否已经加载此类,如果全部没有加载,则开始自顶向下地尝试加载。如果最终仍然加载失败,则抛出ClassNotFoundException。
// java.lang.ClassLoader
// 类加载过程源码
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// 校验类是否已经被加载
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
// 双亲委派,找父加载器去检查加载。即自底向上地检查。
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
}
if (c == null) {
// 上面没有从缓存中找到加载信息,只能自己加载。即自顶向下地尝试加载。
// 如果未被重写,该方法直接抛出ClassNotFoundException。
// 所以实现自定义类加载器的核心是重写此方法。
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
}
return c;
}
2.5 自定义类加载器的实现
- 继承ClassLoader,重写其findClass方法。
- 通过name构造文件绝对路径读取文件。
- 创建文件字节输入流。
- 创建字节数组输出流。
- 读取输入流,将数据写入到输出流。
- 将字节数组输出流装换成二进制字节数组。
- 调用ClassLoader的defineClass()方法用字节数组构造clazz对象。
public class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 这里通过入参 name 构造出文件的绝对路径来获取file。
File file = new File("");
try {
// 创建文件字节输入流
FileInputStream fileInputStream = new FileInputStream(file);
// 创建字节数组输出流
ByteArrayOutputStream byteArrayInputStream = new ByteArrayOutputStream();
int b;
while ((b = fileInputStream.read()) != 0) {
// 读取输入流,将数据写入到输出流
byteArrayInputStream.write(b);
}
// 将字节数组输出流装换成二进制字节数组
byte[] bytes = byteArrayInputStream.toByteArray();
byteArrayInputStream.close();
fileInputStream.close();
// 调用ClassLoader的defineClass()方法用字节数组构造clazz对象
return defineClass(name, bytes, 0, bytes.length);
} catch (Exception e) {
e.printStackTrace();
}
return super.findClass(name);
}
}
自定义类加载器的使用也非常简单,即反射。
public static void main(String[] args) throws Exception {
ClassLoader classLoader = new MyClassLoader();
Class clazz = classLoader.loadClass("");
Object o = clazz.newInstance();
}
2.6 懒加载
懒加载其实就是按需加载,即当对象需要用到的时候再去加载相关的对象。
三、JVM运行数据区
1、JVM运行数据区可分为:方法区、堆、本地方法栈、虚拟机栈和程序计数器。

- 方法区(Method Area):
线程共有,主要用于存放类文件信息,静态变量,常量以及即时编译(JIT)后的代码等数据。 - 堆(Heap):
线程共有,JVM中内存最大的一块, 主要用于存放对象实例,可分为新生代和老年代,是GC的主要区域。 - 虚拟机栈(JVM Stacks):
线程私有,主要存放栈帧。每个方法执行时都会在栈中创建一个栈帧,栈帧是由局部变量表、操作数栈、动态链接和返回地址组成。动态链接指动态将常量池中符号引用转化为直接引用。 - 本地方法栈(Native Method Stacks):
线程私有,专门为JVM调用C和C++编写的native方法服务。 - 程序计数器(Program Counter Register):
线程私有,用于保存当前正在执行的线程的字节码地址。因为线程不具备记忆功能,所以需要程序计数器告诉线程该执行哪一条字节码。
2、一些补充
2.1 介绍一下方法区
方法区并不真实存在,属于 Java 虚拟机规范中的一个逻辑概念,用于存储已被 JVM 加载的类信息、常量、静态变量、即时编译器编译后的代码缓存等。
在 HotSpot 虚拟机中,方法区的实现称为永久代(PermGen),但在 Java 8 及之后的版本中,已经被元空间(Metaspace)所替代,方法区的内存大小取决于系统内存的大小。
2.2 对象一定分配在堆中吗?
随着 JIT 编译期的发展与逃逸分析技术逐渐成熟,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。其实,在编译期间,JIT 会对代码做很多优化。其中有一部分优化的目的就是减少内存堆分配压力,其中一种重要的技术叫做逃逸分析。
逃逸分析(Escape Analysis)技术
编译器可能会将一些原本应该在堆上分配的对象优化为在栈上分配。这通常发生在对象的作用域明确并且不会逃逸出它的创建方法时。
逃逸分析的好处
-
栈上分配:如果确定一个对象不会逃逸到线程之外,那么久可以考虑将这个对象在栈上分配,对象占用的内存随着栈帧出栈而销毁,这样一来,垃圾收集的压力就降低很多。
-
同步消除:线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那么这个变量的读写肯定就不会有竞争, 对这个变量实施的同步措施也就可以安全地消除掉
四、垃圾回收机制
1、什么是新生代、老年代和永久代
1.1 新生代
主要用于存放新生的对象,占据堆内存的1/3。由于频繁创建对象,新生代会进行频繁的Minor GC。新生代分为三块区域:Eden、ServiceFrom和ServiceTo。
- Eden区:新创建的对象会被放入Eden区,如果对象过大则直接分配老年代。当Eden区内存不够时会触发Minor GC,而大多数对象都是朝生夕死,对于存活对象则是进入ServiceTo区或ServiceFrom区。
- ServiceTo:一次Minor GC后Eden区或ServiceFrom存活的对象会被复制到此区域。
- ServiceFrom:一次Minor GC后Eden区或ServiceTo存活的对象会被复制到此区域。
ServiceTo和ServerFrom区本质上没什么区别,循环使用于存放GC后存活的对象。每次存活后对象的年龄加1,年龄到达15后依然存活的对象会被分配到老年代。
Minor GC一般采用复制算法。
1.2 老年代
用于存放大对象或者存活时间很长的对象,占据堆内存的2/3。老年代的对象比较稳定,所以Major GC不会频繁执行。
进入老年代的方式有三种:
- 对象存活时间长,默认年龄为15。
- 对象很大。
- 动态年龄判断:按年龄从小到大将对象累加,如果加入某个年龄的对象后内存超过一半,则从该年龄开始,往上的年龄都进入老年代。
在对象进入老年代后,如果老年代空间不足,则会触发Major GC。如果老年满了装不下了,则会OOM。
Major GC一般采用标记清除或标记整理算法。
1.3 永久代
Java8后永久代被移除,被元空间(Meta Space)取代。
- 元空间不是方法区,而是方法区的一种实现。
- 元空间并不使用JVM的内存,而是使用操作系统的本地内存。
- 元空间主要用于存放Class信息以及元数据信息。
- 元空间不会触发GC。
2、如何对象是否存活
对象不存活就是垃圾。
-
引用计数法
一个对象,如果被引用则计数器加1,引用失效则计数器减1。 如果计数器值为0,则表示该对象不在被引用,可以进行回收。 但有一个致命缺点:无法处理循环依赖。导致没有任何地方使用此方式。 -
可达性分析法
以根对象(GC root)为起点,搜索被根对象集合所连接的目标对象是否可达。
可作为GC Roots 的对象有:
1、虚拟机栈里的变量。
2、方法区中的静态属性引用的对象。
3、方法区中的常量引用的对象。
4、native方法引用的对象。
3、有哪些GC
- MInor GC:新生代Eden区满时触发。
- Major GC:老年代内存满时触发。
- Full GC:清除整个堆空间,通常和Major GC等价。
4、垃圾回收算法
4.1 标记清除算法
- 概述:标记无用对象,然后进行清除回收。一共分为两个阶段:标记阶段和清除阶段,所以该算法需要扫描两次。
- 优点:实现简单,不需要对对象进行移动。
- 缺点:需要两次扫描;会产生内存碎片,提高了GC的频率。
- 使用:
多用于老年代。
4.2 复制算法:
- 概述:将内存划为两个相等的区域,每次只使用一个区域存放数据。垃圾回收时,将存活对象复制到另一个区域,然后将当前区域回收。
- 优点:无内存碎片;只扫描一次,效率高。
- 缺点:将可用内存缩小为原来的一半,并且在对象存活率高的时候会频繁进行GC。
- 使用:
多用于新生代。
4.3 标记整理算法
- 概述:在标记可回收的对象后将所有存活的对象压缩到内存的一端,然后对端边界以外的内存进行回收。需要两次扫描。
- 优点:不会存在内存碎片。
- 缺点:需要两次扫描,并且需要对对象进行移动,效率偏低。
- 使用:
多用于老年代。
4.4 分代算法
对新生代中的对象采用复制算法,对老年代的对象采用标记清除或标记整理算法。
五、垃圾回收器
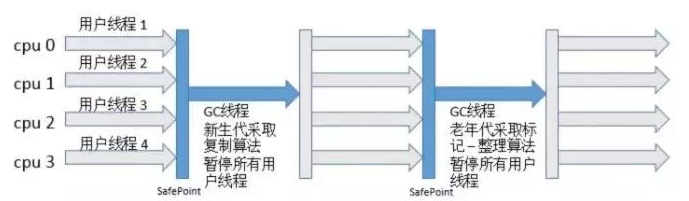
1、Serial + Serial Old
这是一组单线程垃圾回收器,并且GC线程在运行时会STW。
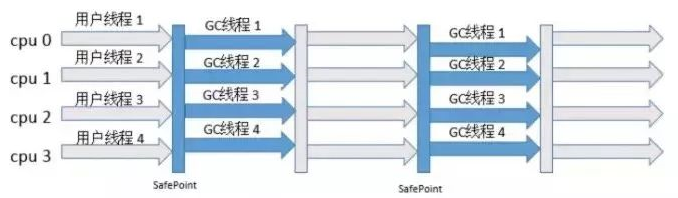
2、Parallel Scavenge + Parallel Old
相比于Serial + Serial Old垃圾收集器,PS+PO的组合优点在于可以通过多线程(默认为CPU数量)进行垃圾回收,但是PS+PO依然会STW。
3、ParNew + CMS
ParNew收集器就是PS收集器为了兼容CMS做了部分改进产生的。
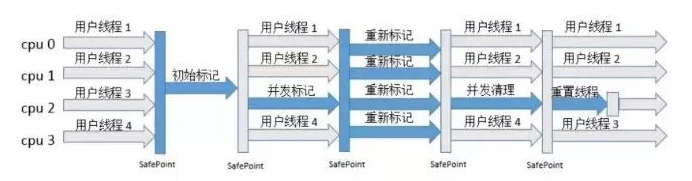
CMS 收集器是一种以最短回收停顿时间为目标的收集器,以 “ 最短用户线程停顿时间 ” 著称。整个垃圾收集过程分为 4 个步骤:
- 初始标记:标记一下 GC Roots 能直接关联到的对象,速度较快。
会STW。 - 并发标记:标记出全部的垃圾对象,并且此时用户线程依然在运行,所以会有新的垃圾产生。垃圾回收的绝大部分耗时都在此阶段。
- 重新标记:修正并发标记阶段因用户程序继续运行而导致垃圾对象的标记记录(可能不再是垃圾)。但并发标记产生的新垃圾无法处理,即产生浮动垃圾。
会STW。 - 并发清除:用标记-清除算法清除垃圾对象(所以CMS会产生内存碎片),可以和用户线程并发执行。
CMS收集器缺点:
- 对 CPU 资源敏感:默认分配的垃圾收集线程数为(CPU 数+3)/4,随着 CPU 数量下降,占用 CPU 资源越多,吞吐量越小。
- 无法处理浮动垃圾(Floating Garbage):由于存在浮动垃圾,并且在并发标记阶段用户线程也在并发执行,CMS 收集器不能像其他收集器那样等老年代被填满时再进行GC,需要预留一部分空间提供用户线程运行使用。当 CMS 运行时,预留的内存空间无法满足用户线程的需要,就会出现 “ Concurrent Mode Failure ”的错误,这时将会启动后备预案,临时用 Serial Old 来重新进行老年代的垃圾收集。
4、G1垃圾收集器
在JDK1.9后,G1成为了默认的垃圾回收器。并且G1垃圾回收期在逻辑上分代,物理上不分代。
G1的堆区在分代的基础上,引入分区的概念:
- G1将堆分成了若干Region,这些分区不要求是连续的内存空间。
- Region的大小可以通过G1HeapRegionSize参数进行设置,其必须是2的幂,范围允许为1Mb到32Mb。
- JVM的会基于堆内存的初始值和最大值的平均数计算分区的尺寸,平均的堆尺寸会分出约2000个Region。分区大小一旦设置,则启动之后不会再变化。
- 分区可以有效利用内存空间,因为收集整体是使用“标记-整理”,Region之间基于“复制”算法,GC后会将存活对象复制到可用分区(未分配的分区),所以不会产生空间碎片。

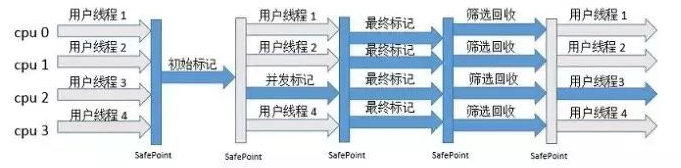
G1收集器的运作大致可以分为以下步骤:
- 初始标记:标记出 GC Roots 直接关联的对象,并且修改TAMS(Next Top at Mark Set)的值,让下一个阶段用户程序并发运行时,能在正确可用的Region中创建新对象,
会STW。 - 并发标记:从GC Root 开始对堆中的对象进行可达性分析,找出存活对象。
- 最终标记:修正并发标记阶段因用户程序继续运行而导致垃圾对象的标记记录(可能不再是垃圾),并且虚拟机将这段时间对象变化记录在线程Remembered Set Logs里面,最终标记需要把Remembered Set Logs的数据合并到Remembered Sets中,这个阶段耗时较长,但可以和用户线程并发执行。
会STW。 - 筛选回收:筛选回收阶段会对各个 Region 的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来指定回收计划(用最少的时间来回收包含垃圾最多的区域,这就是 Garbage First 的由来——第一时间清理垃圾最多的区块),这里为了提高回收效率,并没有采用和用户线程并发执行的方式,而是
STW。















 1953
1953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









