







Dilated convolution 一般译作空洞卷积或者膨胀卷积,在图像修复任务 Generative Image Inpainting with Contextual Attention一文中作者使用了此方法,并这么给出解释:In image inpainting tasks, the size of the receptive fields should be sufficiently large, and Iizuka et al. [17] adopt dilated convolution for that purpose
很明显的指出 膨胀卷积的巨大优势在于增加感受野。
论文
Dalited concolution由《Multi-Scale Context Aggregation by Dilated Convolutions》一文针对语义分割内容提出。
论文地址:[1511.07122]
源码地址:fyu/dilation
分析
针对图像语义分割中像素点级别的密集预测分类,文章提出了一种新的卷积网络模块。通过膨胀(空洞)卷积进行多尺度上下文信息聚合而不降低特征图的大小,膨胀卷积支持感受野的指数增长。
论文核心思想:
传统的图像分类网络通常通过连续的pooling或其他的下采样层来整合多尺度的上下文信息,这种方式会损失分辨率。而对于稠密预测(dense prediction)任务而言,不仅需要多尺度的上下文信息,同时还要求输出具有足够大的分辨率。
为了解决这个问题,过去的论文的做法是:
在图像分割领域,图像输入到FCN中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像像素的同时增大感受野,感受野的问题是需要自己仔细考虑的,这个也是为什么深度学习刚刚兴起的时候论文中采取的filter偏向于选取大尺寸,例如7× 7或者5× 5;现在想来是为了扩大感受野来学习到尽可能多的近邻信息。
VGG论文一个很大的贡献就是指出:作者从卷积叠加的观察中发现:
This (stack of three 3 × 3 conv layers) can be seen as imposing a regularization on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
这里意思是 7 x 7 的卷积层的正则等效于 3 个 3 x 3 的卷积层的叠加。而这样的设计不仅可以大幅度的减少参数,其本身带有正则性质的 convolution map 能够更容易学一个 generalisable, expressive feature space。这也是目前绝大部分基于卷积的深层网络都在用层层堆积的小卷积核的原因。
但是由于图像分割预测是逐像素的输出,所以要将pooling后较小的图像尺寸上采样(upsampling)到原始的图像尺寸进行预测,上采样一般采用反卷积(deconv)操作。池化(pooling)操作使得每个像素预测都能看到较大的感受野信息,上采样则将池化后的图像恢复到原尺寸。
同时很多网络会提供图像的多个重新缩放版本(multiple rescaled verions of the image)作为网络的输入。作者认为这种解决问题的思路似乎也并不必要(比如在相似检测问题中将输入图像进行三个尺寸的resize并进行比较的问题)。
基于以上两点分析与思考,作者在这篇文章中提出了一种新的卷积网络模块,它能够整合多尺度的上下文信息,同时不丧失分辨率,也不需要分析重新放缩的图像。这种模块是为稠密预测专门设计的,没有pooling或其它下采样,即为膨胀卷积。
具体细节
既然网络中加入pooling层会损失信息,降低精度。那么不加pooling层会使感受野变小,学不到全局的特征。如果我们单纯的去掉pooling层、扩大卷积核的话,这样纯粹的扩大卷积核势必导致计算量的增大,此时最好的办法就是Dilated Convolutions。
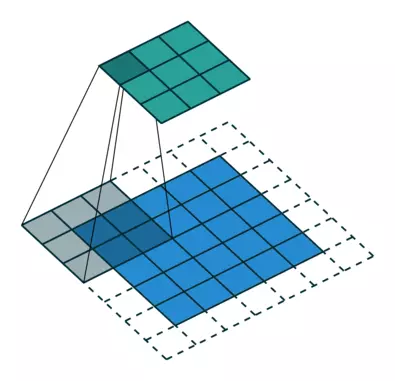
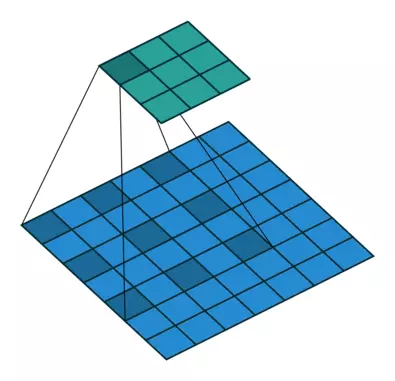
补充:dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割、语音合成WaveNet、机器翻译ByteNet中。















 4940
4940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









