







引言:之前对GAN进行相关的介绍,并在组内进行分享;但之前的分享比较偏向于GAN的前世,对于GAN的今生关注的程度不高,本文重点对GAN的今生进行梳理。
GAN的今生
GAN的前世之前进行过相关总结,GAN的原理具有简洁的逻辑的美,在本文不予赘述,具体可以观看李弘毅老师的讲课视频,深入浅出;
Generative adversarial nets
李宏毅关于GAN的分享,非常细致清楚
Goodfellow在写成 Geneative adversarial nets 这一划时代的大作的时候自然是留了为数众多的坑待填,后来的工作者在理论与网络结构上孜孜以求,不断创新也形成了一大批质量极佳的论文,形成了GAN的今生。
理论派
1、 f-GAN
散度进化:f-GAN是f-divergence GAN的缩写,原生GAN的discriminator为J-S divergence。这种散度在求解过程中不如f-divergence易于收敛;那么基于各式各样的f-divergence出现了很多论文,当然最经典的还是J-S divergence。
2、WGAN
散度替代:原始GAN使用的J-S divergence,可能出现两个分布其实在接近,但discriminator却检测不到的情况,fGAN试着从不同的divergence入手,而WGAN则重新换了一种思路,不用divergence衡量分布,而用earth mover distance(推土机距离)或者称之为Wasserstein distance来衡量不同分布之间的距离。
WGAN的使用了两种权重的处理手段,来防止权值爆炸;分别是原始的weight clip以及WGAN-GP
Training Generative Neural Samplers using Variational Divergence Minimization
Wasserstein gan
Improved training of wasserstein gans
网络结构派
1、DCGAN[1]
之前GAN的generator和discriminator都用的是简单的线型神经元。我们知道,近年来深度学习之所以能大放光彩,主要还是得益于CNN的应用。同样的,GAN中的generator和discriminator也可以换成CNN,最先提出这个思想的就是DCGAN。G和D的结构均由线性单元更换成CNN结构。
2、CGAN[2]
conditional GAN[2]是最早的GAN的变种之一,把原生GAN中的概率全改成条件概率:
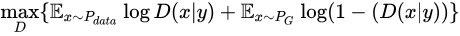
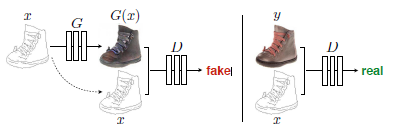
3、pix2pix[3]
这篇文章在cGAN的发展历史上感觉是地位隆重,基本上网路结构都逃避不了要复制或者借鉴这篇文章的结构;文章也在很多方面获得良好的应用;包括但不限于inpainting,人脸生成,colorization等工作,可以说是具有划时代的意义。在本小节我们将对pix2pix结合他人的讲解进行了解。
3.1 介绍
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。通常每一种问题都使用特定的算法(如:使用CNN来解决图像转换问题时,要根据每个问题设定一个特定的loss function 来让CNN去优化,而一般的方法都是训练CNN去缩小输入跟输出的欧氏距离,但这样通常会得到比较模糊的输出)。这些方法的本质其实都是从像素到像素的映射。于是论文在GAN的基础上提出一个通用的方法:pix2pix 来解决这一类问题。通过pix2pix来完成成对的图像转换(Labels to Street Scene, Aerial to Map,Day to Night等),可以得到比较清晰的结果

3.2 网络结构
论文宣称自己对DCGAN的生成器和判别器的结构做了一些改进,但是实际上论文首次引入Unet结构作为生成器,创造性地验证patchGAN作为鉴别器的可行性与优越性,并获得了极佳的实验效果。
生成器部分采用了Unet结构。U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显。
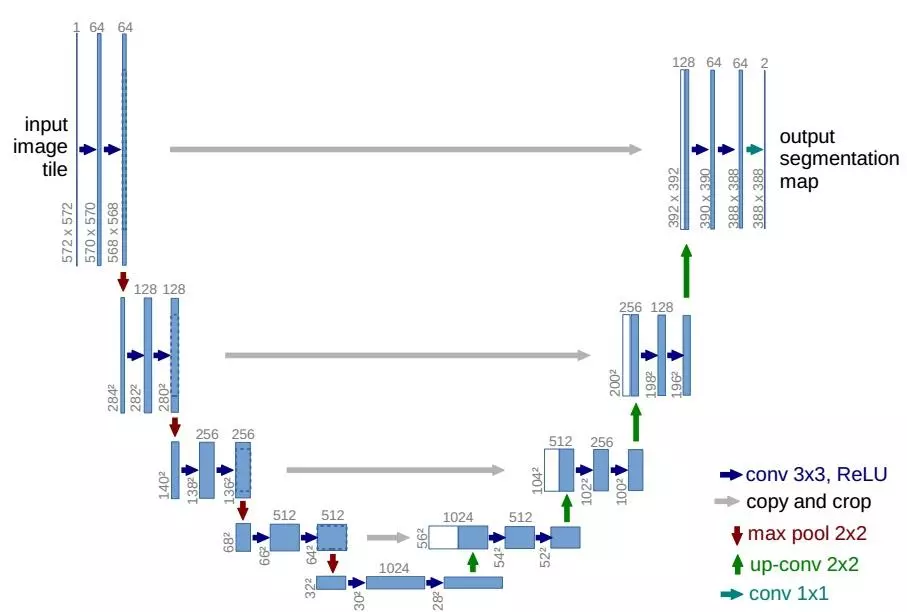
鉴别器部分利用马尔科夫性的判别器(PatchGAN),pix2pix采用的一个想法是,用重建来解决低频成分,用GAN来解决高频成分。一方面,使用传统的L1 loss来让生成的图片跟训练的图片尽量相似,用GAN来构建高频部分的细节。
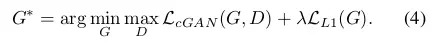
另一方面,使用PatchGAN来判别是否是生成的图片。PatchGAN的思想是,既然GAN只用于构建高频信息,那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为N x N的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的N x N大小的patch,判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。关于patchGAN的相关精神领悟来说,可以推荐一篇解释非常细致的blog一文看懂PatchGAN ;7070的patch来自于对感受野的计算,而非直接的对原图进行crop。
对于patchGAN的7070如何得到,以及对于patchGAN的实质表现形式为convnet的问题,作者有在github上进行回答:Question: PatchGAN Discriminator
具体实现的时候,作者使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。论文对比了不同大小patch的结果,对于256x256的输入,patch大小在70x70的时候,从视觉上看结果就和直接把整张图片作为判别器输入没有多大区别了。
4 BicycleGAN[6]
Pix2pix生成的结果十分单一,为了增加多样性,cycleGAN的大佬又提出BicycleGAN。大佬们基本上都来自同一个实验室,在伯克利的良好科研环境下竞相发paper。这个GAN主要是结合了cVAE-GAN和cLR-GAN两个变种,同时训练这两个网络,如下图:

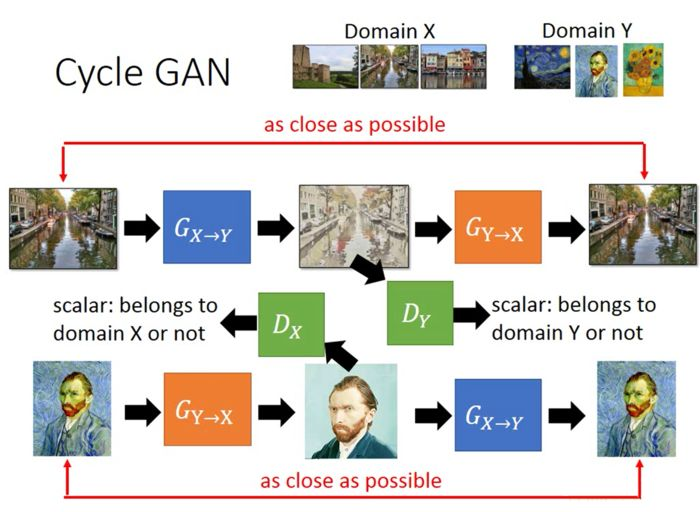
5 Cycle GAN[4]
上面所介绍的cGAN需要有paired data,也许,我们没办法得到这样的数据,比如把彩铅画转化成真实图,不可能去找画家去画各种彩铅画。Cycle GAN[4]和Disco GAN[5]告诉我们不用paird data一样可以做到风格转移:
除了用image做条件外,还可以用text做条件,这样就可以完成基于文本描述的图像生成,不同方法的区别在于如何处理文字,可以转化成向量、矩阵,或者用一个RNN处理。这方面典型的代表工作是:GAN-INIT-CLS[7], GAWWN[8], StackGAN[9]. 这个不是我目前研究的重点,以后再补充相关的细节,这里只给出三个方法的部分实验结果,先是根据文字描述生成鸟

6 本节参考文献
[1] Radford A, Metz L, Chintala S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015.
[2] Mirza, Mehdi, and Simon Osindero. “Conditional generative adversarial nets.” arXiv preprint arXiv:1411.1784 (2014).
[3] Isola, Phillip, et al. “Image-to-image translation with conditional adversarial networks.” arXiv preprint (2017).
[4]Zhu, Jun-Yan, et al. “Unpaired image-to-image translation using cycle-consistent adversarial networks.” arXiv preprint arXiv:1703.10593 (2017).
[5]Kim T, Cha M, Kim H, et al. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks[J]. 2017.
[6] Zhu J Y, Zhang R, Pathak D, et al. Toward Multimodal Image-to-Image Translation[J]. 2017.
[7] Reed S, Akata Z, Yan X, et al. Generative Adversarial Text to Image Synthesis[J]. 2016:1060-1069.
[8] Reed S, Akata Z, Mohan S, et al. Learning What and Where to Draw[J]. New Republic, 2016.
[9] Zhang H, Xu T, Li H. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks[J]. 2016:5908-5916.















 3823
3823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









