






mambair 作为目前比较新颖的mamba创新结构,是非常值得作为研究探讨的,本文记录mamba在本地部署过程中踩到的坑,帮助大家早日部署好环境进入到具体的研究过程中。
1、CUDA版本的配对
MambaIR要求的具体安装环境如下图所示:

比较容易出问题的是CUDA版本,实际上我的CUDA版本只安装到了11.4,这个在安装
pip install causal_conv1d == 1.0.0
pip install mamba_ssm ==1.0.1
过程中是有专门的约束要求cuda above 11.6,因此这个工作必须扎扎实实率先完成。
####1.1 安装CUDA11-7
首先在nvidia官网寻找自己的服务器使用的处理器版本以及操作系统版本。
docker version
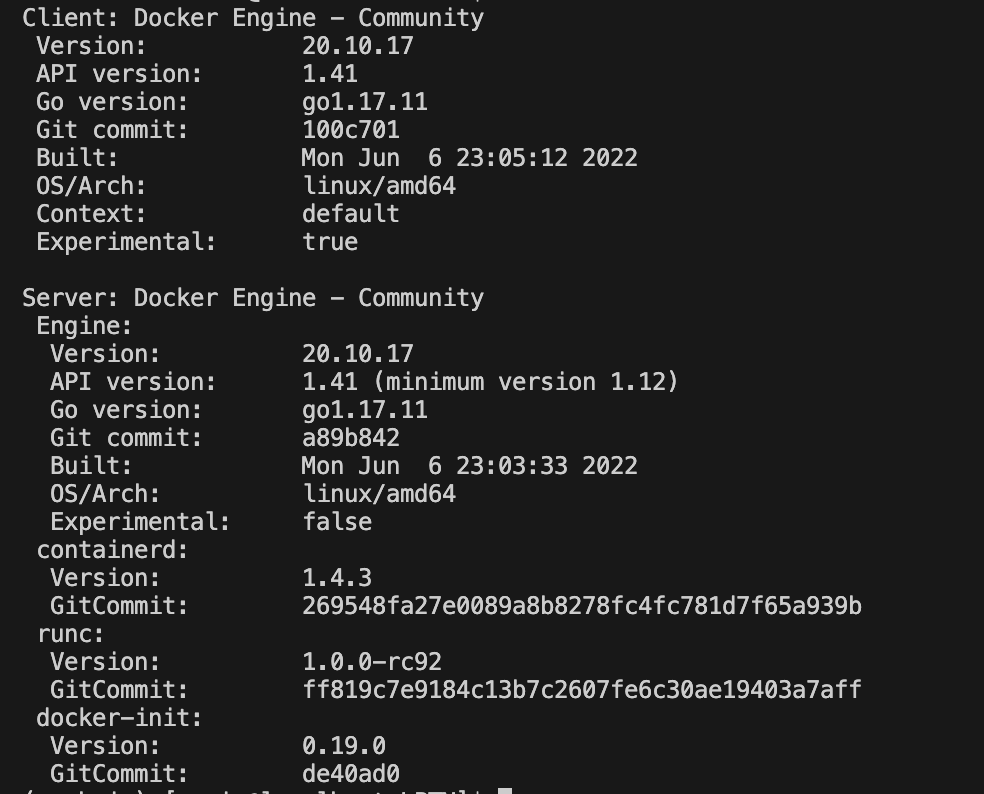
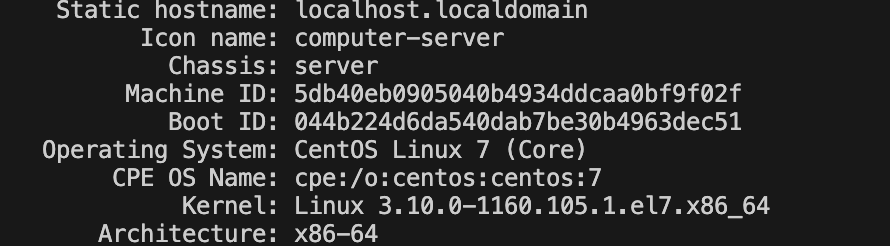
此时就可以确定目前的linux cuda dirver 版本,此时nvidia会提供三种cuda的安装方式,我推荐runfile local的安装方式,第一种方式我安装之后在/usr/local下面没有看到cuda11-7的文件夹,具体的安装过程可以参考博客:
Centos7配置深度学习环境 CUDA 11.8+PyTorch 2.2.2
其中我在安装过程中遇到了/tmp内存不够的问题,解决方法参考此博客:
ubuntu 20.04LTS下安装cuda时提示/tmp空间不足问题的解决方案
以及遇到了服务器download驱动文件需要切换源的问题,可以参考:
Centos7出现问题Cannot find a valid baseurl for repo: base/7/x86_64
以及配置阿里yum源的过程中需要清除原有缓存再sudo yum makecache老是报错,最后直接先暴力删除已有的缓存,再makecache成功。
CentOS8使用阿里云yum源异常
到这算是第一步CUDA11-7是安装好了,nvcc -V查看的话完全正常,显示的就是11-7;我们之前的博客说过nvidia-smi和nvcc -V的区别,一个显示的cuda版本是driver支持的最大版本,另外一个则是本环境本bashrc下使用的cuda版本。
2、mamba安装
安装mamba刚刚开始以为是玄学报错,明明nvcc显示的是11-7,一直疯狂报错需要cuda版本above11-6,非常崩溃,各种尝试。
causal_conv1d和mamba_ssm安装报错问题
flash-attention踩坑:使用conda管理CUDA
Install error #186
疯狂尝试无果之后我决定使用源码安装,这也是我个人debug的一个好习惯了,源码安装相比于pip安装,显著的优势在于可以在源码中找问题。
终于被我发现报错的来源:
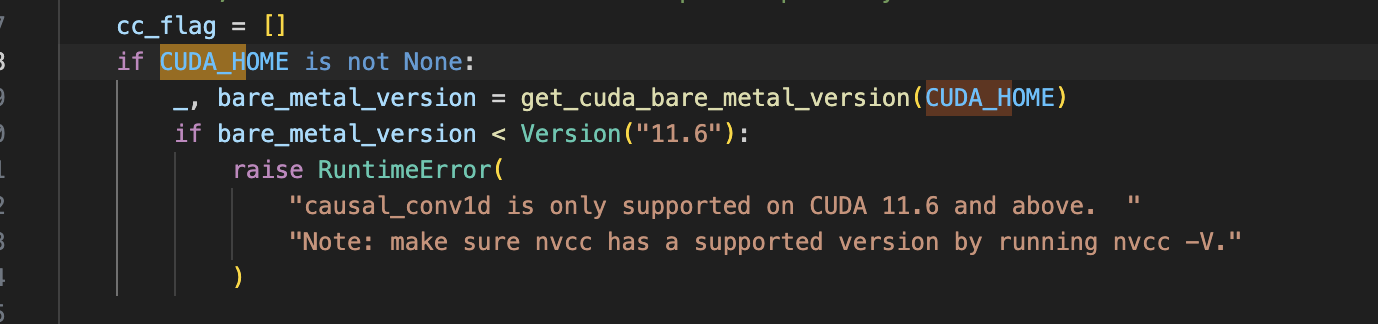
顺藤摸瓜发现CUDA_HOME就是bashrc里面的内容,我只改了两项,抓紧修改:
export CUDA_HOME=/usr/local/cuda-11.7
export PATH=/usr/local/cuda-11.7/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64:$LD_LIBRARY_PATH
这个问题困扰我一下午时间,如果不是看源码,我翻遍全网都找不到这个错误。这也是我为什么立刻写下本博客分享的原因。
在解决此问题之后,后面的问题就变得可控了。主要是mamba-ssm安装building wheel卡着不动,一晚上都没有下载下来,需要自己whl安装。
下载causal-conv1d
Dao-AILabcausal-conv1d
和mamba-ssm
state-spacesmamba
的whl文件,并pip install本地安装。
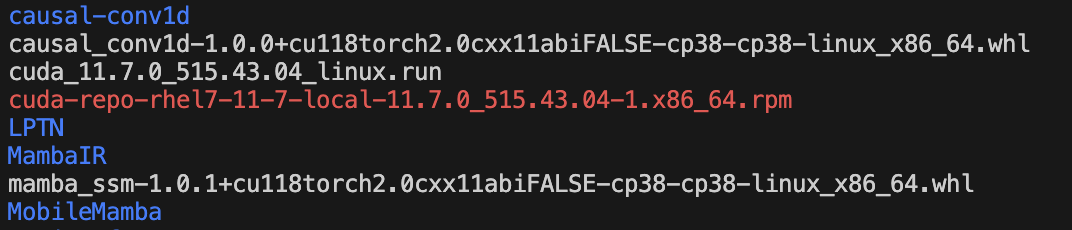

最终效果配置好之后运行无误,可以进行下一步的研究工作啦。

















 47
47

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









