






这个问题的本质是解码方式,了解了解码方式自然就明白了。
对于LLM来说,有好几种采样算法。但是要记住LLM既需要准确性也需要多样性。
-
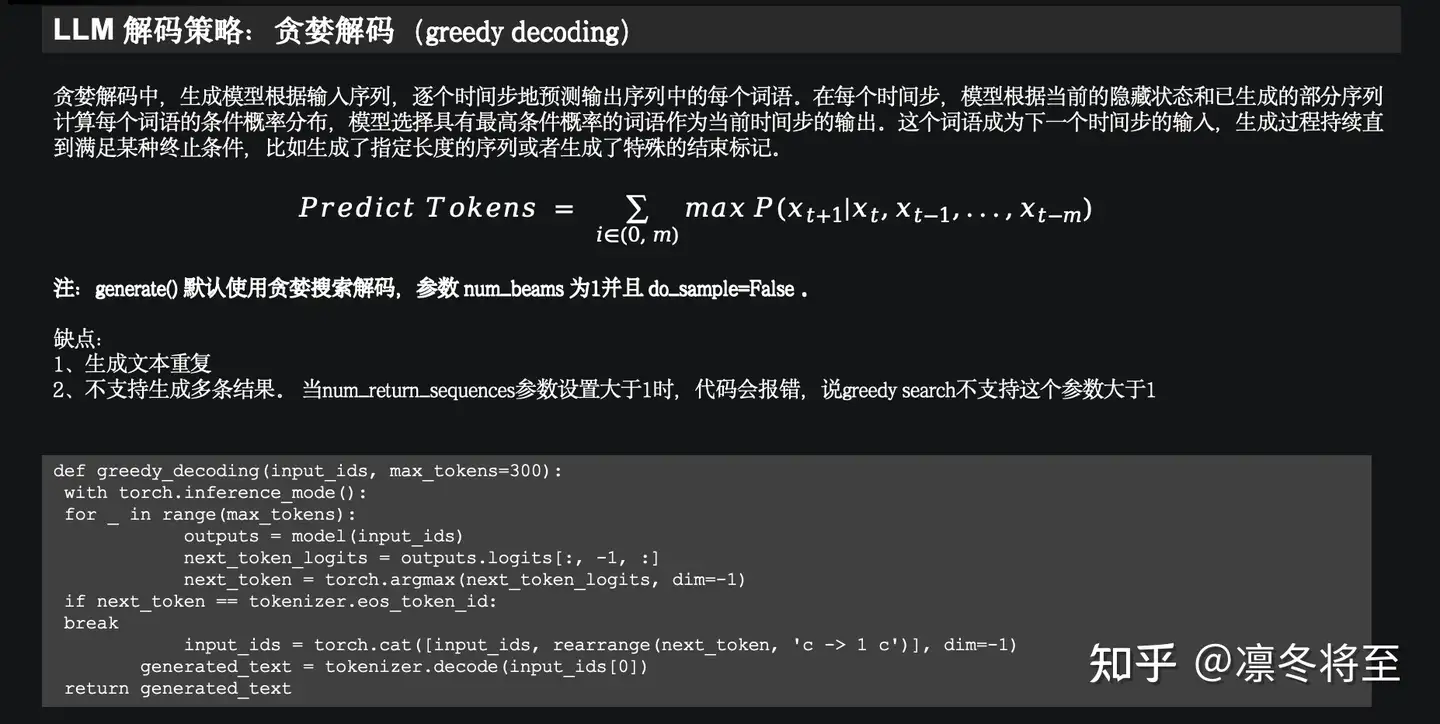
greedy采样:每次总是采样概率最大的值对应的token。这也是个确定性算法,并且只考虑了当前轮生成的信息;
-
beam search:使用当前轮信息以及历史信息选择联合概率最大的beam width个概率最大的值对应的token作为当前轮生成的信息。这是一个确定性算法,理论上生成质量比greedy的要好,但是计算量更大。他们共同的缺点就是缺乏多样性,多次问同样的问题会得到同样的结果。而我们期望多次问同样的问题有不同的结果,也就是想要有多样性。
-
top-k:取出概率最大的k个概率,然后随机选择一个。它的好处是增加了多样性,缺点是k不好选,采样可能会采样到概率比较小的;
-
top-p*:采样的时候采样最小的集合使得集合里面的概率总值超过给定的概率阈值。然后再从这个集合随机采样。这其实是为了解决上面top-k的k不好选的问题,同但是依然有可能采样到小概率;
-
带temperature的top-k和top-p,其实就是调整原始的概率分布使得采样到小概率的几率被temperature调节。temperature越接近0无穷大,采样越接近均匀采样;越接近O,采样越接近greedy采样。后续还出现了动态调节temperature的算法。


-
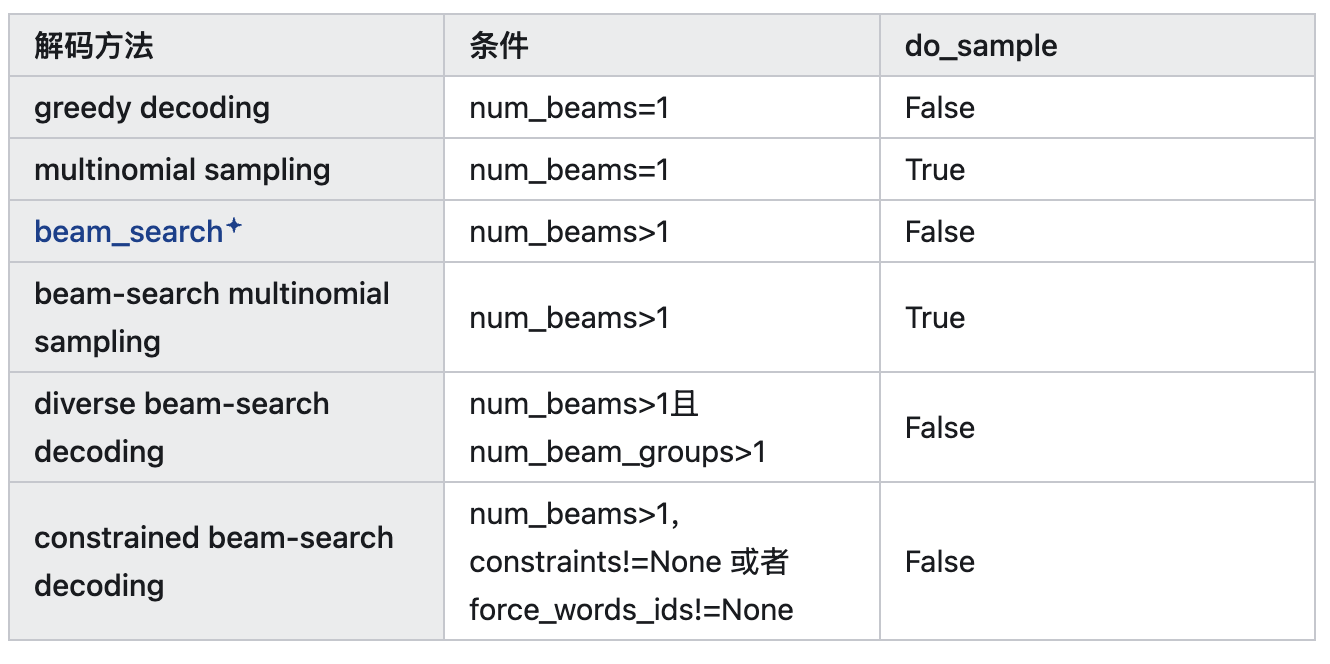
do_sample:决定模型是否采用随机采样(sampling)的方式来生成下一个词,还是仅仅选择最有可能的词。设置为True,启用如多项式采样、波束搜索多项式采样、top k采样+、top p采样+的解码策略。
设置 do_sample=True,启用如多项式采样、波束搜索多项式采样、top k采样、top p采样的解码策略。同时也可以在采样时可以指定一些参数,例如 temperature*、top_P 等,这些参数会影响采样方法的结果,从而影响生成文本的多样性和质量。
如果设置 do_sample=False,那么就会使用贪心算法(greedy decoding)来生成文本,即每次选择模型输出概率最大的token 作为下一个 token,这种方法生成的文本可能会比较单一和呆板。 -
temperature:控制生成文本的随机性和多样性,其实是调整了模型输出的logits概率分布。
temperature参数则会影响采样时概率分布的形状,从而影响生成文本的多样性。较高的temperature值会使分布更加均匀,增加随机性;较低的temperature值会使分布更加尖锐,减少随机性,更倾向于选择高概率的词。
top_k:用于在生成下一个token时,限制模型只能考虑前k个概率最高的token,这个策略可以降低模型生成无意义或重复的输出的概率,同时提高模型的生成速度和效率。
top-p:用于控制生成文本多样性的参数,也被称为"nucleus sampling"。这个参数的全名是"topprobability",通常用一个介于0到1之间的值来表示生成下一个token时,在概率分布中选择的最高概率的累积阈值。采样是从累积概率超过概率p的最小可能单词集合中进行选择,单词集合的大小(采样个数)可以根据下一个单词的概率分布动态地增加和减少。
也可以参考如下的链接:
EDT: 动态调整LLM里面的temperature
对于相同问题大模型的生成为什么会不同?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









