







一、简介
Bunch本质上的数据类型是dict,属性有:
- DESCR:数据描述。
- target_names:标签名。可自定义,默认为文件夹名。
- filenames:文件名。
- target:文件分类。如猫狗两类的话,与filenames一一对应为0或1。
- data:数据数组。
二、代码
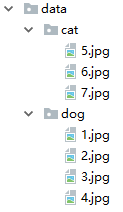
目录结构如图:
from sklearn.datasets import load_files
PATH = './data'
DESCR = 'dog cat dataset'
bunch = load_files(container_path=PATH, description=DESCR)
print('【type】\n', type(bunch))
print('【DESCR】\n', bunch.DESCR)
print('【target_names】\n', bunch.target_names)
print('【filenames】\n', bunch.filenames)
print('【target】\n', bunch.target)
# print('【data】\n',bunch.data)
三、结果
【type】
<class 'sklearn.utils.Bunch'>
【DESCR】
dog cat dataset
【target_names】
['cat', 'dog']
【filenames】
['./data\\dog\\4.jpg' './data\\cat\\7.jpg' './data\\cat\\6.jpg'
'./data\\dog\\1.jpg' './data\\cat\\5.jpg' './data\\dog\\3.jpg'
'./data\\dog\\2.jpg']
【target】
[1 0 0 1 0 1 1]
- 猫对应的分类是0,狗对应的分类是1。
target与filenames一一对应。 - 函数
load_files从文件夹读取bunch默认随机洗牌,可在该函数中添加shuffle=False取消洗牌。
四、备注
以上用点.引用属性均可用键值对形式['']引用,如bunch.target可换成bunch['target']。

















 3760
3760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









