







1 C语言格式
主函数main
c程序主体是由函数构成
函数体的内容在{}中
每一个执行语句的 结尾是;
英文字符大小写不通用
空格空行的使用
2 整型变量
长整型后面加L,无符号整型后面加U
1000L,500U大小写均可
3 进制
8进制前面加0,16进制加0x
4 原码与补码
一个正数的补码与其源码相同
一个负数的补码等于其绝对值的原码按位取反加1
整型数据在计算机内以二进制存储形式存储,存储的是其对应的补码
5 实型常量
单精度后面加F,双精度加L,大小写通用
1.23F,1.21412412L
1.23e2=123
6 字符串存储
空字符串的长度为0
"welcome"在内存中存储形式为 w e l c o m e \0
会在末尾补上反斜杠0
7常用的转义字符表
\n 回车换行
\t 横向跳到下一制表位置
\v竖向跳格
\b退格
\r回车
\f 走纸换页
\\ '\'
\' 单引号
\a 鸣铃
\ddd1~3位八进制所带表的字符
\xhh 1~2位16进制数所代表的字符
7 静态存储与动态存储
静态存储是指程序运行时为其分配固定的存储空间,动态存储则是在程序运行时根据需要动态地分配存储空间
auto关键字用来修饰局部变量 一般定义的局部变量自带auto关键字,不需要再加
static变量为静态变量 ,将函数内部变量与外部变量声明为static变量的意义是不一样的
在函数内声明static变量时,变量只初始化1次,多次进入函数变量不会再次初始化
register变量称为寄存器存储变量
通过register变量,可以把某个局部变量指定存放在计算机的某个硬件寄存器中,而不是在内存中,提高程序的运行速度。实际上编译器可以忽略register对变量的修饰。
extern变量称为外部存储变量
声明了程序中将要使用,但尚未定义的外部变量。
8 赋值运算符与赋值表达式
= 赋值运算符:将一个数据赋给一个变量
类型 变量名 = 常数
类型 变量名 = 表达式
9 强制类型转换
(类型名)(表达式)
float i = 10.1f;
int j = int(i);
10 C语言中的算术运算符和算术表达式
c语言中有2个单目算数运算符5个双目算术运算符
单目指的是只跟一个变量 +1,-1
双目是跟两个变量 1*1 1/1 1%1 1+1 1-1
优先级单目大于双目 双目里乘除大于取余大于加减
如果是负数除以正数,结果会向0取整
-7/4=-1;
括号()在所有优先级中最高,可以改变加减乘除的运算顺序!
自增++自减--运算符
在表达式内部,作为运算的一部分,放在前面,在变量参加表达式运算之前完成自增或自减,放在后面,表达式运算完毕后变量自增或自减。
11 关系运算符与关系表达式
大于>大于等于>= 小于< 小于等于<= 等于== 不等于!=
关系运算符用于两个表达式的值进行比较,返回一个真值或假值 真1假0
优先级和结合性
自左向右 =的优先级低于!=(赋值运算符优先级低于关系运算符)
12逻辑运算符与逻辑表达式
逻辑运算符根据表达式的真或者假属性返回真值或假值
在C语言中表达式的值非0就是真,只有当表达式为0才为假
&& || !逻辑与 逻辑或 逻辑非
&& 和||都是双目运算符,优先级依次是 非 与 或 ! && || ,自左到右
位逻辑运算符与位逻辑表达式
位逻辑与,位逻辑或,为逻辑非,取补 & | ^ ~,这些运算符只能用于整型表达式
13 逗号运算符与逗号表达式
表达式1,表达式2,表达式3
整个逗号表达式的值是最后一个表达式的值
与赋值运算符连用时,注意,赋值运算符的优先级大于逗号运算符
value = 2+5,1+2,5+7结果是7
14 优先级
单目运算符的优先级大于双目运算符
赋值运算符优先级小于关系运算符 ,大于逗号运算符
特殊运算符()[] -> .的优先级最高
三目运算符优先级大于赋值运算符大于逗号运算符
赋值运算符的结合顺序是自右向左。
例如 a+=a*=a/=a-6
假如a=8,则先计算算数运算符 a-6=2,再从右向左 a=a/2=4 a=a*4=4*4=16 a=a+16=16+16=32
15字符数据
字符数据输出
int putchar(int ch)//将字符常量或字符变量输出到屏幕上
字符数据输入
int getchar()//从键盘读入一个字符,然后等待输入是否结束,如果用户按下ENTER键,则执行下一条语句。
getch()//从键盘读入一个字符,但不显示在屏幕上。
putchar(getchar())
字符串输出函数
int puts(char* str)
char* gets(char *str)
用法puts("i love china"),gets(cString);puts(cString)
16格式输出函数
printf函数作用向终端或输出设备输出若干类型的数据
printf(格式控制,输出列表)
格式字符
d,i以带符号的十进制形式输出整数(整数不输出符号)
o 以八进制无符号形式输出整数
x,X以十六进制输出,x以小写,X以大写
u以无符号十进制形式输出整数
c以字符形式输出,只输出一个字符
s输出字符串
f以小数形式输出
e,E以指数形式输出实数
g,G用%f或%e格式中输出宽度较短的一种形式
字母l 用于长整型整数,可加在d、o、x、u前面
m代表一个整数 数据最小宽度
n代表一个整数 对实数表示输出n位小数,对字符串表示截取的字符个数
-输出的数字或字符在域内向左靠拢
17格式输入函数
scanf 按照指定格式接收用户在键盘上输入的数据
scanf(格式控制,地址列表)
d,i 有符号的十进制数
u 无符号的十进制数
o无符号的八进制数
x,X无符号的十六进制数
c 用来输入单个字符
s 用来输入字符串
f用来输入实型
e,E,g,G与f作用相同
l用于输入长整型数据
h用于输入短整型数据
n指定输入数据所占的宽度
*表示指定的输入项在读入后不赋给相应的变量
scanf("%d* %d",&a,&b);
18 选择结构
else语句必须跟在if后面
if,if else,else if三种形式
if(表达式)语句块
if(表达式)语句块1;
else 语句块2;
if (表达式1)语句1
else if(表达式2)语句2
.。。。
else 语句n
意思是表达式为真则执行语句1,结束选择。如果表达式为假,就向后寻找。选择结构只会执行一次。
if的嵌套形式
if(表达式1)
if(表达式2)语句块1
else 语句块 2
else
if(表达式3)语句块3
else 语句块 4
在使用if嵌套时,应注意if与else的配对情况。else总是与其上面的最近的未配对的if进行配对
19 条件运算符
表达式1 ?表达式2:表达式3;
对表达式1的值进行检验,如果为真,返回表达式2的值,假返回表达式3的值
switch语句
switch(表达式)
{
case 情况1:
语句块1;
。。。
case 情况n:
语句块n;
default:
默认情况语句块;
}
switch一般与break联用。
两个case语句都不能使用相同的值,当没有与case匹配的值时执行default后面的。default可有可无
可以使用switch不加break来构成多路开关模式
case 2:
case 3:
case 4:。。。break;
如果判决的是 值2,那它会到case2去,然后经过case3 到case4遇到break弹出
如果分支在3个4个以下用if else 超过4个用switch
20循环语句
while(表达式)语句
当里的条件为真,执行语句,再次判断条件是否为真
do while语句
do
循环体语句
while(表达式)
不论条件是否满足,语句都会执行一次。其他的与上面的while相同。执行一次后判断条件是否成立,成立执行一次语句。再次判断条件是否成立。
for语句
for(表达式1;表达式2;表达式3)
执行for语句时,程序先执行第一个表达式,然后计算第二个表达式,表达式2为真则进入for循环内部执行语句,为假则跳出循环。执行完一次内部的语句会跳到表达式3.然后再检验表达式2.如此往复
for循环的变体
for(;语句1;语句2)应在for循环之前给变量赋初值
for(语句1;;语句2)该变体等同于while(1),循环一直执行
for(语句1;语句2;)该变体等同于变体2,没有循环终止的条件,一直执行。
for语句中逗号的使用
例如for(iCount=1;iCount<100;iCount++,iCount++)
21循环嵌套结构
while循环中嵌套while循环
while()
{
语句
while(表达式)
{
语句
}
}
do while中嵌套do while
do
{
语句
do
{
语句
}while(表达式)
}while(表达式)
for循环中嵌套for循环
for(表达式;表达式;表达式)
{
语句
for(表达式;表达式;表达式)
{
语句
}
}
do while循环中嵌套while循环
do
{
语句
while(表达式)
{
语句
}
}while(表达式)
do while循环内嵌套for循环
do
{
语句
for(表达式;表达式;表达式)
{
语句
}
}while(表达式)
22 转移语句
goto break continue
goto语句为无条件转移语句,可以使程序立即跳转到函数内部的任意一条可执行语句。goto后面跟一个标识符。表示需要跳转的地方。标识符一般后面要跟个冒号
goto Show;
printf("the message before Showmessage");
Show:
printf("Showmessage");
执行到goto的时候直接跳转到Show标识符后面的语句执行。
break语句终止并跳出循环
continue 跳出本次循环进行下一次循环
23一维数组
一维数组用于存储一维数列中数据的集合
类型说明符 数组标识符[常量表达式];
例如 int iArray[5];可以用iArray[0]~iArray[4]。不能用iArray[5],否则造成数组越界!
下标可以是整型变量或整型表达式
一维数组的初始化
1直接对数组元素赋值
int iArray[6]={1,2,3,4,5,6};
2赋值数组中的部分元素
int iArray[6]={1,2,3};//只有前三个被赋值了,其他都是0
3不指定数组元素个数
int iArray[]={1,2,3,4}
一维数组的应用
使用数组来保存学生姓名
char* ArrayName[]={"wangjia","Lipeng"};
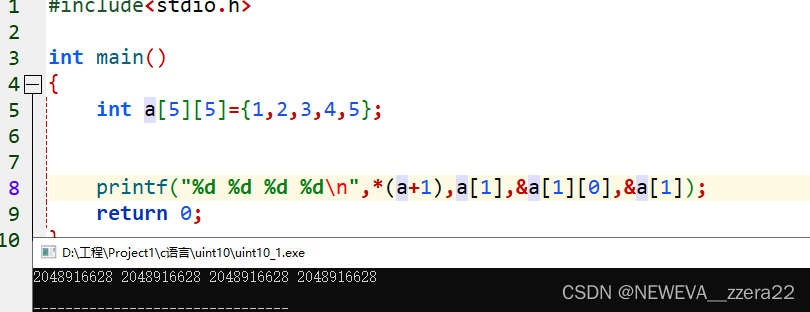
24二维数组
二维数组的定义与一维数组相同
数据类型 数组名[常量表达式1][常量表达式2]
常量表达式1被称作行下标,常量表达式2被称作列下标。
如果二维数组是n行m列,则下标范围是0~n-1,0~m-1
二维数组的引用
数组名[下标1][下标2]
二维数组的初始化
1:将所有元素放入大括号内,按找排序给数组赋值
int array[2][2]={1,2,3,4};
2:省略行下标,其余与第一种一致
int array[][2]={1,2,3,4};
3:分行给数组元素赋值
int array[2][2]={{1,2},{3,4}};
二维数组的应用
输入一个任意的3行3列的二维数组,求对角线元素之和
#include<stdio.h>
int main()
{
int arrayd2[3][3]={0};
printf("请输入数组元素:\n");
for(int i=0;i<=2;i++){
for(int j=0;j<=2;j++){
scanf("%d",&arrayd2[i][j]);
}
}
printf("\n%d\n",arrayd2[0][0]+arrayd2[1][1]+arrayd2[2][2]);
return 0;
}
25 字符数组
当数组中的元素为字符时,成为字符数组
char 数组标识符[常量表达式]
char cArray[2]={'a','b'};
其余与一维数组一样,不能下标越界。
字符数组初始化
1:逐个字符赋给数组中的各元素
char cArray[5]={'H','e','l','l','o'};
2:在定义字符数组时进行初始化,此时可以省略数组长度
char cArray[]={'H','e','l','l','o'};
3:利用字符串给字符数组赋值
char cArray[]={"Hello"};
char cArray[]="hello";
字符数组的结束标志
字符串总是以'\0'作为结束符,用字符串赋值的方式比逐个赋值要多占一个字节。所以为了处理方法一致,我们通常在单个字符赋值后面加上一个结束符
char cArray[]={'H','e','l','l','o','\0'};
char cArray[]="Hello";
字符数组的输入输出
格式符 %c进行输入和输出
格式符%s进行输入输出
printf("%c",cArray[1]);
printf("%s",cArray);
如果一个数组中包含多个'\0'元素,则在遇到第一个时就结束输出
26多维数组
数组类型 数组名[常量表达式1][常量表达式2]...[常量表达式n]
27数组排序
1选择排序法
每次选择所要排序的数组中的最大值或最小值的数组元素,将这个数组元素值与前面没有进行排序的数组元素的值互换。
#include<stdio.h>
int main()
{
int i,j;
int iArray[10];
int n = 10;
int temp = 0;
int pos = 0;
while(n--)
{
scanf("%d",&iArray[9-n]);
}
for(i=0;i<9;i++)
{
temp = iArray[i];
pos = i;
for(j=i+1;j<10;j++)
{
if(iArray[j]<temp)
{
temp=iArray[j];
pos = j;
}
}
iArray[pos]=iArray[i];
iArray[i]=temp;
}
for(int i=0;i<10;i++){
printf("%d ",iArray[i]);
}
return 0;
}
思路:排序10个数,选择法要排9次,第一次设第一个是最大或最小值,然后从第二个开始找比第一个小就令最小值为第二个记录下标。第三个要是依然比最小值小,交换第3个和最小值,记录下标。最后找到了最小值。结束第一次大循环,把最小值与第一个值交换,最小值下标来接收第一个值。依次循环后面8轮。
2冒泡法排序
#include<stdio.h>
int main()
{
int i,j;
int iArray[10];
int n = 10;
int temp = 0;
while(n--)
{
scanf("%d",&iArray[9-n]);
}
for(i=0;i<10;i++)
{
for(j=9;j>=i;j--)
{
if(iArray[j]<iArray[j-1])
{
temp = iArray[j-1];
iArray[j-1]=iArray[j];
iArray[j]=temp;
}
}
}
for(int i=0;i<10;i++){
printf("%d ",iArray[i]);
}
return 0;
}
思路:排序方法基本与交换法一致。一共排n次,从后面开始把最小的依次交换
3交换法排序
#include<stdio.h>
int main()
{
int i,j;
int iArray[10];
int n = 10;
int temp = 0;
while(n--)
{
scanf("%d",&iArray[9-n]);
}
for(i=0;i<9;i++)
{
for(j=i+1;j<10;j++)
{
if(iArray[i]>iArray[j])
{
temp = iArray[i];
iArray[i]=iArray[j];
iArray[j]=temp;
}
}
}
for(int i=0;i<10;i++){
printf("%d ",iArray[i]);
}
return 0;
}
思路:大循环排n个数就n-1次,小循环从大循环加1次开始。每次大循环,定一个最小值,从所定值后面所有的数与最小值比,小就交换再比再交换。
4 插入法排序
#include<stdio.h>
int main()
{
int i;
int iArray[10];
int n = 10;
int temp;
int pos;
while(n--)
{
scanf("%d",&iArray[9-n]);
}
for(i=1;i<10;i++)
{
temp = iArray[i];
pos = i-1;
while(pos>=0&&temp<iArray[pos]){
iArray[pos+1]=iArray[pos];
pos--;
}这里的这个while循环就是用来排数的,条件达成退出循环
iArray[pos+1]=temp;
}
for(int i=0;i<10;i++){
printf("%d ",iArray[i]);
}
return 0;
}
思路:从第2个元素开始插,如果第二个元素的索引大于等于0且第二个元素小于初始的第一个元素。则让第二个元素排排后面。第3个元素与第二个元素比较。比他大则排后面,小的话还要与第一个元素比较,打则排第2,小则排第一。
5:折半法排序
#include<stdio.h>
void CelerityRun(int left,int right,int array[])
{
int i,j;
int middle,temp;
i=left;
j=right;
middle = array[(left+right)/2];
do{
while((array[i]<middle)&&(i<right)){
i++; //等于middle也会退出
}
while((array[j]>middle)&&(j>left))
j--;
if(i<=j)
{
temp = array[i];
array[i] = array[j];
array[j] = temp;
i++;
j--;
}
}while(i<=j);
if(left<j)
CelerityRun(left,j,array);
if(right>i)
CelerityRun(i,right,array);
}
int main()
{
int iArray[10];
int n = 10;
while(n--)
{
scanf("%d",&iArray[9-n]);
}
CelerityRun(0,9,iArray);
for(int i=0;i<10;i++){
printf("%d ",iArray[i]);
}
return 0;
}
思路,先分两半,左边一次循环,右边一次循环。左边时,存在比中间值大的则交换中间值和它的位置。右边时,存在比中间值小的,则交换中间值和其位置。等全部元素循环完后,以左半边为准,再次分成两半,同理右半边也分成两半。直到递归结束。
28 字符串函数
strcpy(目的字符数组名,原字符数组名)复制
字符串结束标志也会被复制
目的数组要足够大,原字符数组可以是字符串,不能用赋值语句将一个字符串赋给一个字符数组,但是可以以字符串初始化。
strcat(目的字符数组名,原字符数组名) 连接
把原字符数组的字符串连接到目的字符数组后面,并且删掉目的字符串数组的结束标志’\0‘
目的字符数组应该足够大,否则可能导致连接不上。
strcmp(字符数组名1,字符数组名2)比较
字符串1=字符串2 返回0
字符串1>字符串2 返回正数
字符串1<字符串2 返回负数
#include<stdio.h>
int main()
{
char user[20]={"mrsoft"};
char password[20]="mrkj";
char ustr[20],pwstr[20];
int i=0;
while(i<3)
{
printf("请输入用户名字字符串:\n");
gets(ustr);
printf("请输入密码字符串:\n");
gets(pwstr);
if(strcmp(user,ustr)!=0)
printf("用户名错误!\n");
else
{
if(strcmp(password,pwstr)!=0)
printf("密码错误!\n");
else
{
printf("登录成功!\n");
break;
}
}
i++;
if(i==3)
{
printf("三次机会用尽,请10min后再次尝试!\n");
}
}
return 0;
}
strupr(字符串)将小写字母转换成大写字母
strlwr(字符串)将大写字母转换成小写字母
strlen(字符数组名)获得字符串长度
可以使用time.h和localtime结合获取系统时间和日期。
29:函数
构成c程序的基本单元是函数。函数中包含程序的可执行代码。
每个c程序的入口和出口都位于main函数之中
一个源文件有一个或多个函数组成,一个源程序文件是一个编译单位,以源程序为单位进行编译。
30:函数的定义
函数头
返回值类型:返回值可以是某个c数据类型
函数名:唯一存在,准寻标识符命名法
参数表:参数表可以有变量也可以没有变量
函数体
局部变量的声明和函数的可执行代码
一个函数的定义分为函数头和函数体两个部分
返回值类型 函数名(参数列表)
{
函数体(函数实现特定功能的过程)
}
函数分为 有参函数,无参函数,空函数。
在程序中编写函数时,要先对函数进行声明,再对函数进行定义。
#include<stdio.h>
/*函数的声明*/
void ShowNumber(int iNumber);
int main()
{
...
return 0;
}
/*函数的定义*/
void ShowNumber(int iNumber)
{
...
}
如果将函数的定义放在调用函数的前面就不需要进行声明
31:返回语句
return 0;
利用返回语句能立即从所在的函数中退出,即返回到调用的程序中去。
返回语句能返回值,即将函数值赋给调用的表达式中。
返回值:return语句后面的括号可以省略,return0 == return(0)
如果函数值的类型和return语句中的表达式的值不一致,则以函数返回值的类型为准。数值型数据可以自动进行数值转换,即定义的返回值类型决定最终返回值的类型
32:函数参数
形式参数:在定义函数时,函数名后面括号里的变量名称作形式参数。在函数调用前,传递给函数的值将被复制到这些形式参数中。
实际参数:在调用一个函数时,函数括号里的参数为实际参数。函数的调用者提供函数的参数叫实际参数。
数组做函数参数:数组作为参数进行传递时,不同于标准的赋值调用参数传递方法。当数组作为函数的实参时,传递的是数组的地址,而不是将整个数组赋值到函数中,当用数组名作为实参调用函数时,指向该数组的第一个元素的指针就被传递到函数中
数组元素作为函数参数:与变量作为函数实参一样的用法。
数组名作为函数参数:此时实参和形参都应该使用数组名。
可变长度数组作为函数参数:可以将函数的参数声明成长度可变的数组。
使用指针作为函数参数:将函数参数声明为一个指针,而指针就是一个地址。
void Function(int* pPoint);
main(int argc,char* argv[])
两个特殊的内部形参argc和argv是用来接收命令行实参的,这是只有main函数才有的参数。
argc参数包存命令行的参数个数,是整型变量。这个参数的值至少是1,因为至少程序的名就是第一个实参
argv参数是一个指向字符指针数组的指针,这个数组中的每一个元素都指向命令行实参。所有命令行实参都是字符串,任何数字都必须有程序转变成一个合适的格式
#include<stdio.h>
int main(int argc,char* argv[])
{
printf("%s\n",argv[0]);
return 0;
}
33:函数的调用
函数语句调用、函数表达式调用、函数参数调用
函数语句调用:作为一个语句被调用
Display();
函数表达式调用:函数出现在一个表达式中,这时要求函数必须带回一个确定的值,而在这个值作为参加表达式运算的一部分
iResult=iNum3*AddTwoNum(3,5);
函数参数的调用:函数调用作为一个函数的实参,也就是将函数返回值作为实参,传递到函数中使用。
iResult=AddTwoNum(10,AddTwoNum(3,5));
嵌套调用
在c语言中,函数的定义都是互相平行、独立的。在定义一个函数时,一个函数体内不能包含定义的另一个函数。不允许嵌套定义!
函数嵌套就是可以在一个函数的定义中调用另一个函数作为定义的一部分。而不是再次定义一个函数。
递归调用
c语言函数都支持递归,也就是说,每个函数都可以直接或间接地调用自己。
34:内部函数和外部函数
函数是c语言中最小的单位,可以把一个或多个函数保存为一个文件。当一个源程序由多个源文件组成时,可以指定函数不被其他文件调用。这样c语言又把函数分为内部函数和外部函数
内部函数:只希望被所在的源文件使用,内部函数又叫做静态函数,
static 返回值类型 函数名(参数列表)
static int Add(int iNum1,int iNum2);
使用内部函数的好处:不同开发者可以分别编写不同的函数,不必担心所使用的函数与其他函数重名,内部函数只在所在的源文件内使用
外部函数:与内部函数相反,用extern修饰
extern int Add(int iNum1,int iNum2);
这样Add函数就可以被其他源文件调用,在c语言中如果不指明函数类型,默认是外部函数,因此可以省略extern
35:局部变量和全局变量
作用域包含局部作用域和全局作用域,局部变量具有局部作用域,全局变量具有全局作用域。
局部变量:在一个函数内部定义的变量,无法被其他函数使用,函数的形式参数也属于局部变量,在语句块内声明定义的变量仅在该语句块内部起作用,也包括嵌套的子语句块。

局部变量的屏蔽作用:在一个代码块里要是存在相同名称的局部变量,遵循局部变量优先的原则。
全局变量:如果一个变量在所有函数的外部声明,他就是全局变量,全局变量可以在程序的任何位置进行访问。全局变量不属于某个函数,而是属于整个源文件。如果外部文件要使用,则要用extern关键字进行引用修饰。
36:函数应用
编译系统通常会提供一些库函数供用户调用。
1.abs函数
int abs(int i),求整数的绝对值
2.labs函数
long labs(long n); 求长整数的绝对值
3.fabs函数
double fabs(double x);求 实型的绝对值
4.sin函数
double sin(double x);求正弦值
5.cos函数
double cos(double x);求余弦值
6.tan函数
double tan(double x);求正切
ceil函数:向上取整。ceil(12.56)=13.000~。包含在头文件math
double ceil(double ceil);
#include<stdio.h>
#include<math.h>
int main()
{
double fxsin=0.5;
printf("%lf",sin(fxsin));
}
包含在头文件ctype.h里
7.isalpha函数
int isalpha(int ch);判断输入的字符是否是字母
8.isdigit函数
int isdigit(int ch);判断输入的字符是否为数字
9.isalnum函数
int isalnum(int ch);判断是否为字母或数字
37:地址与指针
变量的地址是变量和指针二者之间连接的纽带,如果一个变量包含了另一个变量的地址,则可以理解成第一个变量指向第二个变量,所谓的指针变量就是指向一个变量地址的变量。把一个变量的地址赋给指针变量后,那么指针变量就指向该变量。
在程序代码中是通过变量名对内存单元进行存取操作的,但是代码经过编译后,已经将变量名转换为该变量在内存中存放的地址,对变量的存取都是通过地址进行的。
指针变量
专门用来存放一个变量的地址的变量。
类型说明 *变量名 :*表示该变量是一个指针变量,变量名就是定义的指针变量名,类型说明该指针变量所指向的变量的类型
指针变量的赋值
指针变量同普通变量一样,使用之前不仅需要定义,而且需要赋予具体的值,未经赋值的指针禁止使用,给指针变量只能赋予地址。
c语言中提供了地址运算符“&”来表示一个变量的地址 & 变量名
int a;
int *p= &a;
or
int a;
int *p;
p=&a;
未赋值的指针变量的值通常是不确定的,它会包含一个不确定的内存地址,这被称为“野指针”(dangling pointer)。野指针可能指向任何地方,包括没有分配给程序的内存地址,或者以前分配给其他变量的内存地址。
使用野指针可能会导致程序不稳定,因为它们可能会访问未知内存区域,导致未定义的行为和程序崩溃。为了避免野指针的问题,应该始终在使用指针之前将其初始化为合适的值,或者在不再需要指针时将其设置为NULL
int *ptr = NULL; // 或 int *ptr = 0;
指针变量的引用
引用指针变量是对变量进行间接访问的一种形式
* 指针变量
“&”和“*”运算符:运算符“&”是一个返回操作数地址的单目运算符,叫做取地址运算符
*叫做指针运算符,作用是返回指定地址内变量的值,专门与指针(地址)连用
这里我理解为*p就是返回p指向地址的值,而指向的地址的值就是变量名的本质,定义一个变量的时候 例如 int a=10或int a;a 等价于10或0的另一个当前的名字。而这个名字的地址存在p内
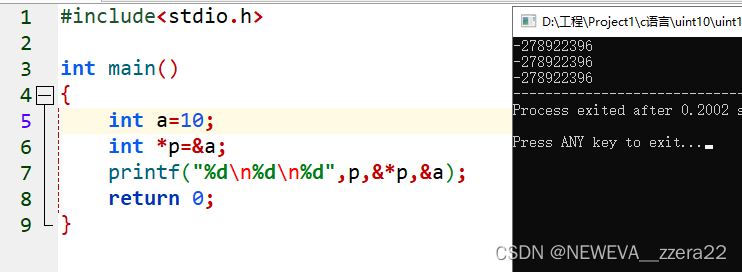
图示显示了如此。指针 = &变量 = &*指针
p=&i;
q=*p;
"&*"和“&”的区别:
int a;
int *p=&a;
假如有&*p,意思是对p得到a,再对a取地址得到a的地址,而&a就是取变量a的地址
*p是返回p指向地址变量的值,然后用&取该值的地址
*&的用法
&用来取地址,*用来解出地址内存放的值。
指针自加自减运算
指针的自加自减不同于普通变量的自加自减运算,例如一个整型变量i在内存中占4个字节,指针p是指向i的地址的,这里的p++不是简单的地址加1,而是指向下一个存放基本整型数的地址,就是p++等于p的值增加4。指针的自增自减与指针指向变量的类型有关也就是和指针类型有关。
38:数组与指针
系统中需要提供一段连续的内存来存储数组中的各个元素,内存都有地址。如果把数组的地址赋给指针变量,就可以通过指针变量来引用数组。
一维数组与指针
当定义一个一维数组时,系统会在内存中为该数组分配一个存储空间,其数组的名称就是数组在内存中的首地址。如果再定义一个指针变量,并将数组的首地址传给指针变量,则该指针就指向了这个一维数组。
int a[10];
int *p=a;
这里的a代表数组a的首地址
a==&a[0];
通过指针的方式引用一维数组中的元素
int *p,a[5];
p=&a;
C语言中地址的大小(字长)不是固定的,它取决于底层硬件和操作系统的体系结构。在大多数32位系统中,地址通常是4个字节,而在64位系统中,地址通常是8个字节。
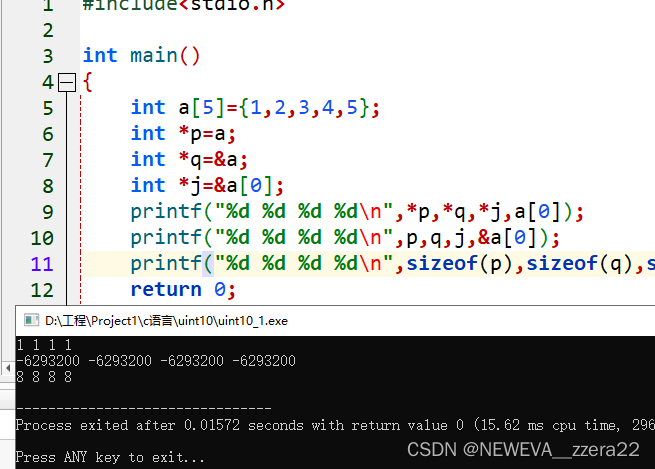
从上图可以看出取数组首地址可以有三种方式 &a=&a[0]=a;
二维数组与指针
&a[0][0]既可以看作数组0行0列的首地址,也可以看作是二维数组的首地址。a[0]+n代表第1行第n列的地址
,而a[0]代表第0行第0列的地址,在这里可以看出对二维数组而言,任何一维的表达都是一个地址而不是一个值。所以可以得出
&a=&a[0]=&a[0][0]=a;如下图所示(错了)。
只是输出来的值一样,但变量类型不同。a[1]是int *类型,而&a[1]是int (*)[4]类型。因此同样加1的时候,偏移不一样。前者只移一位,而后者要移动四维,即到二位数组的下一行。对于二维数组a[m][n]而言,a和a[0]都是首地址等价于&a[0][0],不同之处在于a+1移动至下一行,而a[0]+1移动至下一列。即a+1指针指到a[1][0]处,而a[0]+1指针指到a[0][1];
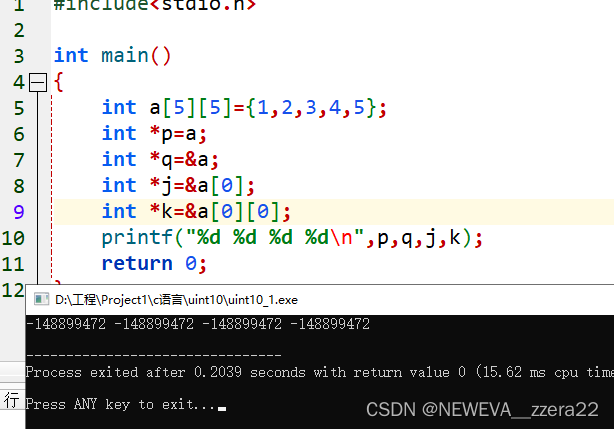
&a[n]代表第n行的首地址。&a和a代表数组首地址。a+n(n是一个整数)这个也代表数组第n行的首地址
等价与&a[n]
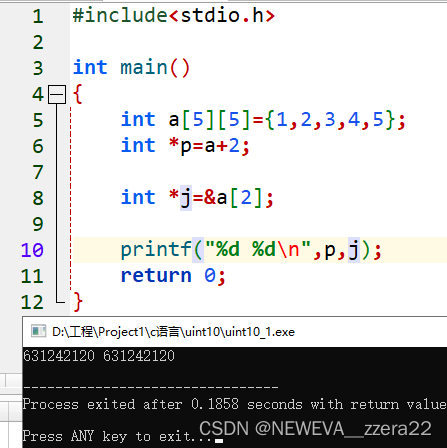
*(*(a+n)+m):a+n表示第n行首地址,一个解引用符变成a[n],然后加m代表第n行第m列地址,再加个*
变成对应的值。回忆前面的内容,发现假如 int *p=a;则*p就等于a,而a是一个值。*号只能对地址操作。
这里我理解的是对*(a+n)得到的是二层地址中的第一层,即行地址。再解一次**(a+n)得到行地址对应的值。
二维数组要取值的话,对于直到行列地址的取一次*就可以,不知道列地址的要取两次*。与此同时*a[n]得到的就是第n行首地址的值!
int a[5][5];
*&a[4][4]=**a[4]
*(*(a+n)+m)=*(a[n]+m)
可以看出这几个表达都能表示数组a的第1行首地址。
更进一步,我们发现下面6种模式都是表示数组a的第1行地址

&*可以抵消掉。只保留原来的地址。
对于二维数组而言
*(a+n)==a[n] !!!!!!!!!!!
二维数组可以由指针数组定义得 int (*a)[5],定义了一个整型指针数组,数组里装着5个整型指针。而这5个整型指针可以是5个整型一维数组。
代表 这个数组由n列。等同于这样的形式 int a[m][5];int(*p)[5]. p=&a[0];
39 字符串与指针
可以通过两种方式访问一个字符串,其一通过字符数组存放一个字符串,其二通过字符串指针指向一个字符串。
char *string="hello world";
char *string;
string = "hello world";
char string[]="hello world";
字符串数组
字符串数组区别于字符数组,相当于二维字符数组吧
char country[5][10]=
{
"China","japan","Russia","Germany","Switzerland"
};
这里也需要考虑字符串结束标识所占的一个字节
指针数组
一个数组,其元素均为指针类型数据,称为指针数组。也就是说,指针数组中的每一个变量都是指针变量。
类型名 *数组名[数组长度]
char *country[]=
{
"China","japan","Russia","Germany","Switzerland"
};
指向指针的指针
一个指针变量可以指向整型变量、实型变量、字符型变量,当然也可以指向指针类型变量。称之为指向指针的指针变量:二重指针
类型标识符 **指针变量名;
int **p;
int *(*p);
40:指针变量做函数参数
我们定义的函数传递的形参又叫做值传递,是实参的copy属于函数内部局部变量,函数执行完成后自动销毁,无法对实参产生影响。通过指针传递实参的地址,不仅可以改变外部实参的值,而且不用再创造一份实参的copy,减少值传递带来的开销。
41:返回指针值的函数
指针变量可以指向一个函数。函数在编译的时候会被分配一个地址,该入口地址就称为函数的指针。可以用一个指针变量指向函数,然后通过该指针变量调用此函数。
函数指针的用法
#include <stdio.h>
// 声明一个函数,该函数接受两个整数参数并返回它们的和
int add(int a, int b) {
return a + b;
}
// 声明一个函数,该函数接受两个整数参数并返回它们的差
int subtract(int a, int b) {
return a - b;
}
int main() {
int result;
// 声明一个函数指针,该指针可以指向接受两个整数参数并返回整数的函数
int (*operation)(int, int);
// 将函数指针指向 add 函数
operation = add;
// 使用函数指针调用 add 函数
result = operation(5, 3);
printf("5 + 3 = %d\n", result);
// 将函数指针指向 subtract 函数
operation = subtract;
// 使用函数指针调用 subtract 函数
result = operation(5, 3);
printf("5 - 3 = %d\n", result);
return 0;
}
一个函数可以带回一个整型值,实型值、字符值等,也可以待会指针类型数据,即地址。其概念与之前介绍的类似,只是带回的值是指针类型而已。返回指针值的函数称为指针函数。
定义指针函数如下:
类型名 *函数名(参数列表);
int *fun(int x,int y)
返回的指针指向一个整型变量。
#include<stdio.h>
int prem;
int *change(int a,int b)
{
int *p=&prem;
prem =a*b;
return p;
}
int main()
{
int a=2,b=3;
int *p;
p = change(a,b);
printf("%d\n%d",*p,prem);
return 0;
}
42:指针数组作main函数的参数
main函数是所有程序的入口,由系统调用。当处于操作命令状态下,输入main函数所在的文件名,系统即调用main函数。
main函数的第一行一般是
main()
而main函数是可以带参的,在一维数组那里介绍过。
main(int argc,char* argv[])
从参数看,包含一个整型和一个指针数组。当一个c的源程序经过编译、链接后,会生成一个扩展名是.mp4的可执行文件,这是可以在操作系统下直接运行的文件。对于main函数来说,其实际参数和命令是一起给出的,也就是一个命令行包括命令名和需要传给main函数的参数。
命令行 参数1 参数2 .。。。参数n
d:\debug\1 hello hi yeah
命令行中的命令就是可执行文件的文件名,如d:\debug\1,命令行和其后所根的参数之间必须用空格分隔。
如 file1 happy bright glad
file1.c经过编译、链接产生一个file1.mp4的文件。其后跟了3个参数。argc记录了命令行中命令与参数的个数4,指针数组的大小由参数的值决定,即char*argv[4]
43:结构体定义
一些基本的数据类型:整型、字符型、数组这类构造类型,在一些情况 下,这些基本的类型是不能满足编写者的使用需求的。因此程序员可以将有关的变量组织起来,定义成一个结构structure,表示一个新的类型。程序可以像处理基本类型一样处理结构
结构体是一种构造类型,它是由若干成员组成。其成员可以是一个基本数据类型,也可以是一个构造类型。既然结构体是一种新的类型,就需要先对其进行构造,这里称这种操作作为声明一个结构体。
假如要构造商品这个类型据需要有 :产品名称、形状、颜色、功能、价格、产地。
声明结构体时使用的关键字是 struct
struct 结构体名
{
成员列表
};
末尾要加分号,跟定义变量一样。
struct Product
{
char cName[10];
char cShape[20];
char cColor[10];
char cFunc[20];
int iPrice;
char cArea[20];
};
结构体变量的定义
1:先声明结构体类型,再定义变量
struct Product p1;
定义结构体变量后,系统会为其分配内存单元!如product1在内存中占用 (10+20+10+20+4+20)=84个字节
2:在声明结构类型的同时定义变量
为了使规模较大的程序更便于修改和使用,常常将结构体类型的声明放在一个头文件中,这样在其他源文件中如果需要使用该结构体类型,则可以使用#include命令将该头文件包含到源文件中。
struct 结构体名
{
成员列表;
}变量名列表;
这里可以定义多个变量。
struct Product
{
char cName[10];
char cShape[20];
char cColor[10];
char cFunc[20];
int iPrice;
char cArea[20];
}product1,product2;
3:直接定义结构体变量
struct
{
成员列表;
}变量名列表;
struct
{
char cName[10];
char cShape[20];
char cColor[10];
char cFunc[20];
int iPrice;
char cArea[20];
}product1,product2;
可以看出这里没有给结构体取名。
类型与变量是不同的,不能对类型进行赋值。比如 int iInt;可以对变量iInt赋值,但不能对int类型赋值。
在编译时,只对变量分配空间,类型是不分配空间的。
44:结构体变量的引用
定义结构体类型变量以后,当然可以引用这个变量,但不能直接将一个结构体的变量作为一个整体进行输入和输出。例如不能将produc1和product2进行以下输入和输出
printf("%s%s%s%s%d%s",product1);
printf("%s%s%s%s%d%s",product2);
要对结构体变量进行赋值、存取或运算,实质上就是对结构体进行成员操作。每一个结构体变量都有他自己的结构体成员。
结构体变量名.成员名
在引用结构体成员时,可以在结构体的变量名的后面加上成员运算符“."
product1.cName="lbwnb";
product1.iPrize=666;
上面的赋值语句就是对结构体变量product1的成员cName和iPrize变量进行赋值。
如果成员是一个结构体的话,这时就要使用若干个成员运算符,一级一级地找到最低一级的成员。只能对最低级的成员进行赋值操作!
student.birthday.year=2000;
不能使用student.birthday来访问student里的birthday,因为birthday本身也是一个结构体。只能操作最低级的成员
结构体变量的成员可以像普通变量一样进行各种运算。
product1.iPrize=product1.iPrize+500;
product1.iPrize++;
注意,这里的优先级问题,.的优先级最高,实际是product1.iPrize的成员进行自加操作,而不是iPrize自加。
45:结构体类型的初始化
跟其他基本类型一样可以在定义结构体变量时指定初始值。
struct Student
{
char cName[20];
char cSex;
int iGrade;
}student1={"lbw",'m',0};
or Student student2={"lbw2","w",1};
46:结构体数组
定义一个结构体数组跟定义一个结构体变量的区别就是变量的位置变成了数组。
struct 结构体名
{
成员列表;
}数组名;
struct Student
{
char cName[20];
char cSex;
int iGrade;
}student[5];
这种定义结构体数组的方式是声明结构体类型的同时定义结构体数组。
还可以直接定义结构体数组
struct Student student1[5];
数组中的各数据在内存中是连续存储的
初始化结构体数组
struct 结构体名
{
成员列表;
}数组名={初始值列表};
struct Student
{
char cName[20];
char cSex;
int iGrade;
}student[5]={{"wangwu",'w',12306},...,{"zhangsan",'m',12}};
为数组进行初始化时,最外层的大括号表示所列出的是数组中的元素。每一个元素都是结构体类型,
所以每一个元素也使用大括号,其中包含每个结构体元素成员数据
在定义数组student时也可以不指定数组中的元素个数,编译器会根据数组后面的初始化值列表中给出的
元素个数,来确定数组中元素的个数。
struct Student student[5]={...};
47:结构体指针
一个指向变量的指针表示的是变量所占的内存的起始地址。如果一个指针指向结构体变量,那么该指针指向的是结构体变量的起始地址。同样,指针变量也可以指向结构体数组中的元素。
指向结构体变量的指针
定义结构体指针的一般形式如下
结构体类型 *指针名;
struct Student *pStruct;
使用指向结构体变量的指针访问成员有两种方法:
1:(*pStruct).成员名 *pStruct表示指向结构体的变量,因此使用点运算符可以应用结构体中的成员变量。
*pStruct一定要使用小括号括起来,因为点运算符的优先级是最高的,如果不使用括号就会先执行点运算然后执行*运算
声明结构体的位置可以在main函数内也可以在main函数外。
2:使用指向运算符引用结构成员
pStruct->成员名;
以下3种方式等价 :student.成员名 (*pStruct).成员名 pStruct->成员名
在使用“->"引用成员时,要分析以下情况:
1:pStruct->iGrade,表示指向结构体变量中的成员iGrade的值
2:pStruct->iGrade++,表示指向结构体变量的成员iGrade先使用,然后加1
3:++pStruct->iGrade,表示指向结构体变量的成员iGrade的值加1然后再使用。
指向结构体数组的指针
结构体指针变量不但可以指向一个结构体变量,话可以指向结构体数组,,此时指针变量的值是结构体数组的首地址。
结构体指针变量也可以直接指向结构体数组中的元素。这时指针变量的值就是该该结构体数组元素的首地址。
struct Sudent* pStruct;
struct Student student[5];
pStruct=student;
数组不使用下标时表示的是数组第一个元素的地址,所以指针指向的是数组的首地址。如果要指向第3个元素
pStruct=&student[2];
!!!!!!!!!!!!!!!!
(++pStruct)->Number 与 (pStruct++)->Number 是不一样的,前者先使指针移向下一位元素地址,然后取得该元素的成员值
后者先取该地址元素的成员的值,然后再移向下一个元素的地址
结构体作为函数参数:使用结构体作为函数的参数有3种形式:
1 使用结构体变量作为函数参数
void Display(struct Student stu);
使用结构体变量做函数的实参时,相当于值传递。
2 使用指向结构体变量的指针作为函数参数
void Display(struct Student *stu);
使用指向结构体变量的指针作为参数时,是将结构体变量的首地址传递,并无变量副本的创建。
在实际应用的时候,为了直观地看出函数传递的参数是结构体变量的指针,定义了一个指针变量指向结构体。实际上,可以直接传递
结构体变量的地址作为函数的参数 即Display(&student);
3 使用结构体变量的成员作为函数参数
使用这种方式为函数传递参数与普通的变量作为实参一样,都是值传递
Display( student.fScore[0]);
48:包含结构的结构
就是一个结构体类型的定义中它的成员不仅有基本类型还包含结构体类型,例如
struct date
{
int year;
int month;
int day;
};
struct People
{
char name[20];
struct date birthday;
}people={"yamaha",{2000,2,2}};
这里要注意一个结构体里定义的成员,必须是具体的,就是如果包含另一个结构体这个结构体必须是个变量,而不能是一个结构体类型
49:链表
数据是信息的载体。数据结构是指数据对象及其中的相互关系和构造方法。在数据结构中有一种线性存储结构称为线性表。
链表是一种常见的数据结构。使用数组存放数据时,会有一个问题,就是数组大小问题,如果设置小了就会导致数组越界问题,设置大了就会导致资源浪费问题。所以这时候诞生了链表,其存储元素的个数是不受限定的。
在链表中有一个头指针变量,这个指针存放一个地址。head头节点指向第一个元素,第一个元素中的指针又指向第二个元素。以此类推。最后一个元素的指针指向空。这就构成了一个链表。
在链表这种结构中,必须利用指针才能实现,因此链表中的节点应该包含一个指针变量来保存下一个节点的地址。
struct Student
{
char cName[20];
int iNumber;
struct Student* pNext; /*指向下一个节点的指针*/
}
可以看到学生的姓名和学号属于数据部分,而pNext就是指针部分,用来保存下一个节点的地址。
当有新的节点添加到链表中时,原来最后一个节点的指针将保存新添加节点的地址,而新节点的指针指向空(NULL),不用担心链表的长度会超出范围。
50:创建动态链表
链表的创建是一个动态的过程,动态的创建一个节点时,要为其分配内存。动态创建链表需要用到一些内存管理函数。
1:malloc函数
void *malloc(unsigned int size);
该函数的功能是在内存中动态的分配一块size大小的内存空间。malloc函数会返回一个指针,该指针指向分配的内存空间,如果出现错误就返回NULL
2:calloc函数
void *calloc(unsigned n,unsigned size);
该函数的功能是在内存中动态分配n个长度为size的连续内存空间数组。calloc函数会返回一个指针,该指针指向动态分配的连续内存空间地址。当分配失败时返回NULL
3:free函数
void free(void *ptr)
该函数的功能是使用由指针ptr指向的内存区,使部分内存能被其他变量使用。ptr是最近一次调用calloc和malloc函数返回的值
创建动态链表过程:
1.创建节点结构(一个节点包含数据部分和指向下一个节点的指针部分)
struct Student
{
char cName[20];
int iNumber;
struct Student *pNext;
};
2.定义一个Creat函数,用来创建链表
int iCount; //全局变量表示链表长度
struct Student* Creat()
{
struct Student* pHead=NULL;
struct Student* pEnd,*pNew;
iCount=0;
pEnd = pNew=(struct Student*)malloc(sizeof(struct Student));
printf("please first enter Name,then Number\n")
scanf("%s",&pNew->cName);
scanf("%d",&pNew->iNumber);
while(pNew->iNumber!=0)
{
iCount++;
if(iCount==1)
{
pNew->pNext=pHead;//指向NULL
pEnd=pNew;
pHead=pNew;
}
else
{
pNew->pNext=NULL:
pend->pNext=pNew;
pEnd=pNew;
}
pNew=(struct Student*)malloc(sizeof(struct Student));
scanf("%s",&pNew->cName);
scanf("%d",&pNew->iNumber);
}
free(pNew);
return pHead;
}
iCount是个全局变量表示链表中节点个数。pHead表示头指针,pEnd用来指向原来的尾节点,pNew用来指向新节点。
使用malloc分配内存(内存大小为一个结构体变量大小,返回这个结构体变量的首地址),先用pEnd和pNew都指向第一个分配的内存(给他俩分配刚开辟的内存空间首地址)
在while循环内,iCount++表示节点的增加,判断加入的节点是不是第一个加入的节点。如果是第一次加入执行if内的
因为第一次加入节点时,链表内没有节点,新节点就是首节点,也是最后一个节点。新加入的节点要符合尾节点指针特性指向NULL,即为pHead指向。然后pEnd就指向这个新加入的节点。
else语句内,是实现链表中已存在节点时的操作。将新加入节点的pNew的指针指向NULL,然后将原来最后一个节点的指针指向新节点,最后将pEnd的指针指向新加入的节点。
输出链表
void Print(struct Student* pHead)
{
struct Student* pTemp;
int iIndex=1;
printf("----the List has %d members:----\n",iCount)
printf("\n");
pTemp=pHead;
while(pTemp!=NULL)
{
printf("the NO%d member is:\n",iIndex);
printf("the name is:%s\n",pTemp->cName);
printf("the number is:%d\n",pTemp->iNumber) ;
printf("\n");
pTemp=pTemp->next;
iIndex++;
}
}
Printf()函数用来将链表中的数据打印出来。在pHead表示一个链表的头节点。在函数定义中定义一个临时指针pTemp用来循环,定义一个iIndex用来表示链表中的序号。当所拥有的指针指向NULL时,循环结束
#include<stdio.h>
#include<stdlib.h>
int iCount;
struct Student /*创建学生结构*/
{
char cName[20];
int iNumber;
struct Student* pNext; //节点内指针,指向下一个节点。
};
struct Student* Creat();
void Print(struct Student* pHead);
int main()
{
struct Student* pHead;
pHead = Creat();
Print(pHead);
return 0;
}
struct Student* Creat()
{
struct Student* pHead=NULL;
struct Student* pNew,*pEnd;
iCount=0;
pNew=pEnd=(struct Student*)malloc(sizeof(struct Student));
printf("请输入学生姓名后,输入学号:\n");
scanf("%s",&pNew->cName);
scanf("%d",&pNew->iNumber);
while(pNew->iNumber!=0)
{
iCount++;
if(iCount==1)
{
pNew->pNext=pHead;
pHead=pNew;//pHead是头节点的意思 经过自己敲了一遍代码发现这里易错
pEnd=pNew;
}else
{
pNew->pNext=NULL;
pEnd->pNext = pNew;
pEnd=pNew;
}
printf("请输入学生姓名后,输入学号:\n");
pNew=(struct Student*)malloc(sizeof(struct Student));
scanf("%s",&pNew->cName);
scanf("%d",&pNew->iNumber);
}
free(pNew);
return pHead;
};
void Print(struct Student* pHead)
{
struct Student* pTemp;
int iIndex=1;
printf("----this List has %d members\n",iCount);
printf("\n");
pTemp=pHead;
while(pTemp!=NULL)
{
printf("the NO%d member is:\n",iIndex);
printf("the name is %s\n",pTemp->cName);
printf("the number is %d\n",pTemp->iNumber);
printf("\n");
pTemp=pTemp->pNext;
iIndex++;
}
};
易错点:
1创建一个结构体类型,这个类型也是节点的意思,要包含自身要带的数据和指向下一个节点的指针.
2在创建链表的时候,初始化头指针为空,因为没有节点。还需要两个指针辅助节点操作。令其在创建链表之前都指向新开辟的内存首地址。pNew和pEnd一个指向新创建的节点,一个指向尾节点
3头节点,顾名思义他是一个节点,而不是一个指针,他是结构体变量。
4在创建第一个节点的时候,给节点成员赋完值后,指向问题,第一个节点也是最后一个节点。新创建的节点准寻尾节点的指针指向NULL原则,头指针指向的头节点,即pHead=pNew,他俩的顺序不能搞反。自右向左,因为是新节点从右边加入。指向尾节点的指针pEnd指向新节点。pEnd=pNew。
5在已经存在节点的情况下,新节点的指针指向NULL,未加入新节点之前的尾节点指针指向新节点pEnd->next=pNew。尾节点变更pEnd=pNew;
6打印中注意索引从1开始。
7创建和打印里,传递的参数都是结构体指针,就是头指针,而头指针存的是链表的首地址。
51:链表相关操作
链表还应具有插入删除节点的功能。
链表的插入
struct Student* Insert(struct Student* pHead)
{
struct Student* pNew;
printf("----Insert member at first----\n");
pNew=(struct Student*)malloc(sizeof(struct Student));
scanf("%s",&pNew->cName);
scanf("%d",&pNew->iNumber);
pNew->pNext = pHead;
pHead=pnew;
iCount++;
return pHead;
}
易错点:感觉无论是头插还是尾部写,都遵循先把右边的接上,再管左边。这里就是让新节点的指针指向原来的头节点。然后让整个链表头指针指向新节点。相当于加了一个节点让链表连上了,但是此时链表头节点的地址变了,然后让头指针指向它就完成了。如果颠倒顺序会导致头指针指向新节点,但是新节点的指针又指回头指针形成死循环
链表的删除
要删除一个节点,首先要找到这个节点的位置。把它左边右边剪断,让左边节点指针指向右边节点。
void Delete(struct Student* pHead)
{
int i;
struct Student* pTemp;
struct Student* pPre;
pTemp=pHead;
pPre=pTemp;
printf("----delete NO%d member----\n",iIndex);
for(i=1;i<iIndex;i++)
{
pPre=pTemp;
pTemp=pTemp->pNext;
}
pPre->pNext=pTemp->pNext;
free(pTemp);
iCount--;
}
易错点:利用两个指针,来存放一个节点地址和它下一个节点地址,而要删除的就是这个下一个节点,让它的前一个节点的指针指向要删除节点指针指向的节点就完成了连接。有个bug这种方式不能删除首节点。
52:共用体
共用体看起来很像结构体,只不过关键字变成了union
结构体定义了一个由多个数据成员组成的特殊类型,而共用体定义了一块为所有数据成员共享的内存。
union 共用体名
{
成员列表
}变量列表;
union DataUnion
{
int iInt;
char cChar;
float fFloat;
}variable;
其中variable为定义的共用体变量
union DataUnion variable;
结构体变量大小是成员大小之和,而共用体是最大的那个。
上面那个就是以float为准;
共用体变量的引用
共用体变量.变量名
不能直接引用共用体变量 printf("%d",variable);在程序内改变共用体的一个成员,其他成员也会随之改变
加入令iInt=97,那么cChar就变成了a;
共用体的初始化
对共用体初始化只需要初始化1个值就可以,其类型必须与共用体第1个成员变量类型一致。
共用体特点:
1同一内存段可以用来存放几种不同类型成员,但每次只能存放一种,也就是共用体成员只有一个起作用
2共用体变量中起作用的是最后一次存放的成员,加入新成员,原有的成员就是去作用
3共用体变量的地址和它的各成员地址是一样的
4不能对共用体变量名赋值
53:枚举类型
利用关键字 enum可以声明枚举类型。使用该类型可以定义枚举类型变量,一个枚举类型变量包含一组相关的标识符,其中每个标识符都对应一个整数值,称为枚举常量。
enum Colors(RED,GREEN,BLUE);
Colors代表变量,括号内的标识符代表数值0,1,2.
每个标识符必须是唯一的,且不能用作用域内相同标识符重名。
enum Colors(RED=1,GREEN,BLUE);
这样就变成了1,2,3
54:位运算
位运算符
& 按位与
| 按位或
~ 取反
^ 按位异或
<< 左移
>> 右移
010 & 111 =010
111 & 000 =000
按位与,同1为1,有0为0
按位与的作用就是清零,将原数中为1的位置为零,只需将与其与的操作数对应位置置0其他位置为1
000 | 111 = 111
101 | 000 = 101
按位或,有1为1,全零为0
按位或的作用是一个数对应位置为1,按位或一个对应位置为1其余位置为0的数就行
~111 = 000
~000 = 111
取反,0变成1,1变成0
取反是按位取反,而不是取-号
000 ^ 111 = 111;
101 ^ 101 = 000;
异或,相同取0.相反取1
使特定位翻转,如果将107的后7位翻转,只需要异或一个后七位都是1的数即可。
将x,y的值互换可以不经过中间变量,直接三次异或
x = x^y;
y = y^x;
x = x^y;
异或运算经常被用到一些简单的加密运算中。
左移运算符
<<是吧左边运算数的各二进制位全部左移若干位
a<<2;
实际上左移1位,相当于该数乘以2,左移2位相当于乘2^2=4.这种情况只使用与左移出的位不是1的情况,假如一个以一个字节8位存储的数 64 0100 0000,左移1位变成128,左移两位变成0了!
右移运算符
>>是吧左边运算数的各二进制位全部左移若干位
a>>2;
与左移差不多,但没有乘2的性质,但是要注意符号位的问题,当为正数时,最高位补0;为负数时最高位补0还是补1由操作系统决定。
55:循环移位
循环移位就是将移出的低位放到该数的高位,或者将移出的高位放到该数的低位。
将x的左端n位先放到z中的低n位
z=x>>(32-n);
将x左移n位,其后面的n位补0;
y=x<<n
将y与z进行按位或运算。
y=y|z;
假如长度为1个字节,8位
10110111 循环左移1位
z=0000 0001
y=0110 1110
y = y|z = 0110 1111;实现了循环左移1位
循环右移
将x的右端放到z中的高n位
z = x<<(32-n);
将x的左端右移n位,左边补n个零
y = x>>n;
将y与z进行或运算
y = y|z;
56: 位段
位段类型是一种特殊的类型,其所有成员都是以二进制单位定义的。
结构 结构名
{
类型 变量名1:长度;
类型 变量名2:长度;
...
}
一个位段必须被说明是int、unsigned或signed中的一种。
CPU的状态寄存器按位段类型定义如下:
struct status
{
unsigned sign:1;
unsigned zero:1;
unsigned carry:1;
unsigned parity:1;
unsigned half_carry:1;
unsigned negative:1;
}flags;
struct packed_data
{
unsigned a:2;
unsigned b:1;
unsigned c:1;
unsigned d:2;
}data;
位段说明
1:位段是一种结构类型,所以位段类型和位段变量的定义,以及对位段的引用均与结构类型的结构变量相同。
2:各个位段只占用定义大小的二进制位,如果某个位段需要表示多余两种的状态,也可以为该位段设置占用多个二进制位。
3:某一个位段要从另一个字节开始存放,可写成如下形式
struct status
{
unsigned a:1;
unsigned b:1;
unsigned c:1;
unsigned :0;
unsigned d:1;
unsigned e:1;
unsigned f:1;
}flags;
这样前三个和后三个不会存在相同的字节里
4:可以使每个位段占满一个字节,也可以不占满一个字节
5:一个位段必须存储在一个存储单元内,不能跨两个存储单元。如果本单元不够容纳某位段,则从下一个单元开始存储该位段
6:可以用%d,%x,%u,%o等格式输出位段
7:在数值表达式中引用位段时,系统将自动将位段转换为整数。
57:宏定义
预处理是C语言特有的功能,可以使用预处理和具有预处理功能是c语言与其他高级语言的区别之一。
预处理包含许多有用的功能,如宏定义、条件编译等
使用预处理功能便于程序的修改,阅读,移植和调试。也便于实现模块化程序设计。
不带参数的宏定义
#define 宏名 字符串
#表示这是一个预处理命令
宏名是一个标识符
字符串可以是常数、表达式、格式字符串等
#define PI 3.14159
宏定义不是C语句不需要在行尾加分号
宏名定义后,即可以称为其他宏定义中的一部分
#define SIDE 5
#define PERIMETER 4*SIDE
#define STANDARD "You are welcome to join us."
printf(STANDARD);
printf("This is STANDARD");该字符串内有宏名,但是不进行替换。
如果串长于一行,可以在行尾加”\“来续行。
#define命令出现在程序函数外面,宏名的有效范围为定义命令之后到此源文件结束
可以用#undef命令终止宏定义的作用域
#include<stdio.h>
#define TEST "this is an example";
int main()
{
printf(TEST);
#undef TEST;
//代码块 在下面的代码块中宏名就不起作用了。
return 0;
}
带参数的宏定义
#define 宏名(参数表)字符串
#define MIX(a,b) ((a)*(b)+(b))
宏定义时,参数要加括号。如果不加括号,则结果可能是正确的也可能是错误的。
假如a=10,b=7 结果是77,但是当a=10,b=3+4时结果变成 10*3+4+3+4=41
宏扩展必须使用括号来保护表达式中低优先级的操作符,以确保表达式能达到想要的效果。
如果MIX(a,b) 后边没加括号 则5*MIX(a,b)结果 5*(a)*(b)+(b);
说明
1 对带参数的宏展开,只是将语句中的宏名后面括号内的实参字符串代替#define 命令中的形参
2 在宏定义时,宏名与带参数的括号之间不可以加空格。否则会将空格后面的字符都作为替代字符串的一部分
3 在带参宏定义中,形式参数不分配内存单元,因此不必做类型定义
58:#include指令
在一个源文件中使用#include指令可以将另一个源文件的全部内容包含进来,也就是将另外的文件包含到本文件中来。#include使编译程序将一个源文件嵌入带有#include的源文件,被读入的源文件必须用双引号或尖括号括起来
#include"stdio.h"
#include<stdio.h>
用尖括号时,系统到存放C库函数头文件所在的目录中寻找所要包含的文件。双引号,到用户当前目录寻找所包含的文件,找不到再到C库函数头文件所在目录去寻找
一般情况下 将宏定义、结构、联合和枚举声明 、typedef声明 外部函数声明 全局变量声明 放在头文件内
59: 条件编译
一般情况下,源程序中所有的行都参加编译,如果只希望其中一部分参加编译,就需要使用一些条件编译命令。
#if 的基本含义是:如果#if后的参数表达式为真 ,则编译#if到#endif之间的程序段,否则跳过这段程序。#endif命令用来表示#if段的结束
#if命令的一般形式
#if 常数表达式
语句段
#endif
中间还可以加入 #else用来当#if为假时提供另一种选择。
#elif指令用来建立一种如果。。。或者如果这样的阶梯状多重编译操作选择。
#ifdef及#idndef 命令
在#if条件编译命令中,需要判断符号常量所定义的具体值,但有时并不需要判断具体值。只需要知道这个符号是否被定义了,这时就不需要使用#if,可以采用另一种条件编译的方法,即#ifdef和#ifndef 。
#ifdef 宏替换名
语句段
#endif
其含义是:如果宏替换名已被定义过,则对语句段进行编译;如果未定义#ifdef后面的宏替换名,则不对语句进行编译
#ifdef 可以与#else连用
#ifdef 宏替换名
语句段 1
#else
语句段 2
#endif
其含义是:如果宏替换名被定义过,编译语句段1,否则编译语句段2
#idndef的一般形式如下:
#ifndef 宏替换名
语句段
#endif
其含义是:如果未定义后面的宏替换名,则编译语句段
同理#ifndef也可以与#else连用
#ifndef 宏替换名
语句段 1
#else
语句段 2
#endif
#undef命令
使用#undef命令可以删除事先定义好的宏定义
#undef 宏替换名
#define MAX_SIZE 100
#undef MAX_SIZE
#undef的主要目的是将宏名局限在仅需要他们的代码中
#line命令
#line命令用于显示__LINE__ 与__FILE__的内容
__LINE__存放当前编译行的行号,__FILE__存放当前编译的文件名
#line 行号["文件名"]
行号为任一正整数,可选的文件名为任意有效的文件标识符。
#line 100 "13.7.C"
#include<stdio.h>
main()
{
printf("1.当前行号:%d\n",__LINE__);
printf("2.当前行号:%d\n",__LINE__);
}
#pragma命令
设定编译器状态 ,或者指示编译器完成一些特定的动作
#pragma 参数
1 message参数:在编译信息窗口中输出相应的信息
2 code_seg参数:设置程序中函数代码存放的代码段
3 once参数:保证头文件被编译一次
预定义宏名
ANSI标准说明了以下5个预定义宏替换名
1:__LINE__:当前被编译代码的行号
2: __FILE__ :当前源程序的文件名称
3:__DATA__:当前源程序的创建日期
4:__TIME__:当前源程序的创建时间
5:__STDC__:用来判断当前编译器是否为标准C,若是,其值为1,否则不是标准c
60:文件
文件是指一组相关的数据的有序集合,这个数据有一个名称,叫做文件名。
通常情况下,使用计算机也就是在使用文件。在前面的程序设计中介绍了输入和输出,即从标准的输入设备(键盘)输入,有标准输出设备(显示器或打印机)输出。不仅如此,我们也常把磁盘作为信息载体,用于保存中间结果或最终数据。在使用一些字处理工具时,会打开一个文件将磁盘的信息输入内存,通过关闭一个文件来实现将内存数据输出到磁盘。这时的输入和输出是针对文件系统的,因此文件系统也可以是输入和输出的对象
所有文件都可以通过流进行输入、输出操作。与文本流和二进制流相对应。
1:文本文件也成为ASCII文件,这种文件在保存时,每个字符对应一个字节,用于存放对应的ASCII码。
2:二进制文件,不是保存ASCII码,而是按二进制的编码方式来保存文件内容
3:从用户的角度,文件可以分为普通文件和设备文件
普通文件是指驻留在磁盘或其他外部介质上的一个有序数据集
设备文件是指与主机相连的各种外部设备,如显示器、打印机、键盘等。在操作系统中把外部设备也看作是一个文件来进行管理,把他们二点输入、输出等同于磁盘文件的读和写。
4:按文件内容看,分为源文件,目标文件,可执行文件,头文件,数据文件等
C语言中文件操作都是由库函数完成
文件的基本操作
文件的基本操作包括打开和关闭。除了标准的输入、输出文件外,其他的文件都必须打开再使用,使用后还必须关闭该文件。
文件指针:一个指向文件有关信息的指针,这些信息包含文件名,状态和当前位置。它们保存在一个结构变量中。在使用文件时需要在内存中为其分配空间,用来存放文件的基本信息,该结构体类型是由系统定义的,C语言规定该类型为FILE类
typedef struct
{
short level;
unsigned flags;
char fd;
unsigned char hold;
short bsize;
unsigned char *buffer;
unsigned ar *curp;
unsigned istemp;
short token;
}FILE;
从上面的结构可以发现,使用typedef定义了一个FILE为该结构体的类型。在编写程序的时候,
可直接使用上面的定义的FILE类型来定义变量,注意,在定义变量时不必将结构体内容全部给出,只需要写成如下形式
FILE *fp;
fp是一个指向FILE类型的指针变量
61:文件的打开
fopen函数用来打开一个文件,打开文件的操作就是创建一个流。fopen函数的原型在stdio.h中,
FILE *fp;
fp = fopen(文件名,使用文件的方式);
如果要以只读方式打开文件名为123的文本文档文件
FILE *fp;
fp=("123.txt","r");
如果使用fopen函数打开文件成功,则返回一个有确定指向的FILE类型指针;若打开失败,则返回NULL。
通常打开失败的原因
1:指定的盘符或路径不存在。
2:文件名中含有无效字符。
3:以r模式打开一个不存在的文件。
62:文件的关闭
文件使用完毕后,要使用fclose函数将其关闭。fclose函数和fopen函数一样,原型也在stdio.h中,调用的一般形式如下
fclose(文件指针);
fclose(fp);
fclose函数也是返回一个值,当正常关闭文件操作时,fclose函数返回值为0,否则返回EOF。
63:文件的读写
1 fputc函数
ch=fputc(ch,fp);
该函数的作用是吧一个字符写进磁盘文件(fp所指向的是文件)。其中,ch是输出的字符,它可以是一个字符常量,也可以是一个字符变量。fp是文件指针变量,如果函数输出成功,则返回值就是输出的字符;如果输出失败,则返回EOF。
#include<stdio.h>
main()
{
FILE *fp;
char ch;
if(()fp=fopen("E:\\exp01.txt","w"))==NULL) //返回的是NULL就是创建失败
{
printf("cannot open file\n");
exit(0);
}
ch=getchar();
while(ch!='#')
{
fputc(ch,fp);
ch=getchar();
}
fclose(fp);
}
2 fgetc函数
ch=fgetc(fp)
该函数的作用是从指定的文件(fp指向的文件)读入一个字符赋予ch。需要注意的是,该文件必须以已读或读写的方式打开。当函数遇到文件结束符时,将返回一个文件结束标志EOF
#include<stdio.h>
main()
{
FILE *fp;
char ch;
fp=fopen("E:\\exp02.txt","r");
ch=getc(fp);
while(ch!=EOF)
{
putchar(ch);
ch=getc(fp);
}
fclose(fp);
}
3 fputs函数与fputc函数类似,区别在于fputc每次只向文件中写入一个字符,而fputs函数每次向文件写入一个字符串
fputs(字符串,文件指针)
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
char filename[30],str[30];
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,"w"))==NULL) //返回的是NULL就是创建失败
{
printf("can not open!\n press any key to continue:\n");
getchar();
exit(0);
}
printf("please input string:\n");
getchar();
gets(str);
fputs(str,fp);
fclose(fp);
}
fgets函数和fgetc类似,同上
fgets(字符数组名,n,文件指针);n表示所得到的字符串中字符的个数!
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
char filename[30],str[30];
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,"r"))==NULL) //返回的是NULL就是创建失败
{
printf("can not open!\n press any key to continue:\n");
getchar();
exit(0);
}
printf("please input string:\n");
fgets(str,sizeof(str),fp);
printf("%s",str);
fclose(fp);
}
fprintf函数
fprintf读写的对象不是终端而是磁盘文件
ch=fprintf(文件类型指针,格式字符串,输出列表);
例如
fprintf(fp,"%d",i);将整型变量i的值以”%d“的格式输出到fp指向的文件中
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
int i=88;
char filename[30];
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,"w"))==NULL) //返回的是NULL就是创建失败
{
printf("can not open!\n press any key to continue:\n");
getchar();
exit(0);
}
fprintf(fp,"%c",i);
fclose(fp);
}
fscanf函数
fscanf(文件类型指针,格式字符串,输入列表)
fscanf(fp,"%d",&i);它的作用是读入fp所指向文件中i的值
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
char i,j;
char filename[30];
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,"r"))==NULL) //返回的是NULL就是创建失败,注意是让打开文件的指针跟NULL
{
printf("can not open!\n press any key to continue:\n");
getchar();
exit(0);
}
for(i=0;i<5;i++)
{
fscanf(fp,"%c",j);
printf("%d is :%5d\n",i+1,j)
}
fclose(fp);
}
fread和fwrite函数
整块读写函数
fread(buffer,size,count,fp);
从fp指针读入count次,每次读size个字节,读入的信息存在buffer地址内
fwrite(buffer,size,count,fp)
将buffer地址开始的信息输出count次,每次写size字节到fp所指的文件中去。
fread(a,2,3,fp);
fwrite(a,2,3,fp);
例子,将录入通信录信息保存到磁盘文件中去,在录入完信息后,将所录入的信息全部显示出来
#include<stdio.h>
#include<process.h>
struct address_list
{
char name[10];
char addr[20];
char tel[15];
}info[100];
void save(char *name,int n)
{
FILE *fp;
int i;
if((fp=fopen(name,"w"))==NULL)
{
printf("cannot open file\n");
exit(0);
}
for(i=0;i<n;i++)
{
if(fwrite(&info[i],sizeof(struct address_list),1,fp)!=1)
printf("file write error\n");
}
fclose(fp);
}
void show(char *name,int n)
{
int i;
FILE *fp;
if((fp=fopen(name,"r"))==NULL)
{
printf("cannot open file\n");
exit(0);
}
for(i=0;i<n;i++)
{
fread(&info[i],sizeof(struct address_list),1,fp);
printf("%15s%20s%20s\n",info[i].name,info[i].adr,info[i].tel);
}
fclose(fp);
}
int main()
{
int i,n;
char filename[50];
printf("how many?\n");
scanf("%d",&n);
printf("please input filename:\n");
scanf("%s",filename);
printf("please input name,address,telephone:\n");
for(i=0;i<n;i++)
{
printf("NO%d ",i+1);
scanf("%s%s%s",info[i].name,info[i].adr,info[i].tel);
save(filename,n);
show(filename,n);
}
return 0;
}
64:文件的定位
fseek函数
借助缓冲型I/O系统中的fseek函数,可以完成随机读写的操作
fseek(文件类型指针,位移量,起始点);
该函数的作用是移动文件内部的位置指针。其中,”文件类型指针“指向被移动的文件。”位移量“表示移动的字节数,要求位移量是long型数据,以便文件在大于64KB时不会出错。当用常量表示位移量时,要求加后缀”L“
fseek(fp,-20L,1)
表示指针从当前位置向后退20个字节。
feek一般用于二进制文件。在文本文件中由于需要计算,往往计算的位置会出现错误。
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
char filename[30],str[50];
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,'wb'))==NULL)
{
printf("cannot open file\n");
getchar();
exit(0);
}
printf("please input string:\n");
getchar();
gets(str);
fputs(str,fp);
fclose(fp);
if((fp=fopen(filename,'rb'))==NULL)
{
printf("cannot open file:\n");
getchar();
exit(0);
}
fseek(fp,5L,0);
fgets(str,sizeof(str),fp);
putchar('\n');
puts(str);
fclose(fp);
}
rewind函数
rewind函数也能定位文件指针。
int rewind(文件类型指针)
该函数的作用是使指针位置返回文件的开头,该函数没有返回值。
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
char filename[30],ch;
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,'wb'))==NULL)
{
printf("cannot open file\n");
getchar();
exit(0);
}
ch=fgetc(fp);
while(ch!=EOF)
{
putchar(ch);
ch=fgetc(fp);
}
rewind(fp);
ch=fgetc(fp);
while(ch!=EOF)
{
putchar(ch);
ch=fgetc(fp);
}
fclose(fp);
}
ftell函数
long ftell(文件类型指针)
该函数作用是得到流式文件中的当前位置,用相对于文件开头的位置来表示。当ftell函数的返回值为-1L时,表示出错。
#include<stdio.h>
#include<process.h>
main()
{
FILE *fp;
int n;
char filename[30],ch;
printf("please input filename:\n");
scanf("%s",filename);
if((fp=fopen(filename,'wb'))==NULL)
{
printf("cannot open file\n");
getchar();
exit(0);
}
ch=fgetc(fp);
while(ch!=EOF)
{
putchar(ch);
ch=fgetc(fp); //指针移到结尾获取位移量,得到长度
}
n=ftell(fp);
printf("\nthe length of the string is :%d\n",n);
fclose(fp);
}
feof(文件指针)
是C语言标准库函数,其原型在stdio.h中,其功能是检测流上的文件结束符,如果文件结束,则返回非0值,否则返回0(即,文件结束:返回非0值;文件未结束:返回0值)
65: 内存
内存被组织成4个逻辑段
1:可执行代码
2:静态数据。可执行代码和静态数据存储在固定的内存位置
3:动态数据(堆)。程序请求动态分配的内存来自内存池,也就是上面所列举的堆。
4:栈。局部数据对象、函数参数,以及调用函数和被调用函数的联系放在称为栈的内存池中。
堆用来存放动态分配的内存空间,栈用来存放局部数据对象、函数参数,以及调用函数和被调用函数的联系。
堆:在C程序中,用malloc和free函数从堆中动态地分配和释放内存。
#include<stdio.h>
int main()
{
int *pInt;
pInt=(int *)malloc(sizeof(int));
*pInt=100;
printf("number is %d\n",*pInt);
free(pInt);
return 0;
}
栈:程序不会像处理堆那样,在栈中显示地分配内存,当程序调用函数和声明局部变量时,系统内会自动分配内存。
栈是一个后进先出地数据结构。在程序运行时,需要向栈中压入一个对象,然后栈指针移入下一个位置。当系统从栈中弹出一个对象时,最晚进栈地对象将被弹出,然后栈指针向上移动一个位置。如果栈指针位于栈顶,则表示栈是空的。如果栈指针指向最下面地数据项地后一位置,则表示栈是满的。
动态管理
malloc函数
void *malloc(unsigned int size);
stdlib.h包含该函数。分配一片大小为size地空间,返回一个指针指向该空间,出错返回NULL
calloc函数
void *calloc(unsigned n,unsigned size)
分配n个尺寸为size的连续内存空间数组。
realloc函数
void *realloc(void *ptr,size_t size);
改变ptr指针指向空间的大小为size大小。
free函数
void free(void *ptr)
释放由指针ptr指向的内存区,ptr是最近一次调用calloc或malloc时返回的值。
在使用malloc等函数分配内存后,还需使用free函数释放内存。内存不进行释放会造成内存遗漏。















 6157
6157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









