







MySQL高级第十一篇:数据库调优策略(定位-调优-结构)
一、数据库调优的目标
- 1.尽可能节省系统资源,以便系统可以提供更大负荷的服务。
(吞吐量更大) - 2.合理的结构设计和参数调整,以提高用户操作响应的速度。
(响应速度更快) - 3.减少系统的瓶颈,提高MySQL数据库整体的性能。
二、调优时如何定位问题?
1. 用户的反馈★
- 用户是我们的服务对象,因此他们的反馈是最直接的。虽然他们不会直接提出技术建议,但是有些问题往往是用户第一时间发现的。我们要重视用户的反馈,找到和数据相关的问题。
2. 日志分析★
- 通过查看数据库日志和操作系统日志等方式找出异常情况,通过它们来定位遇到的问题。
3. 服务器资源使用监控
- 通过监控服务器的CPU、内存、I/O等使用情况,可以实时了解服务器的性能使用,与历史情况进行对比。
4. 数据库内部状况监控
- 在数据库的监控中,
活动会话(Active Session)监控是一个重要的指标。通过它,可以清楚地了解数据库当前是否处于非常繁忙的状态,是否存在SQL堆积等。
5. 其它
- 除了活动会话监控以外,也可以对事务、锁等待等进行监控,这些都可以帮助我们对数据库的运行状态有更全面的认识。
三、数据库调优步骤
第1步:选择适合的DBMS
DBMS的选择关系到了后面的整个设计过程,所以首先要选择适合的DBMS,如果是确定好的系统直接第二步
- 如果对事务性处理以及安全性要求高的话,可以选择商业的数据库产品。这些数据库在事务处理和查询性能上都比较强,比如采用SQL Server、Oracle,单表存储上亿条数据是没有问题的。如果数据表设计得好,即使不采用分库分表的方式,查询效率也不差。
- 除此以外,也可以采用开源的MySQL进行存储,它有很多存储引擎可以选择,如果进行事务处理的话可以选择InnoDB,非事务处理可以选择MylSAM。
- NoSQL阵营包括键值型数据库、文档型数据库、搜索引擎、列式存储和图形数据库。这些数据库的优缺点和使用场景各有不同,比如列式存储数据库可以大幅度降低系统的I/O,适合于分布式文件系统,但如果数据需要频繁地增删改,那么列式存储就不太适用了。
第2步:优化表设计
RDBMS中,每个对象都可以定义为一张表,表与表之间的关系代表了对象之间的关系。如果用的是MySQL,还可以根据不同表的使用需求,选择不同的存储引擎。
- 1.表结构要
尽量遵循三范式的原则。这样可以让数据结构更加清晰规范,减少冗余字段,同时也减少了在更新,插入和删除数据时等异常情况的发生。 - 2.如果查询应用比较多,尤其是需要进行多表联查的时候,可以采用
反范式进行优化。反范式采用空间换时间的方式,通过增加冗余字段提高查询的效率。 - 3.表字段的
数据类型选择,关系到了查询效率的高低以及存储空间的大小。一般来说,如果字段可以采用数值类型就不要采用字符类型;字符长度要尽可能设计得短一些。针对字符类型来说,当确定字符长度固定时,就可以采用CHAR类型;当长度不固定时,通常采用VARCHAR类型。
第3步:优化逻辑查询
- SQL查询优化,可以分为
逻辑查询优化和物理查询优化。逻辑查询优化就是通过改变SQL语句的内容让SQL执行效率更高效,采用的方式是对SQL语句进行等价变换,对查询进行重写。 - SQL的查询重写包括了子查询优化、等价谓词重写、视图重写、条件简化、连接消除和嵌套连接消除等。
第4步:优化物理查询
索引的创建和使用
索引相关问题前边几章节已经详细剖析过,这里不在赘述。
第5步:考虑使用缓存
除了可以对SQL本身进行优化以外,还可以请外援提升查询的效率。
- 因为数据都存放到数据库中,我们需要从数据库层中取出数据放到内存中进行业务逻辑的操作,当用户量增大的时候,如果频繁地进行数据查询,会消耗数据库很多资源。如果
将常用的数据直接放到内存中,就会大幅提升查询的效率。 - 常用的键值存储数据库有 Redis和Memcached,它们都可以将数据存放到内存中。
- 从可靠性来说,
Redis支持持久化,可以让我们的数据保存在硬盘上,不过这样一来性能消耗也会比较大。而Memcached仅仅是内存存储,不支持持久化。 - 从支持的数据类型来说,Redis 比 Memcached要多,它不仅支持key-value类型的数据,还支持List,Set,Hash等数据结构。
第6步:库级优化
读写分离- 如果读和写的业务量都很大,并且它们都在同一个数据库服务器中进行操作,那么数据库的性能就会出现瓶颈,这时为了提升系统的性能,优化用户体验,我们可以采用读写分离的方式降低主数据库的负载,比如用主数据库完成写操作,用从数据库完成读操作。
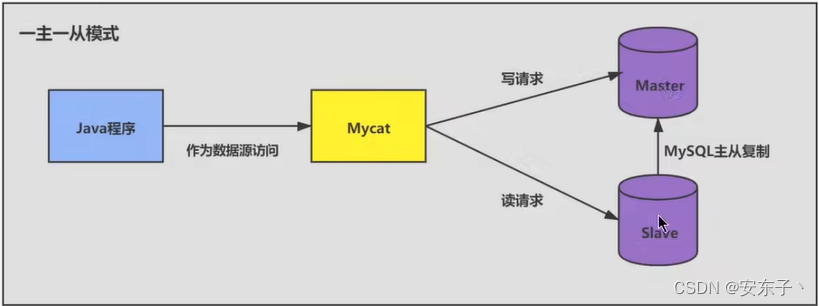
分库分表- 当数据量级达到千万级以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力。如果使用的是MySQL,就可以使用MySQL自带的分区表功能,也可以自己做垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)。
四、数据库结构优化
1. 拆分表(冷热分离)
- 把1个包含很多字段的表拆分成2个或者多个相对较小的表。
- 因为这些表中某些字段的操作频率很高(热数据),经常要进行查询或者更新操作,而另外一些字段的使用频率却很低(冷数据),冷热数据分离,可以
减小表的宽度。 - 如果放在一个表里面,每次查询都要读取大记录,会消耗较多的资源。
- MySQL限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节。
- 表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的I/O。
- 冷热数据分离的目的是:
①减少磁盘I/O,保证热数据的内存缓存命中率。②更有效的利用缓存,避免读入无用的冷数据。
2. 增加中间表、冗余字段
-
对于需要经常联合查询的表,可以建立中间表以提高查询效率。
-
通过建立中间表,把需要经常联合查询的数据插入中间表中,然后将原来的联合查询改为对中间表的查询,以此来提高查询效率。
-
另外,表的规范化程度越高,表与表之间的关系就越多,需要连接查询的情况也就越多。尤其在数据量大,而且需要频繁进行连接的时候,为了提升效率,我们也可以考虑增加冗余字段来减少连接。
3. 优化字段数据类型
- 优先选择符合存储需要的最小的数据类型。
- 列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少,在遍历时所需要的IO次数也就越多,索引的性能也就越差。
五、单表记录过大优化
- 1、限定查询范围,使用上查询条件,索引。
- 2、读写分离
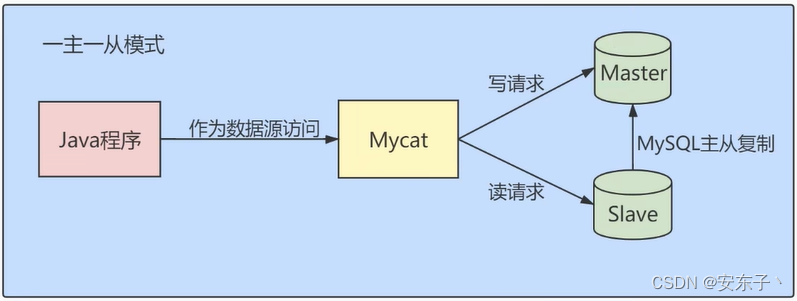
- 3、垂直拆分,水平拆分

















 8036
8036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











