






跑一篇论文的代码,预处理数据就感觉不对劲,跑了一天半才35%:
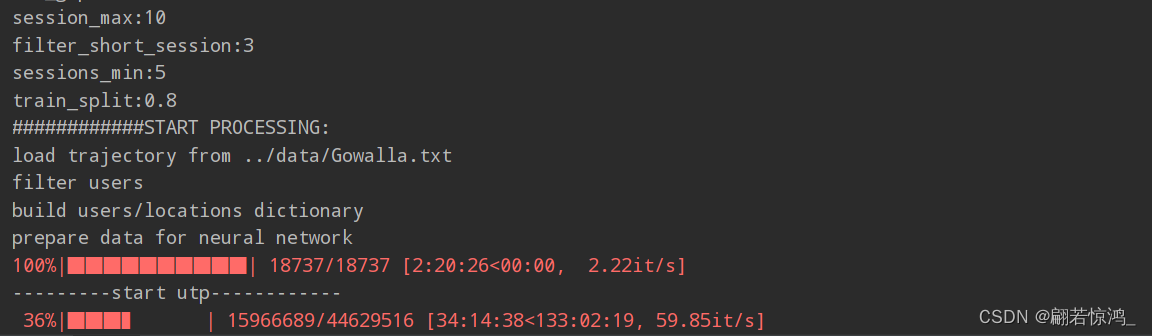
仅仅是一个数据预处理,怎么能这么慢?
仔细看过代码以后,大概明白是怎么回事了:
def construct_data(self, n_tim_rel, tim_dis_dict):
train_kg_ptp, train_kg_upt, train_kg = [], [], []
train_kg_dict, train_kg = collections.defaultdict(list), collections.defaultdict(list)
n_locs = len(self.vid_list)
# get utp-triple
head_upt = [(triple[0] + n_locs) for triple in self.train_utp]
rel_upt = [triple[1] for triple in self.train_utp]
tail_upt = [triple[2] for triple in self.train_utp]
# get ptp-triple
head_ptp = [triple[0] for triple in self.train_ptp]
rel_ptp = [int(tim_dis_dict[tuple(triple[1])] + n_tim_rel) for triple in self.train_ptp]
tail_ptp = [triple[2] for triple in self.train_ptp]
print("---------start utp------------")
for i in tqdm(range(len(head_upt))):
if [head_upt[i], rel_upt[i], tail_upt[i]] not in train_kg['utp']:
train_kg_dict[head_upt[i]].append((tail_upt[i], rel_upt[i]))
train_kg['utp'].append([head_upt[i], rel_upt[i], tail_upt[i]])
print("---------start ptp------------")
for j in tqdm(range(len(head_ptp))):
if [head_ptp[j], rel_ptp[j], tail_ptp[j]] not in train_kg['ptp']:
train_kg_dict[head_ptp[j]].append((tail_ptp[j], rel_ptp[j]))
train_kg['ptp'].append([head_ptp[j], rel_ptp[j], tail_ptp[j]])
print('load KG data.')
return train_kg_dict, train_kg
问题出在这几句代码上:
print("---------start utp------------")
for i in tqdm(range(len(head_upt))):
if [head_upt[i], rel_upt[i], tail_upt[i]] not in train_kg['utp']:
train_kg_dict[head_upt[i]].append((tail_upt[i], rel_upt[i]))
train_kg['utp'].append([head_upt[i], rel_upt[i], tail_upt[i]])
print("---------start ptp------------")
for j in tqdm(range(len(head_ptp))):
if [head_ptp[j], rel_ptp[j], tail_ptp[j]] not in train_kg['ptp']:
train_kg_dict[head_ptp[j]].append((tail_ptp[j], rel_ptp[j]))
train_kg['ptp'].append([head_ptp[j], rel_ptp[j], tail_ptp[j]])
可以看到作者其实只是想做一个没有重复三元组的list,但是他使用的方法是每次插入之前都在整个list中做查询,算法的复杂度直接变成了O(n^2)
这种算法太笨了,想了想,参考这篇博客,我改成了下面这样:
print("---------start utp------------")
upt_mat = np.array((head_upt, rel_upt, tail_upt)) # 3 * n
upt_mat = upt_mat.T # n * 3
temp = list(set([tuple(t) for t in upt_mat])) # 去重
temp = [list(v) for v in temp] # tuple->list
train_kg['utp'] = temp
for i in range(len(temp)):
train_kg_dict[temp[i][0]].append((temp[i][2], temp[i][1]))
print("---------start ptp------------")
ptp_mat = np.array((head_ptp, rel_ptp, tail_ptp)) # 3 * n
ptp_mat = ptp_mat.T # n * 3
temp = list(set([tuple(t) for t in ptp_mat])) # 去重
temp = [list(v) for v in temp] # tuple->list
train_kg['ptp'] = temp
for i in range(len(temp)):
train_kg_dict[temp[i][0]].append((temp[i][2], temp[i][1]))
再次运行,这里几乎就没有停滞,几秒钟就做完了。
和原先需要的时间(几秒vs三四天)比起来,简直是天差地别…
经验教训:对于要处理大数据量的程序,谨慎编写代码,尽量为算法的性能考虑,多用Python所给的方法解决问题。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









