







1、[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.5:compile (default-compile) on project easyml-manage: Compilation failure: Compilation failure:
[ERROR] /D:/gyl/gitee/EasyMl/easyml-manage/src/main/java/com/trusfort/easyml/controller/interceptor/StartupListener.java:[3,40] 找不到符号
[ERROR] 符号: 类 JobService
[ERROR] 位置: 程序包 com.trusfort.easyml.service.task
[ERROR] /D:/gyl/gitee/EasyMl/easyml-manage/src/main/java/com/trusfort/easyml/controller/interceptor/StartupListener.java:[22,5] 找不到符号
[ERROR] 符号: 类 JobService
[ERROR] 位置: 类 com.trusfort.easyml.controller.interceptor.StartupListener
[ERROR] -> [Help 1]
解决方案:找到项目中JobService类的位置,右键该类,点击Recompile即可。

2、

这是因为scala程序的主类是这样声明的:
Class Demo {
def main(args : Array[String]) {
}
}
要把它改成这样:

3、下面的bug是因为没有写这句话:
Import org.apache.spark.sql.types._

4、spark中textFile读取txt文件时,txt文件内容行数与读取出来进行count后的行数与内容行数不一致。
(1)txt文件最后没有空行,总共有150行
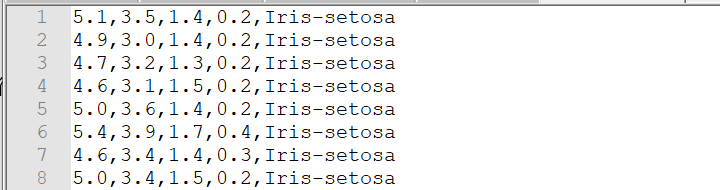


(2)txt文件最后有空行,spark中textFile读取了151行
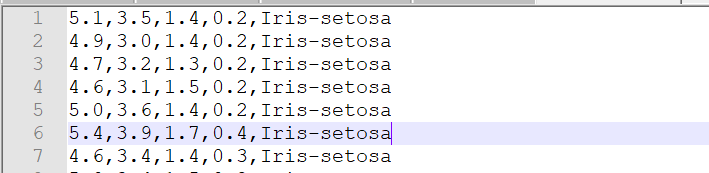


再看看数据,最后一个空行被toDF操作转换为[]

5、spark的dataframe中withColumn里函数不要写成这样col(“features”).apply(convertUDF),会出问题(这里的apply的用法不同)
要写成下面这样就没问题:

6、Idea中JDK为1.8,还提示Diamond types are not supported at this language level。

解决方法:通过查看项目设置,发现project的java level 也是8。

然后继续检查其他模块 如modules ,发现了问题所在

将其改为8就可以了。
7、一个非常简单的程序,出现了一个这样的错误:


解决办法:
(1)
- 网上说是hdfs目录下有相关的hadoop jar包,删掉就能用,试了一下,并没有用。
- 网上说是jar包冲突,删除本地guava库(这种解决方法是存在多个版本guava库的时候,而我这里只有一个版本,并且我也没有进行hbase查询,所以并没有用)。
- 真正的答案,导致错误的原因的确是guava包的问题。查看pom.xml文件,发现自己并没有写guava的依赖,所以应该是别的地方引用到了。然后去idea的依赖包管理界面external Libraries查看存在版本为19.0的guava包,导致这个错误的原因就是版本19.0的guava包和spark不兼容,于是在pom.xml文件中添加以下依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>
等依赖加载完后,能看到external Libraries里guava包的版本变为15.0,再次运行,发现不会报错了。

8、错误:
Unable to instantiate SparkSession with Hive support because Hive classes are not found.解决方法:在pom.xml文件中添加依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
9、在对dataframe的每列计算统计特征时,报如下错误:

错误原因:scala中“$”后面接一个变量名以提取变量值,而这里columnName(0)的值是字符串。

解决方案:将”$”去掉也没用,因为将“$”去掉后,在双引号里面的columnName(0)就表示一个字符串,而不是”x”。最后的解决方法是分别定义,然后用”$”引用。
10、关于spark.sql中字符串前面s的问题,如果不加s,则会报错:无法解析变量

解决方法:在字符串前面加个s(具体可以看看scala中字符串插值)

11、mysql中第一次修改密码出现的问题:

出现该错误的原因是root@localhost加了单引号,将该单引号去掉就ok,即:ALTER USER root@localhost IDENTIFIED BY '1234'; 。(注意:最后的分号一定要有)
12、sql问题:出现这个问题的主要原因是$str中的值与data1和data2的列不一样,在str中数据表是aa和bb,而实际给的是data1和data2.这说明sql中别名和原始名是不等价的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









