






1、前言
随着docker和kubernetes的普及,越来越多的服务选择了容器化部署,这当然包含了一部分go语言程序,而go程序的GOMAXPROCS在容器环境需要特别关注。
2、GOMAXPROCS
2.1 GMP模型
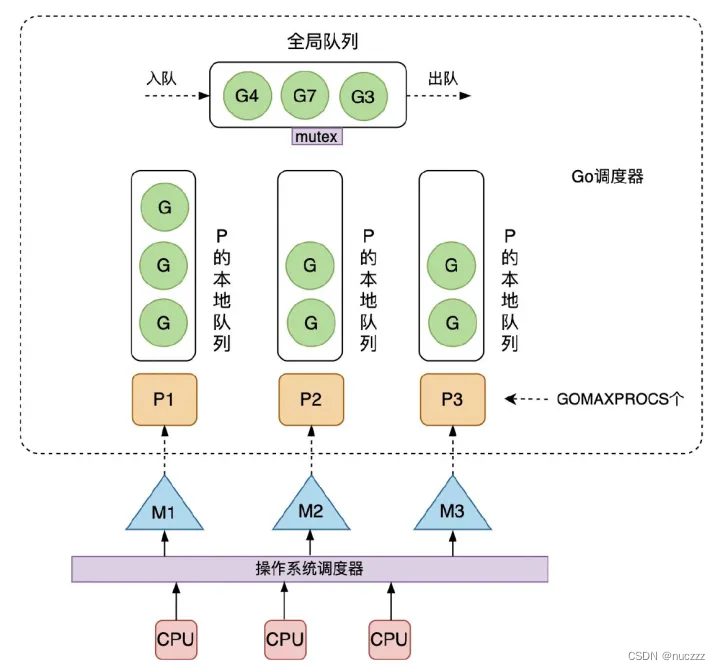
go使用GMP调度模型,其中G对应goroutine,M对应操作系统线程(OS Thread),P是Processor的缩写,代表一个虚拟的处理器。每个P维护一个本地G队列,go调度器也维护了一个全局的G队列,可以通过CAS的方式无锁访问,工作线程M优先使用自己的局部运行队列中的G,只有必要时才会去访问全局G队列,每个G要想真正运行起来,首先需要被分配一个P。P的数量可以通过GOMAXPROCS函数设置。
2.2 如何设置和获取P的数量?
可以借助runtime包下的GOMAXPROCS函数设置和读取P的数量,以go@v1.17.1为例,GOMAXPROCS函数源码如下:
// go/src/runtime/debug.go
func GOMAXPROCS(n int) int {
if GOARCH == "wasm" && n > 1 {
n = 1 // WebAssembly has no threads yet, so only one CPU is possible.
}
lock(&sched.lock)
ret := int(gomaxprocs)
unlock(&sched.lock)
if n <= 0 || n == ret {
return ret
}
stopTheWorldGC("GOMAXPROCS")
// newprocs will be processed by startTheWorld
newprocs = int32(n)
startTheWorldGC()
return ret
}
通过上面代码可以看出,一般情况下,GOMAXPROCS函数入参小于1时,不会修改P的数量,因此可用入参0来获取P的数量;如果想设置P的数量,则传入一个大于或等于1的数即可。
package main
import (
"fmt"
"runtime"
)
func main() {
// 获取当前P的数量
fmt.Println(runtime.GOMAXPROCS(0))
// 设置P的数量
runtime.GOMAXPROCS(4)
// ...
}
2.3 默认P的数量
从v1.5版本起,go程序启动的时候会默认把P的数量设置为CPU数量,例如一个go程序跑在2C4G的虚拟机或者物理机上,则P的数量默认为2。
我们以v1.17.1为例,从go源码上稍微追踪下这段逻辑。在go/src/runtime/proc.go的schedinit调度器初始化函数前有如下注释:
// go/src/runtime/proc.go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
说明了在main函数前bootstrap会做osinit、schedinit等流程,P的数量也是在这些流程中初始化的。
2.3.1 osinit
假设操作系统是linux,osinit相关流程如下:
// go/src/runtime/runtime2.go
var (
gomaxprocs int32
ncpu int32
/*...*/
newprocs int32
)
// go/src/runtime/os_linux.go
func osinit() {
ncpu = getproccount()
/*...*/
}
// go/src/runtime/os_linux.go
func getproccount() int32 {
// This buffer is huge (8 kB) but we are on the system stack
// and there should be plenty of space (64 kB).
// Also this is a leaf, so we're not holding up the memory for long.
// See golang.org/issue/11823.
// The suggested behavior here is to keep trying with ever-larger
// buffers, but we don't have a dynamic memory allocator at the
// moment, so that's a bit tricky and seems like overkill.
const maxCPUs = 64 * 1024
var buf [maxCPUs / 8]byte
// 核心逻辑是sched_getaffinity函数
r := sched_getaffinity(0, unsafe.Sizeof(buf), &buf[0])
if r < 0 {
return 1
}
n := int32(0)
for _, v := range buf[:r] {
for v != 0 {
n += int32(v & 1)
v >>= 1
}
}
if n == 0 {
n = 1
}
return n
}
//go:noescape
// noescape的作用就是禁止逃逸,指定文件中的下一个声明必须是不带主题的func(意味着该声明的实现不是用Go编写的),不允许将作为参数传递的任何指针逃逸到堆或函数的返回值上
func sched_getaffinity(pid, len uintptr, buf *byte) int32
sched_getaffinity是【获取操作系统cpu亲和性】的方法 ,该方法的详细信息可在linux上执行man sched_getaffinity查看,一般情况下CPU不会对进程做特殊限制,因此这里也就可以获取操作系统层面的CPU数量。
2.3.2 schedinit
再来看看schedinit相关逻辑:
// go/src/runtime/proc.go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
/*...*/
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
/*...*/
}
// go/src/runtime/proc.go
func procresize(nprocs int32) *p {
/*...*/
old := gomaxprocs
/*...*/
// 初始化P的数量
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
/*...*/
// 销毁多余的P
// release resources from unused P's
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
/*...*/
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
return runnablePs
}
前面提到osinit是在schedinit前执行,而osinit已经把全局变量ncpu设置为了操作系统cpu数,因此上面schedinit代码中通过procresize函数把ncpu的值作为P的数量,并设置到全局变量gomaxprocs中,从而完成了GOMAXPROCS的初始化。
2.4 再看GOMAXPROCS函数
2.4.1 获取P的数量
在上面GOMAXPROCS函数源码中可以看出,当入参传入0时,返回的实际上是一个全局变量gomaxprocs,这个变量就是schedinit设置的ncpu,也就是osinit过程获取到的操作系统层面的cpu数量值。
2.4.2 设置P的数量
假设有机器的cpu是8,程序中有设置P数量为4的代码:
runtime.GOMAXPROCS(4)
经过osinit和schedinit后,全局变量ncpu和gomaxprocs的值都是8,于是GOMAXPROCS函数会走如下逻辑:
// go/src/runtime/debug.go
// n = 4
func GOMAXPROCS(n int) int {
/*...*/
// n = 4
newprocs = int32(n)
startTheWorldGC()
return ret
}
// go/src/runtime/proc.go
func startTheWorldGC() {
startTheWorld()
/*...*/
}
// go/src/runtime/proc.go
func startTheWorld() {
systemstack(func() { startTheWorldWithSema(false) })
/*...*/
}
// go/src/runtime/proc.go
func startTheWorldWithSema(emitTraceEvent bool) int64 {
/*...*/
procs := gomaxprocs
if newprocs != 0 {
procs = newprocs
newprocs = 0
}
p1 := procresize(procs)
/*...*/
}
procresize函数在schedinit中也有调用,传入的procs = 4,小于之前的8,所以在procresize函数内部会走这段逻辑,从而达到了设置P数量的目的:
// go/src/runtime/proc.go
func procresize(nprocs int32) *p {
/*...*/
// 销毁多余的P
// release resources from unused P's
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
/*...*/
docker容器环境
在2.3.1 osinit章节中,我们强调了 sched_getaffinity是【获取操作系统cpu亲和性】的方法 ,但是对于docker容器,它是共享宿主机操作系统内核的,因此docker容器下的go程序会初始化P的数量为宿主机cpu数量。
但是在kubernetes集群中,通常宿主机的cpu都会比较大,有的甚至有100+c,而go程序业务通常需要很小规格即可,例如2c4g。假设一个go程序pod容器的request配置了2c4g,而部署到了一个120c的宿主机上,go程序默认会起120个P,但是cgroup限制了go程序只有2c4g的资源,这很可能会因P数量过多导致不必要的资源争抢,反而降低性能。
3、docker容器环境中如何正确设置P的数量
通过前面的分析,docker环境go程序P数量设置过大的原因是go初始化时获取的宿主机cpu与cgroup中数值不一致,我们可以用uber的automaxprocs包把GOMAXPROCS设置为cgroup中cpu数:
package main
import _ "go.uber.org/automaxprocs"
func main() {
/*...*/
}
来看看uber这个包是怎么实现的:
// go.uber.org/automaxprocs/automaxprocs.go
import (
"log"
"go.uber.org/automaxprocs/maxprocs"
)
func init() {
maxprocs.Set(maxprocs.Logger(log.Printf))
}
// go.uber.org/automaxprocs/maxprocs/maxprocs.go
func Set(opts ...Option) (func(), error) {
cfg := &config{
procs: iruntime.CPUQuotaToGOMAXPROCS,
minGOMAXPROCS: 1,
}
maxProcs, status, err := cfg.procs(cfg.minGOMAXPROCS)
if err != nil {
return undoNoop, err
}
/*...*/
runtime.GOMAXPROCS(maxProcs)
return undo, nil
}
// go.uber.org/automaxprocs/internal/runtime/cpu_quota_linux.go
func CPUQuotaToGOMAXPROCS(minValue int) (int, CPUQuotaStatus, error) {
cgroups, err := newQueryer()
if err != nil {
return -1, CPUQuotaUndefined, err
}
quota, defined, err := cgroups.CPUQuota()
if !defined || err != nil {
return -1, CPUQuotaUndefined, err
}
maxProcs := int(math.Floor(quota))
if minValue > 0 && maxProcs < minValue {
return minValue, CPUQuotaMinUsed, nil
}
return maxProcs, CPUQuotaUsed, nil
}
// go.uber.org/automaxprocs/internal/runtime/cpu_quota_linux.go
func newQueryer() (queryer, error) {
// 先查询cgroup v2
cgroups, err := _newCgroups2()
if err == nil {
return cgroups, nil
}
// 再查cgroups v1
if errors.Is(err, cg.ErrNotV2) {
return _newCgroups()
}
return nil, err
}
// go.uber.org/automaxprocs/internal/cgroup/cgroups2.go
// cgroups v2
func (cg *CGroups2) CPUQuota() (float64, bool, error) {
cpuMaxParams, err := os.Open(path.Join(cg.mountPoint, cg.groupPath, cg.cpuMaxFile))
if err != nil {
if os.IsNotExist(err) {
return -1, false, nil
}
return -1, false, err
}
defer cpuMaxParams.Close()
scanner := bufio.NewScanner(cpuMaxParams)
if scanner.Scan() {
fields := strings.Fields(scanner.Text())
if len(fields) == 0 || len(fields) > 2 {
return -1, false, fmt.Errorf("invalid format")
}
if fields[_cgroupv2CPUMaxQuotaIndex] == _cgroupV2CPUMaxQuotaMax {
return -1, false, nil
}
max, err := strconv.Atoi(fields[_cgroupv2CPUMaxQuotaIndex])
if err != nil {
return -1, false, err
}
var period int
if len(fields) == 1 {
period = _cgroupV2CPUMaxDefaultPeriod
} else {
period, err = strconv.Atoi(fields[_cgroupv2CPUMaxPeriodIndex])
if err != nil {
return -1, false, err
}
if period == 0 {
return -1, false, errors.New("zero value for period is not allowed")
}
}
return float64(max) / float64(period), true, nil
}
if err := scanner.Err(); err != nil {
return -1, false, err
}
return 0, false, io.ErrUnexpectedEOF
}
从代码可以看出,uber的automaxprocs包会去读进程cgroups(先找cgroups v2,如果没找到再找cgroups v1)中cpu相关数据,最后通过runtime.GOMAXPROCS设置P的数量为cgroup中cpu对应值,从而解决docker容器环境go程序默认设置P的数量为宿主机cpu数量的问题。
微信公众号卡巴斯同步发布,欢迎大家关注。

















 94
94

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









