







二叉查找树,排序二叉树(中序遍历结果是有序序列),二叉搜索树其实说的都是BST树,对于二叉查找树中的每一个非叶子节点,其左子节点的值比当前结点的值小,其右子节点的值比当前结点的值大。
二叉查找树有个特点,那就是对BST树进行中根遍历,得到的结果一定是个有序序列,如果是:左值 < 根值 <右值,得到的就是从小到大的序列。其实原因很简单,中根遍历的书序是左中右,而BST树的建树规则就是左值 < 根值 <右值(当然也可以左值 >根值 >右值,这样得到的结果就是由大到小的序列)。
下面就直接贴码说明,建树(插入)的过程很简单,就不多注释了,删除节点时的操作其实也不复杂,只要理解了最左子节点,就理解了删除的过程。
/*BST.c*/
#include<assert.h>
typedef int RESULT;
#ifndef SUCCESS
#define SUCCESS 0
#endif
#ifndef FAILURE
#define FAILURE -1
#endif
typedef struct _Node
{
struct _Node* plc; /*左字结点指针*/
struct _Node* prc; /*右子结点指针*/
int key; /*key字段*/
int val; /*val字段*/
int cnt; /*计数*/
}Node;
/*建树 插入节点*/
RESULT insert(Node** root, int key, int val);
/*删除指定key的元素*/
RESULT delete(Node** root, const int key);
/*BST.c*/
#include “stdlib.h”
#include “stdio.h”
#include “BST.h”
/*创建节点*/
Node* createnode(int key,int val)
{
Node* node = (Node*)malloc(sizeof(Node));
node->key = key;
node->val = val;
node->cnt = 1;
node->plc = NULL;
node->prc = NULL;
return node;
}
/*插入节点*/
RESULT insert(Node** root, int key, int val)
{
Node* node = createnode(key, val);
if (NULL == *root)
{
if (NULL == node)
{
perror("createnode error!!!\n");
return FAILURE;
}
*root = node;
}
else
{
Node* tmp = *root;
while (1)
{
if (key == tmp->key)
{
tmp->cnt++;
return SUCCESS;
}
else if (key < tmp->key)
{
if (tmp->plc == NULL)
{
tmp->plc = node;
return SUCCESS;
}
tmp = tmp->plc;
continue;
}
else
{
if (tmp->prc == NULL)
{
tmp->prc = node;
return SUCCESS;
}
tmp = tmp->prc;
continue;
}
}
}
return SUCCESS;
}
Node* findleftnode( Node* node,Node** p )
{
*p = node;
while (node->plc != NULL)
{
*p = node;
node = node->plc;
}
return node;
}
/*删除指定key的元素*/
RESULT delete(Node** root,const int key)
{
Node* tmp = *root;
Node* parent = NULL;
int lc_or_rc = 0;/*0代表左子节点,1代表右子节点*/
while (tmp != NULL)
{
if (key == tmp->key)/*找到了要删除的元素*/ {
break;
}
else if (key < tmp->key)/*要找的key在左子树*/ {
parent = tmp;
tmp = tmp->plc;
continue;
}
else/*要找的key在右子树*/ {
parent = tmp;
tmp = tmp->prc;
lc_or_rc = 1;
continue;
}
}
/*未找到或者树本身就为空*/
if (NULL == tmp)
{
printf("don't find the node which needs to delete !!!\n");
return SUCCESS;
}
/*如果找到了,判断是否有重复元素,如果有,将重复元素格式减一就达到了一次伤处的目的,
如果没有这个判断,则直接删除了所有tmp->key值为key的所有重复元素*/
if (tmp->cnt > 1)
{
tmp->cnt--;
}
else
{
Node* n = NULL;
if (tmp->plc == NULL && tmp->prc == NULL)/*如果要删除的节点是叶子节点,直接删除此节点即可(父节点的子节点指针设置为空)*/
{
n = NULL;
}
else if ( tmp->plc == NULL && tmp->prc != NULL)
{
n = tmp->prc;
}
else if ( tmp->plc != NULL && tmp->prc == NULL )
{
n = tmp->plc;
}
else/*如果要删除的不是叶子节点,则需要找出:当前结点右子树中值最小的结点,
根据BST树的性质(小左大右),可以知道,我们要找的其实就是最左子节点(因为小的都是放左边,最边边的当然是最小的),
为什么需要找右子树的最左子节点呢?因为我们要删除tmp这个节点,就得找个节点顶替它的位置,
顶替它位置的元素需要满足BST树的性质,所有,tmp的右子树的最左节点的值(右子树最小值)和tmp节点的值是最靠近的,
,因此用它来代替tmp节点是满足BST树性质的,其实我觉得也可以找左子树的最右子节点*/
{
Node* p = tmp->prc;/**/
Node* node = findleftnode(tmp->prc, &p);/*返回tmp节点右子树的最小节点(不一定是叶子节点),*/
if (node == tmp->prc) /*如果返回的节点就是tmp的右子节点(tmp->prc->plc为NULL)*/
{
node->plc = tmp->plc;/*直接将node的左子节点指向tmp的左子节点*/
}
else/**/
{
if (node->prc != NULL)/*如果node节点有右子节点*/
{
p->plc = node->prc;/*需要将node的右子节点作为node父节点p的左子节点*/
}
else/*如果node没有右子节点,也就是说node是个叶子节点*/ {
p->plc = NULL;
}
node->prc = tmp->prc;/*将tmp节点的左右子节点给node节点*/
node->plc = tmp->plc;
}
n = node;
}
/*如果当前要删除的节点是其父节点的左子节点,则将其父节点的左子节点置NULL*/
if (lc_or_rc == 0) {
parent->plc = n;
}
else/*父节点的右子节点置NULL*/ {
parent->prc = n;
}
free(tmp);/*释放了tmp节点,删除完成*/
tmp = NULL;
}
return SUCCESS;
}
代码仅供描述过程使用,可以运行,但如遇到Bug,希望指出,谢谢!
以上就是BST树的插入节点和删除节点的代码,插入节点的操作很简单,删除节点需要考虑的情况比较多,所有加了很多注释解释清楚。
其实总结一下有以下几种情况,
-
要删除的结点是叶子节点,这种情况最好处理,只需要将其父节点指向自己的指针置为NULL即可。
-
如果待删除节点只有左子树或者只有右子树,只需要将其左子节点或者右子节点的代替自己即可,即父节点指向自己的左子节点或者右子节点
-
如果待删除节点左右子节点都不为空,这个时候就需要找到其右子树中值最小的结点(最左子节点),然后用最左子节点替换掉待删除节点即可。
BST树的性能
平均复杂度 最坏情况复杂度
插入操作 O(logN) O(N)
查询操作 O(logN) O(N)
删除操作 O(logN) O(N)
上面我们可以看到,BST树一般时间复杂度是O(logN),如下度这种情形,
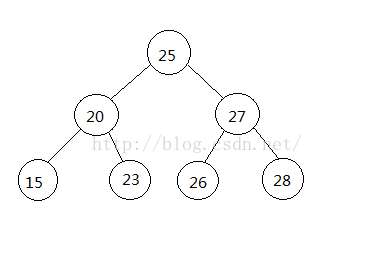
最坏的时间复杂度是O(N),如果你插入的是一个有序序列,那么此时的时间复杂度就是O(N),因为此时树严重失衡,已经退化成链表了。如下图

上面可以看出来,BST树的性能是不稳定的,主要是因为在插入的过程中没有做好树的平衡问题,最终导致二叉树严重失衡,造成最差性能,后面我们将会学习AVL树(自平衡二叉查找树)和RB-Tree(红黑树),这两种树都在插入节点的操作中加入了旋转操作,使得树不至于严重失衡,对于RB-Tree和AVL树的区别,后面的章节也将继续讨论。
BST树的查找和遍历可以参考前面几篇文章的遍历和查找方法,这里就不贴代码了。















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









