



一、引言
在医疗领域,数据驱动的分析与决策正变得愈发重要。通过对医疗数据集的深入挖掘,我们能够洞察患者特征、疾病关联等关键信息,为医疗研究、临床诊断辅助等提供有力支撑。本文将详细介绍如何运用 Python 的数据分析与机器学习库,对医疗数据集展开全方位剖析,从数据预处理、可视化探索到模型构建与评估,一步步揭开医疗数据背后的秘密 。
二、环境搭建与数据准备
(一)库安装与导入
首先,我们需要安装并导入一系列必要的 Python 库。sklearn(scikit-learn )是机器学习领域常用的库,可通过pip install sklearn进行安装。此外,pandas用于数据处理,numpy支持数值计算,matplotlib和seaborn(本文虽未完全用到seaborn但可辅助可视化 )负责数据可视化,具体导入代码如下:
python
运行
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler # 数据处理:标准化
from sklearn.model_selection import train_test_split # 数据处理:训练集和测试集划分
from sklearn.linear_model import LogisticRegression # 分类模型:逻辑回归
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.svm import SVC # SVM
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc # 模型评估
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
mpl.rcParams['font.family'] = 'SimHei' # 设置中文显示问题
plt.rcParams['axes.unicode_minus'] = False # 设置负轴符号显示问题
这些库涵盖了从数据读取、处理、建模到结果可视化的全流程需求,为后续分析奠定基础。
(二)数据读取
我们使用pandas的read_csv函数读取存储在指定路径(D:\aaddff\Medicaldataset.csv )的医疗数据集,代码简单却关键:
python
运行
data = pd.read_csv(r'D:\aaddff\Medicaldataset.csv')
data.head()
通过data.head()可快速查看数据集前几行,初步了解数据的字段、格式等基本情况,比如包含年龄(Age )、性别(Gender )、心率(Heart rate )、血压(收缩压、舒张压 )、血糖(Blood sugar )、肌酸激酶同工酶(CK-MB )、肌钙蛋白(Troponin )等特征字段,这些特征对于分析患者健康状况与潜在疾病关联至关重要。
三、数据预处理:异常值检测与处理
(一)异常值图示探索 —— 箱型图
为了直观了解各特征的分布情况以及可能存在的异常值,我们借助箱型图进行可视化分析。箱型图能清晰展示数据的四分位数、中位数以及异常值(超出 whisker 范围的值 )。我们定义了一个特征映射字典feature_map,方便将英文特征名转换为中文,提升可视化结果的可读性:
python
运行
feature_map = {
'Age': '年龄',
'Gender': '性别',
'Heart rate': '心率',
'Systolic blood pressure': '收缩压',
'Diastolic blood pressure': '舒张压',
'Blood sugar': '血糖',
'CK-MB': '肌酸激酶同工酶',
'Troponin': '肌钙蛋白',
}
plt.figure(figsize=(20, 10))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(2, 4, i)
plt.boxplot(data[col]) # 画箱型图
plt.title(f'{col_name}箱线图')
plt.ylabel('人数')
plt.grid(axis='y', linestyle='--', alpha=0.4)
plt.tight_layout() # 调整子图间距
plt.show()
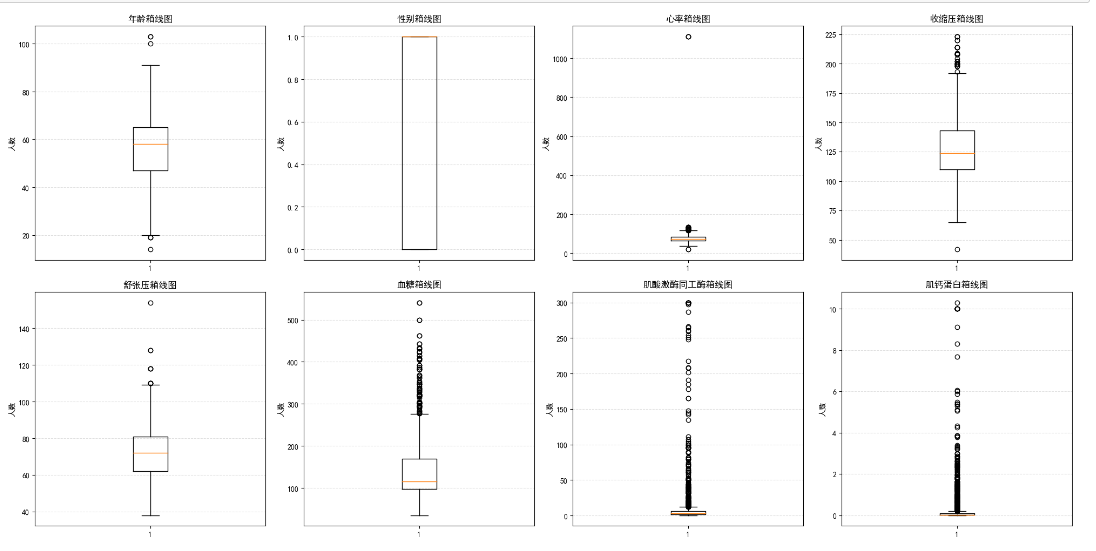
通过箱型图,我们可以快速发现心率、血压等特征中可能存在的异常点,比如心率可能出现极大值,血压也可能存在不合理的数值,这为后续针对性处理异常值提供了依据。
(二)异常值针对性处理
1. 心率异常值处理
从箱型图以及初步分析中,我们发现存在心率大于 1000 的极端异常值,这显然不符合实际医疗常识(正常心率范围一般在 60 - 100 次 / 分钟左右,即使在特殊情况也不会达到 1000 ),因此我们通过条件筛选删除这些异常数据:
python
运行
data = data[data['Heart rate'] < 1000]
2. 收缩压异常值处理
同样,收缩压存在小于 50 的不合理情况(正常收缩压一般不低于 90,即使低血压情况也有一定范围,50 明显异常 ),进行如下筛选删除:
python
运行
data = data[data['Systolic blood pressure'] > 50]
3. 舒张压异常值处理
舒张压大于 140 也属于异常(正常舒张压一般不超过 90,高血压也有对应的诊断标准,140 的舒张压明显不合理 ),执行删除操作:
python
运行
data = data[data['Diastolic blood pressure'] < 140]
4. 舒张压与收缩压逻辑异常处理
在医疗常识中,正常情况下舒张压应小于收缩压。我们需要检查是否存在舒张压大于收缩压的情形,并对这种可能因数据记录错误导致的问题进行修正:
python
运行
wrong_data = data[data['Diastolic blood pressure'] > data['Systolic blood pressure']]
# 可能数据记录反了,将二者调换,将对应index两个血压互换
data.loc[wrong_data.index, ['Systolic blood pressure', 'Diastolic blood pressure']] = data.loc[wrong_data.index, ['Diastolic blood pressure', 'Systolic blood pressure']]
通过上述一系列异常值处理操作,我们让数据集更加贴合实际医疗场景,为后续分析与建模提供更可靠的数据基础。
四、数据可视化探索:洞察特征分布与关联
(一)患者年龄分布
年龄是医疗分析中重要的基础特征,我们通过核密度图与直方图结合的方式,展示患者年龄的分布情况:
python
运行
plt.figure(figsize=(20, 15))
ax1 = plt.subplot(241)
data['Age'].plot(kind='kde', color='r', label='核密度')
data['Age'].plot(kind='hist', bins=12, secondary_y=True)
plt.title('患者年龄分布')
plt.xlabel('年龄')
plt.ylabel('人数')
核密度图(kde )能够平滑地展示年龄分布的整体趋势,而直方图(hist )则以离散的 bins 呈现具体的年龄区间人数分布。从可视化结果中,我们可以观察患者年龄的集中区间、分布形态等,比如是否呈现正态分布趋势,哪个年龄段患者数量较多等,这对于分析不同年龄阶段与疾病的关联有参考意义。
(二)患者性别分布
性别也是影响疾病发生、发展的一个因素,我们使用饼图展示患者的性别分布:
python
运行
ax2 = plt.subplot(242)
gender_data = data['Gender'].value_counts()
plt.pie(gender_data, labels=['男', '女'], startangle=90, autopct='%.1f%%')
plt.title('患者性别分布')
饼图直观地呈现了男女患者在数据集中的占比情况,通过autopct参数还能显示具体的百分比数值,帮助我们快速了解性别分布的均衡性或倾向性,后续可进一步分析不同性别在疾病特征上的差异。
(三)患者心率分布
心率反映了患者的心脏功能状态等信息,同样采用核密度图与直方图结合的方式分析其分布:
python
运行
ax3 = plt.subplot(243)
data['Heart rate'].plot(kind='kde', color='r', label='核密度')
data['Heart rate'].plot(kind='hist', bins=12, secondary_y=True)
plt.title('患者心率分布')
plt.xlabel('心率')
plt.ylabel('人数')
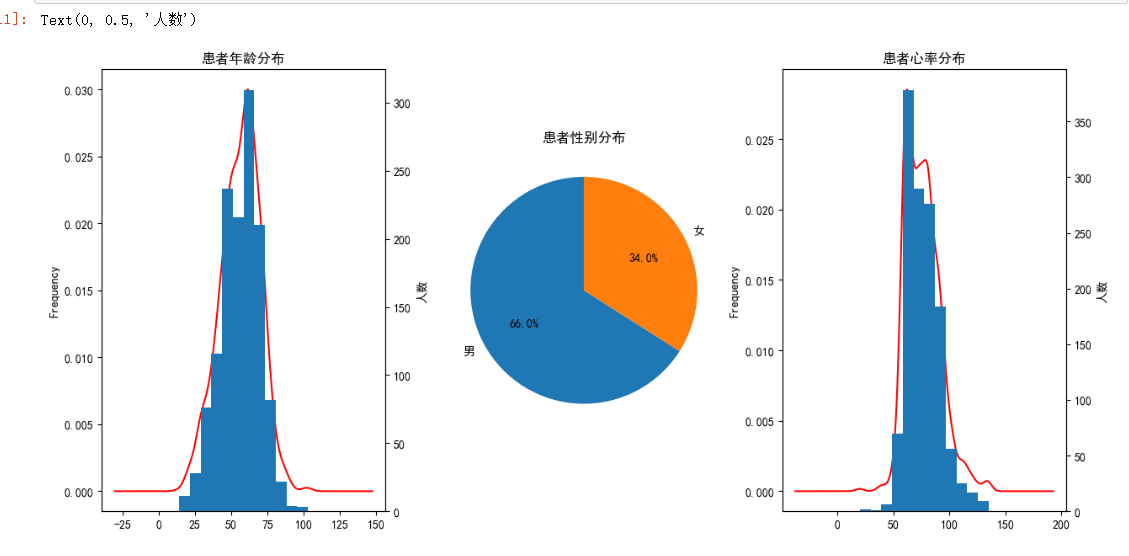
通过该可视化,我们可以知晓患者心率的常见范围、是否存在异常波动(在异常值处理后,分布应更合理 ),以及心率分布与疾病(比如心脏病等,后续可结合疾病标签分析 )之间可能存在的联系,为深入研究提供直观线索。
五、机器学习模型构建准备(拓展方向)
(一)特征工程与数据集划分
虽然上述代码中尚未完全展开模型构建的全流程,但在实际医疗数据分析中,后续可基于处理后的数据进行特征工程操作,比如对类别型特征(如Gender )进行编码(One - Hot 编码等 ),对数值型特征进行标准化(使用StandardScaler )等,让特征更适合机器学习模型输入。然后通过train_test_split划分训练集和测试集:
python
运行
# 假设后续要预测的目标变量为某疾病标签(需数据集中有对应字段,这里假设为'disease_label' )
X = data.drop('disease_label', axis=1) # 特征矩阵
y = data['disease_label'] # 目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 可进一步对X_train和X_test进行标准化等操作
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
(二)模型选择与初步介绍
我们导入了多种经典的机器学习分类模型,如逻辑回归(LogisticRegression )、决策树(DecisionTreeClassifier )、支持向量机(SVC )、随机森林(RandomForestClassifier )等。这些模型各有特点:
- 逻辑回归:简单高效,可解释性强,能给出特征与目标变量之间的线性关联关系(通过系数 ),适合初步探索特征对疾病的影响。
- 决策树:以树结构进行决策,直观易懂,能处理非线性关系,但容易过拟合。
- 支持向量机:在处理小样本、非线性数据时有优势,通过寻找最优分类超平面实现分类,但对数据尺度敏感,需要做好标准化。
- 随机森林:基于决策树的集成学习方法,通过多棵树投票决策,降低过拟合风险,具有较好的稳定性和预测性能,适合处理复杂的医疗数据特征组合。
后续可基于划分好且处理后的训练集和测试集,分别训练这些模型,并使用classification_report、confusion_matrix、roc_curve、auc等评估指标进行模型性能评估,对比不同模型在医疗数据集上的表现,筛选出更适合的模型用于辅助疾病诊断等场景。
六、总结与展望
(一)总结
本文详细展示了运用 Python 对医疗数据集进行分析的完整流程,从环境搭建、数据读取,到异常值检测与处理、数据可视化探索,每一步都为深入挖掘医疗数据价值提供了支撑。通过箱型图等可视化手段,我们能快速发现数据中的异常并针对性处理,让数据更可靠;借助年龄、性别、心率等分布的可视化,初步洞察患者群体特征。同时,也为后续机器学习模型构建做好了铺垫,多种经典模型可用于探索疾病与特征之间的复杂关系 。
(二)展望
在实际应用中,还可进一步拓展分析:
- 模型深化:完善机器学习模型构建流程,尝试更多优化手段,如调参(网格搜索、随机搜索等 )、模型融合( stacking、blending )等,提升模型在医疗诊断辅助等任务中的准确性和可靠性。
- 特征挖掘:深入挖掘特征之间的交互作用,构建更具代表性的特征,比如结合年龄和心率构建新的特征指标,探索其与疾病的关联。
- 多维度分析:若数据集中包含更多维度信息(如患者病史、检查影像特征提取后的数据等 ),可整合进行更全面的分析,为精准医疗提供更丰富的决策依据。
- 临床应用结合:将分析结果与临床实际诊断流程结合,验证模型和分析结论的实用性,真正助力医疗决策,为患者提供更优质的医疗服务。
总之,医疗数据分析是一个充满潜力的领域,通过不断优化分析方法和技术应用,能够为医疗行业的发展注入新的活力,为守护人们的健康发挥更大作用。


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









