







即插即用模块是真的厉害
本文作者认为,传统的L2 Loss有两个很大的缺点:
(1)对人头部定位的约束比较差,MSE倾向于解决density map的值的高频率的变化,但是定位上做的不好,最终的结果是容易导致对高密度区域预测的值偏小,即欠预测,而对稀疏的区域预测的值较大,即容易过预测。
(2)L2 Loss对抗干扰能力差,很容易因为一些噪声值的扰动,导致预测的波动比较大。
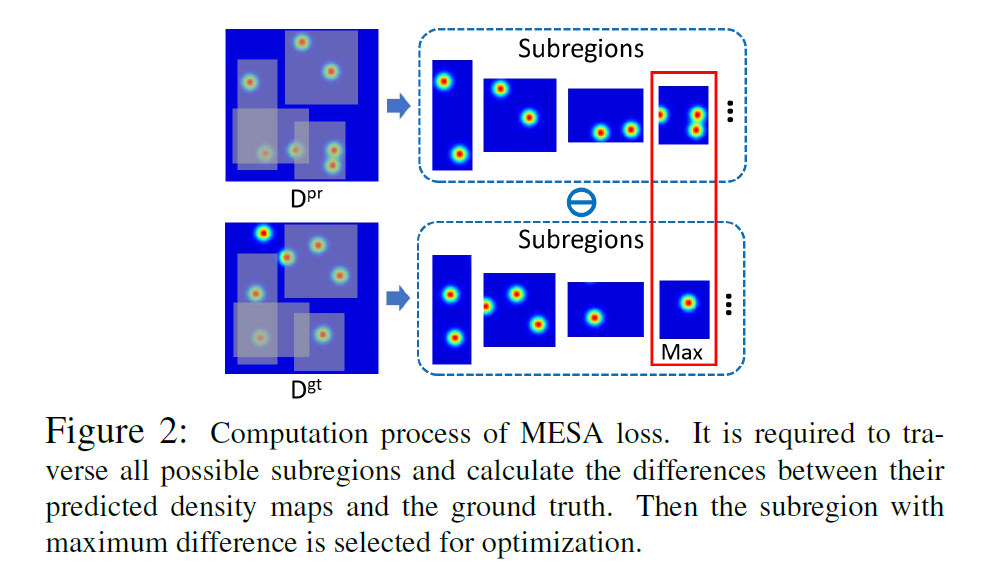
Maximum Excess over SubArrays,即MSEA loss可以通过求出预测的Density Map与GT的差异最大的矩形分区解决这个问题,但是这个过程不可微,无法反向传播,因此作者就改进成了去找误差最大的点,而不是误差最大的区域,设计出了Maximum Excess over Pixels,即MEP loss。

作者认为,(1)像素级别的L2 Loss难以保留Density Map的高频信息:L2 Loss更偏向于过平滑的预测结果,空间感知能力较差;(2)L2 Loss对人群计数中典型噪声高度敏感,包括零均值噪声、头部大小变化和头部遮挡。作者做了一个简单的统计,结果表明零均值噪声与高估的共现率可达96%(7044张测试图像中的6776张)。我们进一步发现,几乎所有估计的密度图都不能准确地预测遮挡发生时的头部位置或大小,这可能导致高密度区域的估计不足。此外,由于标注误差和高斯核的固定方差,生成的地面真值密度也可能不精确。
MSEA loss用来找到差异最大的矩形框,由于该组子区域包括了整张图片,因此MESA loss代表着人群计数预测的上限。只对行人的空间分布敏感,对前文说的典型噪声具有较强的鲁棒性。
作者提出了一个Maximum Excess over Pixels(MEP) loss,该方法不像在MESA中那样寻找不匹配的矩形子区域,而是通过最大像素损失(MEP)来优化与地面真值密度图有较大差异的像素级子区域。为了获得这种像素级的子区域,利用弱监督的等级信息生成一个掩码来指示高差异像素。
现有的人群计数的问题经常被视为密度回归问题,训练集中有N张训练图片 I = { I 1 , I 2 , . . . , I N } \mathbf{I}=\{I_1,I_2,...,I_N\} I={
I1,I2,...,IN},每张图片 I i I_i Ii有 c i c_i ci个头部中心点的位置 P i g t = { P 1 , P 2 , . . . , P c i } \mathbf{P}_i^{gt}=\{P_1,P_2,...,P_{c_i}\} Pigt={
P1,P2,...,Pci}。因此,对于图片 I i I_i Ii中每个像素p的密度图被定义如下: ∀ p ∈ I i , D g t , i ( p ) = ∑ P ∈ P i g t N g t ( p ; μ = P , σ 2 ) \forall p\in I_i,D^{gt,i} (p)=\sum_{P\in\mathbf{P}_i^{gt}}\mathcal{N}^{gt}(p;\mu=P,\sigma^2) ∀p∈Ii,Dgt,i(p)=P∈Pigt∑Ngt(p;μ=P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















09-25
 4220
4220
4220
12-11
3778
3778
07-18
6832
6832
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









