






目录
- kubernetes-kubeadm init从私有仓库拉取镜像
- CentOS 7 yum更改Containerd配置
- kubeadm init 初始化问题
- 重新拉取kubeadm join
- 重新生成token
- 一些操作命令
- 部署网络的坑
- registry.k8s.io/pause:3.6
- 初始化删除代码
kubernetes-kubeadm init从私有仓库拉取镜像
kubernetes-kubeadm init从私有仓库拉取镜像_kubeadm init 从harbor拉取镜像-CSDN博客
全网最详细完整【20分钟使用kubeadm+阿里云镜像源部署kubernetes 1.20.0集群】_阿里源原生的kubesphere怎么结合okg_永远吃不胖的运维攻城狮的博客-CSDN博客
CentOS 7 yum更改Containerd配置
第一种
这里若出现containerd的问题
- 降低containerd的版本
- 对containerd的配置文件修改
#配置文件默认内容
# Copyright 2018-2022 Docker Inc.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
## 删除这里
disabled_plugins = ["cri"]
#root = "/var/lib/containerd"
#state = "/run/containerd"
#subreaper = true
#oom_score = 0
#[grpc]
# address = "/run/containerd/containerd.sock"
# uid = 0
# gid = 0
#[debug]
# address = "/run/containerd/debug.sock"
# uid = 0
# gid = 0
# level = "info"
- 重装containerd
重新安装containerd
第二种
[root@k8s-master01 ~]# kubeadm init --apiserver-advertise-address=192.168.65.103
[init] Using Kubernetes version: v1.28.4
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2023-11-16T14:52:59+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
错误关键字:
"validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
查看日志:
# journalctl -f -u containerd
-- Journal begins at Thu 2023-03-30 15:42:34 HKT. --
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.620700651+08:00" level=info msg="loading plugin \"io.containerd.tracing.processor.v1.otlp\"..." type=io.containerd.tracing.processor.v1
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.620817381+08:00" level=info msg="skip loading plugin \"io.containerd.tracing.processor.v1.otlp\"..." error="no OpenTelemetry endpoint: skip plugin" type=io.containerd.tracing.processor.v1
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.620920032+08:00" level=info msg="loading plugin \"io.containerd.internal.v1.tracing\"..." type=io.containerd.internal.v1
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.621035782+08:00" level=error msg="failed to initialize a tracing processor \"otlp\"" error="no OpenTelemetry endpoint: skip plugin"
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.621195952+08:00" level=info msg="loading plugin \"io.containerd.grpc.v1.cri\"..." type=io.containerd.grpc.v1
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.621572039+08:00" level=warning msg="failed to load plugin io.containerd.grpc.v1.cri" error="invalid plugin config: `systemd_cgroup` only works for runtime io.containerd.runtime.v1.linux"
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.622076402+08:00" level=info msg=serving... address=/run/containerd/containerd.sock.ttrpc
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.622318145+08:00" level=info msg=serving... address=/run/containerd/containerd.sock
Mar 31 15:15:55 debian systemd[1]: Started containerd container runtime.
Mar 31 15:15:55 debian containerd[5314]: time="2023-03-31T15:15:55.626592651+08:00" level=info msg="containerd successfully booted in 0.034138s"
提取错误:
ning msg="failed to load plugin io.containerd.grpc.v1.cri" error="invalid plugin config: `systemd_cgroup` only works for runtime io.containerd.runtime.v1.linux"
改错:
containerd config default | sudo tee /etc/containerd/config.toml
修改 runtime_type 的值
sed -i '96s/runtime_type.*/runtime_type = "io.containerd.runtime.v1.linux"/' /etc/containerd/config.toml
确认修改值
cat -n /etc/containerd/config.toml
86 [plugins."io.containerd.grpc.v1.cri".containerd.default_runtime]
87 base_runtime_spec = ""
88 cni_conf_dir = ""
89 cni_max_conf_num = 0
90 container_annotations = []
91 pod_annotations = []
92 privileged_without_host_devices = false
93 runtime_engine = ""
94 runtime_path = ""
95 runtime_root = ""
96 runtime_type = "io.containerd.runtime.v1.linux"
重启containerd
systemctl restart containerd
journalctl -f -u containerd
# journalctl -f -u containerd
-- Journal begins at Thu 2023-03-30 15:42:34 HKT. --
Mar 31 16:47:50 master01 systemd[1]: Started containerd container runtime.
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.826347892+08:00" level=info msg="Start subscribing containerd event"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.826786123+08:00" level=info msg="Start recovering state"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.828864368+08:00" level=info msg="containerd successfully booted in 0.038659s"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.833400449+08:00" level=info msg="Start event monitor"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.833695542+08:00" level=info msg="Start snapshots syncer"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.833808203+08:00" level=info msg="Start cni network conf syncer for default"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.833906768+08:00" level=info msg="Start streaming server"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.834291549+08:00" level=info msg="ImageCreate event &ImageCreate{Name:sha256:221177c6082a88ea4f6240ab2450d540955ac6f4d5454f0e15751b653ebda165,Labels:map[string]string{io.cri-containerd.image: managed,},XXX_unrecognized:[],}"
Mar 31 16:47:50 master01 containerd[8116]: time="2023-03-31T16:47:50.835290401+08:00" level=info msg="ImageUpdate event &ImageUpdate{Name:registry.aliyuncs.com/google_containers/pause:3.7,Labels:map[string]string{io.cri-containerd.image: managed,},XXX_unrecognized:[],}"
https://zhuanlan.zhihu.com/p/618551600
kubeadm init 初始化问题
[init] Using Kubernetes version: v1.28.2
[preflight] Running pre-flight checks
[WARNING Hostname]: hostname "node" could not be reached
[WARNING Hostname]: hostname "node": lookup node on 8.8.8.8:53: no such host
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
这个错误信息表示在执行Kubernetes集群初始化时遇到了一些问题。具体来说,有以下几个问题:
- 主机名无法解析:无法解析主机名为"node"的IP地址(8.8.8.8)。这可能是因为网络配置问题或者DNS解析问题导致的。
# /etc/hosts
8.8.8.8 node
- 文件已存在:以下文件已经存在,导致初始化失败:
- /etc/kubernetes/manifests/kube-apiserver.yaml
- /etc/kubernetes/manifests/kube-controller-manager.yaml
- /etc/kubernetes/manifests/kube-scheduler.yaml
- /etc/kubernetes/manifests/etcd.yaml
- 端口占用:端口10250已经被占用。这可能是因为其他进程正在使用该端口,或者配置文件中指定了错误的端口号。
要解决这个问题,你可以尝试以下方法:
-
检查网络配置,确保主机名可以正确解析为IP地址。
-
删除已存在的文件,然后重新运行初始化命令。你可以使用以下命令删除这些文件:
sudo rm /etc/kubernetes/manifests/kube-apiserver.yaml
sudo rm /etc/kubernetes/manifests/kube-controller-manager.yaml
sudo rm /etc/kubernetes/manifests/kube-scheduler.yaml
sudo rm /etc/kubernetes/manifests/etcd.yaml
-
检查端口占用情况,确保没有其他进程占用端口10250。如果有,请关闭占用该端口的进程或更改配置文件中的端口号。
-
如果以上方法都无法解决问题,你可以尝试忽略某些预检错误,使用
--ignore-preflight-errors=...参数运行初始化命令。例如:
sudo kubeadm init --ignore-preflight-errors=Hostname,Port-10250
重新拉取kubeadm join
kubeadm token create --print-join-command
如果遇见如同和第一点的问题,就用第一个办法解决。
[root@k8s-node01 ~]# kubeadm join 192.168.65.103:6443 --token 8uunqo.rxib6b3gkwdoua43 --discovery-token-ca-cert-hash sha256:fba5
[preflight] Running pre-flight checks
f^Herror execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "8uunqo"
To see the stack trace of this error execute with --v=5 or higher
错误:
error execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "8uunqo"
解决方案,冲重新生成一个token。
重新生成token
重新生成token要在master节点上。
kubectl create secret generic token-to-join --from-literal=token="new-token"
这里的"new-token",想当于密码,自己整一个就🆗。
基础操作命令
kubectl get nodes 查看join的node
kubectl create secret generic token-to-join --from-literal=token="new-token" 重新生成token
kubeadm init 初始化kubeadm
kubeadm token create --print-join-command重新拉取创建过的token
kubectl get pod --all-namespaces -o wide 获取所有命名空间中Pod信息的Kubernetes命令
kubectl apply -f kube-flannel.yml 运行yml文件
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml 是一个用于删除Kubernetes集群中指定配置文件的指令。
kubectl -n kube-system logs <name>查看没起来的日志
重新应用配置:如果可能的话,尝试删除并重新应用Flannel的配置。这可以通过运行
kubectl delete -f kube-flannel.yml -n kube-system和
kubectl apply -f kube-flannel.yml -n kube-system
命令来完成。
kubectl describe pod <READINESS GATES > -n <INATED NODE> : 这个事查看pod的详细描述。
kubectl get deployments 获取部署
kubectl delete deployment <name> 删除部署
kubectl get service 获取服务
kubectl delete service <name> 删除服务
kubectl get namespaces 获取命名空间
# 查看当前集群的所有的节点
kubectl get node
# 显示 Node 的详细信息(一般用不着)
kubectl describe node node1
# 查看所有的pod
kubectl get pod --all-namespaces
# 查看pod的详细信息
kubectl get pods -o wide --all-namespaces
# 查看所有创建的服务
kubectl get service
# 查看所有的deploy
kubectl get deploy
# 重启 pod(这个方式会删除原来的pod,然后再重新生成一个pod达到重启的目的)
# 有yaml文件的重启
kubectl replace --force -f xxx.yaml
# 无yaml文件的重启
kubectl get pod <POD_NAME> -n <NAMESPACE> -o yaml | kubectl replace --force -f -
# 查看pod的详细信息
kubectl describe pod nfs-client-provisioner-65c77c7bf9-54rdp -n default
# 根据 yaml 文件创建Pod资源
kubectl apply -f pod.yaml
# 删除基于 pod.yaml 文件定义的Pod
kubectl delete -f pod.yaml
# 查看容器的日志
kubectl logs <pod-name>
# 实时查看日志
kubectl logs -f <pod-name>
# 若 pod 只有一个容器,可以不加 -c
kubectl log <pod-name> -c <container_name>
# 返回所有标记为 app=frontend 的 pod 的合并日志
kubectl logs -l app=frontend
# 通过bash获得 pod 中某个容器的TTY,相当于登录容器
# kubectl exec -it <pod-name> -c <container-name> -- bash
eg:
kubectl exec -it redis-master-cln81 -- bash
# 查看 endpoint 列表
kubectl get endpoints
# 查看已有的token
kubeadm token list
(以下这个没整出来,不建议看)
部署网络的坑(flannel网络)
参考这个:https://zhuanlan.zhihu.com/p/627310856
-
运行
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
会出现
1. The connection to the server localhost:8080 was refused - did you specify the right host or port?
这个我只在在node部署flannel组件遇到,这里使用第三种
2. ,[root@k8s-master01 ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml namespace/kube-flannel unchanged clusterrole.rbac.authorization.k8s.io/flannel unchanged clusterrolebinding.rbac.authorization.k8s.io/flannel unchanged serviceaccount/flannel unchanged configmap/kube-flannel-cfg unchanged daemonset.apps/kube-flannel-ds unchanged- 被墙了的话,换一种方式(我这里使用了这个方法)
curl -o kube-flannel.yml https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl apply -f kube-flannel.yml这时候就 /root 路径下就出现这个
kube-flannel.yml文件-
如果还是被墙的话,就本地部署
这个顺序是先在/root创建一个
kube-flannel.yml文件然后再执行
kubectl apply -f kube-flannel.ymlkube-flannel.yml 文件内容
---
kind: Namespace
apiVersion: v1
metadata:
name: kube-flannel
labels:
k8s-app: flannel
pod-security.kubernetes.io/enforce: privileged
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: flannel
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- networking.k8s.io
resources:
- clustercidrs
verbs:
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: flannel
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: flannel
name: flannel
namespace: kube-flannel
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-flannel
labels:
tier: node
k8s-app: flannel
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-flannel
labels:
tier: node
app: flannel
k8s-app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
image: registry.cn-zhangjiakou.aliyuncs.com/test-lab/coreos-flannel:amd64
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
image: registry.cn-zhangjiakou.aliyuncs.com/test-lab/coreos-flannel:amd64
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: registry.cn-zhangjiakou.aliyuncs.com/test-lab/coreos-flannel:amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
Kubernetes 安装flannel组件(本地 kube-flannel.yml 文件
kube-flannel.yml(已修改镜像下载数据源)
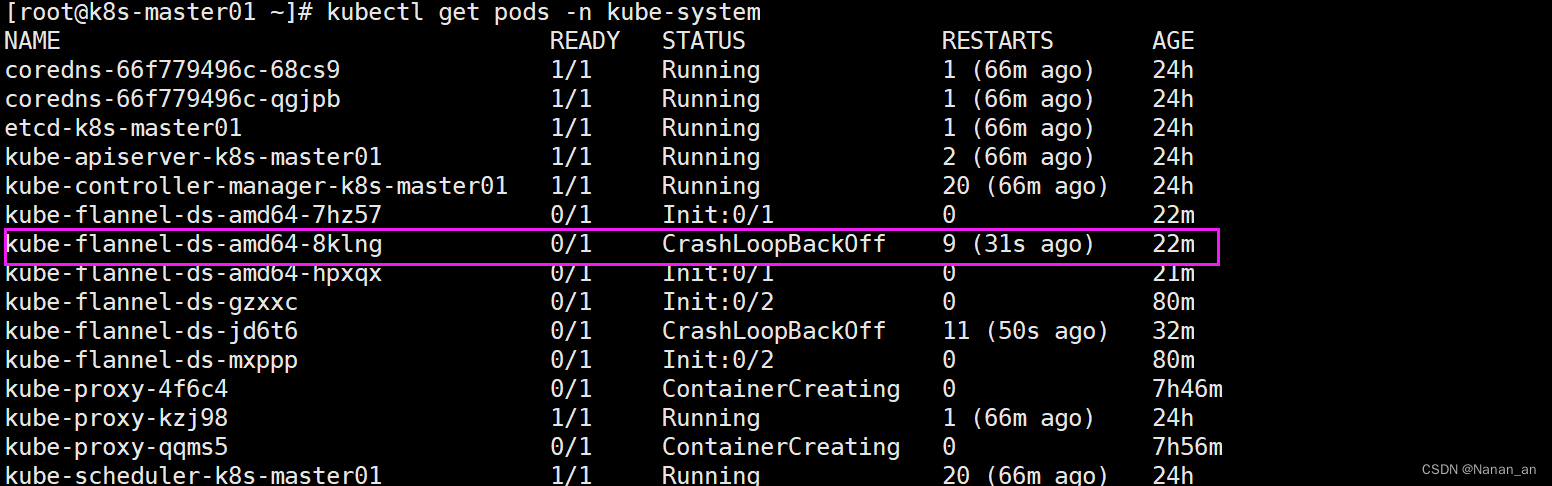
运行后我们发现:没有Runing!!!!!
换成本地yaml内容
kubectl -n kube-system logs <name>查看没起来的日志
日志查看
kubectl -n kube-system logs kube-flannel-ds-amd64-8klng
E1117 11:13:50.358214 1 main.go:234] Failed to create SubnetManager: error retrieving pod spec for 'kube-system/kube-flannel-ds-jd6t6': pods "kube-flannel-ds-jd6t6" is forbidden: User "system:serviceaccount:kube-system:flannel" cannot get resource "pods" in API group "" in the namespace "kube-system"
大意就是:没权限
错误消息表明,用户 “system:serviceaccount:kube-system:flannel” 无法获取在
“kube-system” 命名空间中的 “pods” 资源。这通常是因为RBAC(Role-Based Access
Control)权限配置不正确。
可以用【kubectl get pods -n kube-system -o wide】 可以清楚看出来是哪个节点/IP上pod或者镜像有问题
每一次更改kube-flannel.yml都要先
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
然后再
kubectl apply -f kube-flannel.yml
重新应用配置:如果可能的话,尝试删除并重新应用Flannel的配置。这可以通过运行kubectl delete -f kube-flannel.yml -n kube-system和kubectl apply -f kube-flannel.yml -n kube-system命令来完成。
结论就是。我没整出来
但是是kube-flannel.yml文件的问题。没找到一个合适的kube-flannel.yml文件
k8s安装网络插件flannel 时出现报错Init:ImagePullBackOff 无法安装成功
重新初始化kubeadm init,重新加入节点,重新再来。
registry.k8s.io/pause:3.6
Warning FailedCreatePodSandBox 2m30s (x6 over 17m) kubelet
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to get sandbox image "registry.k8s.io/pause:3.6":
failed to pull image "registry.k8s.io/pause:3.6":
failed to pull and unpack image "registry.k8s.io/pause:3.6":
failed to resolve reference "registry.k8s.io/pause:3.6":
failed to do request: Head "https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.6":
dial tcp 64.233.188.82:443: connect: connection refused
如果没有 containerd
- 生成 containerd 的默认配置文件
containerd config default > /etc/containerd/config.toml- 查看 sandbox 的默认镜像仓库在文件中的第几行
cat /etc/containerd/config.toml | grep -n “sandbox_image”
初始化删除代码
master
[root@k8s-master01 ~]# kubeadm init --apiserver-advertise-address=192.168.65.103 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.28.2 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
[init] Using Kubernetes version: v1.28.2
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
代码
从错误信息来看,主要是端口占用问题和文件已存在问题,以及etcd数据目录未清空问题。以下是一些可能的解决方案的示例代码:
- 解决端口占用问题:
你可以使用lsof命令来查看哪些进程正在使用特定的端口,然后根据需要关闭它们。在你的情况下,需要关闭使用6443、10259、10257、10250、2379和2380端口的进程。示例代码如下:
# 列出使用6443端口的进程并终止它们
lsof -i :6443 | awk '{print $2}' | xargs kill -9
# 重复以上步骤,替换端口为其他被占用的端口
- 解决文件已存在的问题:
你可以尝试删除已经存在的文件,然后再次运行kubeadm init命令。示例代码如下:
# 删除存在的文件
rm -rf /etc/kubernetes/manifests/kube-apiserver.yaml
rm -rf /etc/kubernetes/manifests/kube-controller-manager.yaml
rm -rf /etc/kubernetes/manifests/kube-scheduler.yaml
rm -rf /etc/kubernetes/manifests/etcd.yaml
- 解决etcd数据目录问题:
你需要清空etcd的数据目录。示例代码如下:
# 清空etcd的数据目录
rm -rf /var/lib/etcd/*
然后再次尝试运行kubeadm init命令。















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









