




 RETE算法作为主流规则引擎的核心,通过构建DAG图优化规则匹配,实现高效执行。本文深入探讨RETE算法的工作原理,包括规则编译、运行时执行及特点,详细解释Fact、Rule、LHS、RHS等关键概念。
RETE算法作为主流规则引擎的核心,通过构建DAG图优化规则匹配,实现高效执行。本文深入探讨RETE算法的工作原理,包括规则编译、运行时执行及特点,详细解释Fact、Rule、LHS、RHS等关键概念。
1.算法简介
目前,业界主流的规则引擎使用的算法,都是RETE算法。什么是RETE算法呢,以下算法的定义,是从其他官方博客摘抄而来,同时加入了自己的理解。
Rete 算法最初是由卡内基梅隆大学的 Charles L.Forgy 博士在 1974 年发表的论文中所阐述的算法 , 该算法提供了专家系统的一个高效实现。自 Rete 算法提出以后 , 它就被用到一些大型的规则系统中 , 像 ILog、Jess、JBoss Rules 等都是基于 RETE 算法的规则引擎。
Rete 在拉丁语中译为”net”,即网络。Rete 匹配算法是一种进行大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。
其核心思想是将分离的匹配项根据内容动态构造匹配树(其实是构造一个DAG,有向无环图),以达到显著降低计算量的效果。Rete 算法可以被分为两个部分:规则编译和规则执行 。当 Rete 算法进行事实的断言时,包含三个阶段:匹配、选择和执行,称做 match-select-act cycle。本质上是利用空间换换时间。
2.术语了解
-
Fact,事实对象,对于真实事物或者事实的承载对象,例如:登录事实对象,可能包含:登录ip,用户id,登录设备,近一一小时内登录成功次数,近一小时登录失败次数,可以理解为规则引擎所需要的输入参数。规则引擎会基于Fact对象和规则,构造DAG。
- Rule,规则,由条件构成和结论构成的推理语句。例如:if ... then ... else .....,if 登录ip in 黑产ip列表内,then 命中登录黑名单 else 放行。这里的规则通指,if..then...else...的原子规则,而非多条件多关系的规则集。
- LHS,规则的左半部分,通常指规则的if.... 部分。进一步细化,一般是指,具体的左半边因子,操作符,右半边因子。例如:if 登录ip in 黑产ip列表内。左半边因子即登录ip,操作符即in,右半边因子即黑产ip列表。
- RHS,规则的右半部分,通常指规则的then以及else部分。一般是指具体的action,因为then以及else,往往是对应具体的动作,例如:或者给其他参数赋值(赋值动作),执行其他的函数(执行方法动作)。
- 知识包,知识包是打包了,某一个业务场景下,所有的规则,所有的库文件(Fact元数据描述库,动作库,常量库,枚举库),甚至包括评分卡,决策流等。一个知识包往往是一个业务场景下大的集合,知识包都有版本概念,可以发布新版本的知识包,当有新的知识包发布,所有依赖某个业务规则的客户端,都会更新为最新知识包下的规则。
- Session,session代表一次回话,一个回话往往对应一个工作区,即包括整体流程的执行。
- workmemory,工作区,即执行规则的内存空间,一个workmemory对应一次回话,对应一次规则的执行。
- Rete,由LHS部分构成的规则网络,通常是dag图。
- Agenda,议程,决定执行哪些RHS的Action。
- Action,动作,RHS部分对应的具体动作,例如:赋值,打印参数,执行方法等。
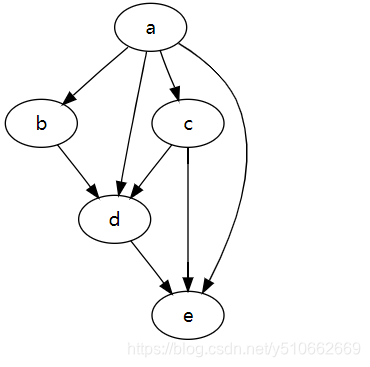
这里插入一段对DAG的解释,dag即有向无环图,在图论中,如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。
例如:
3.核心流程
算法整体分为两部分:1)规则编译和运行时执行,规则编译即把规则编译构造成Rete网络,也即DAG图。2)运行时执行,根据构造的DAG图,带入FACT对象,分配一块workmemory,开始进行匹配执行。
3.1 规则编译
rete网络图
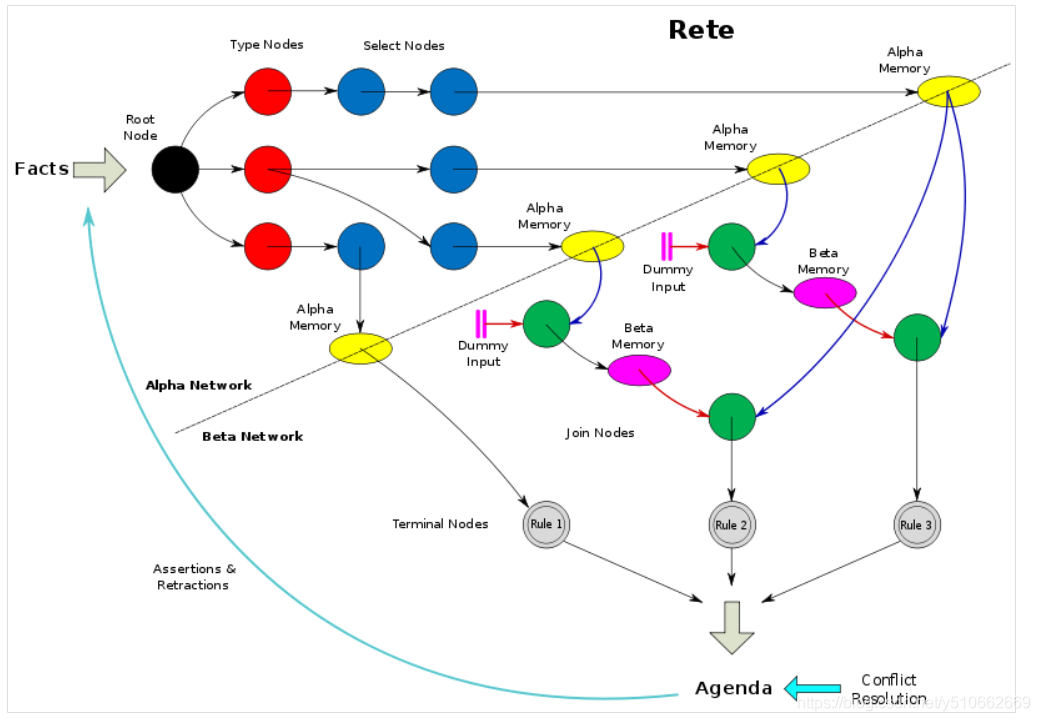
节点解释:
- root node(输入起始节点)
- one-input node(单fact的条件匹配)
- two-input node(多facts的联合join)
- terminal node(终止节点,走到此节点,则规则匹配完成)
one-input node再细分为:
- Type Node:类型节点,有的地方也叫ObjectTypeNode。主要作用:定位事实属性。fact从根节点进入后,会立刻进入TypeNode节点。确定fact的类型,这里是根据class类型去确定,如果是有多个fact对象,则会被拆分为多个TypeNode,例如上文的登录fact则只有一个TypeNode。即上图的红色节点部分。
- Alpha Node:对fact的属性进行匹配判断。Alpha 节点是规则的条件部分的一个模式。通常用于评估字面的条件。例如,登录ip in 黑产ip列表,这个可以理解为一个Alpha Node。在图中AlphaNode未直接体现出来,但是AlphaMemory即AlphaNode所在位置。
two-input node再细分为:
- Beta Node:则相对更为复杂一些,需要实现了两个fact的关联与匹配。作用:用来对2个对象进行对比、检查。约定BetaNode的2个输入称为左边(Join Node)和右边。左边通常是一个a list of objects,右边(Not Node)通常是 a single object。每个Bate节点都有自己的终端节点等组成。BetaNode具有记忆功能,左边输入的叫做BetaMemory,会记住所有的语义,右边输入叫做Alpha Memory,会记住所有到达过的对象。
- Join Node:用于连接操作的节点,相当于and。属于Beta Node类型节点。
- Not Node:根据右边输入对左边输入的对象数组进行过滤,两个NotNode可以完成 exists 检查。
- LeftInputAdapterNodes: 将单个对象转化成对象数组。
例子(来自IBM DEVELOPER论坛):
rule
when
Cheese( $cheddar : name == "cheddar" )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar" );
end
rule
when
Cheese( $cheddar : name == "cheddar" )
$person : Person( favouriteCheese != $cheddar )
then
System.out.println( $person.getName() + " does not like cheddar" );
end说明:
两个Fact对象,Cheese与Person,即两个TypeNode, Cheese与Person。即两个Alpha Node,Cheese.name与Person.favouriteCheese,
但是此处Person.favouriteCheese不能严格称之为AlphaNode,这个应该是BetaNode。
从图上可以看到,编译后的RETE网络中,AlphaNode是共享的,而BetaNode不是共享的。两条规则的BetaNode的不同。然后这两条规则有各自的Terminal Node。即:AlphaMemory是共享的,BetaMemory是不共享的
例子(真实的案例):
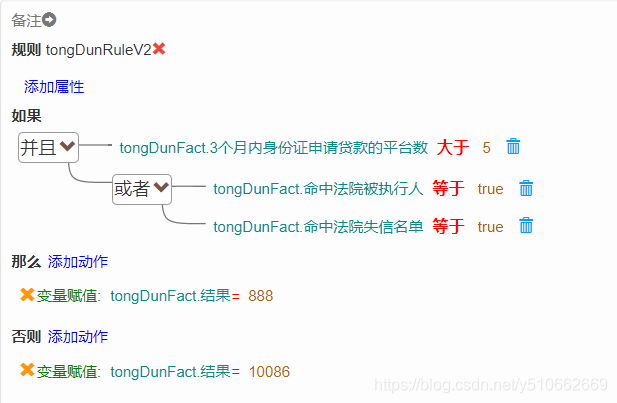
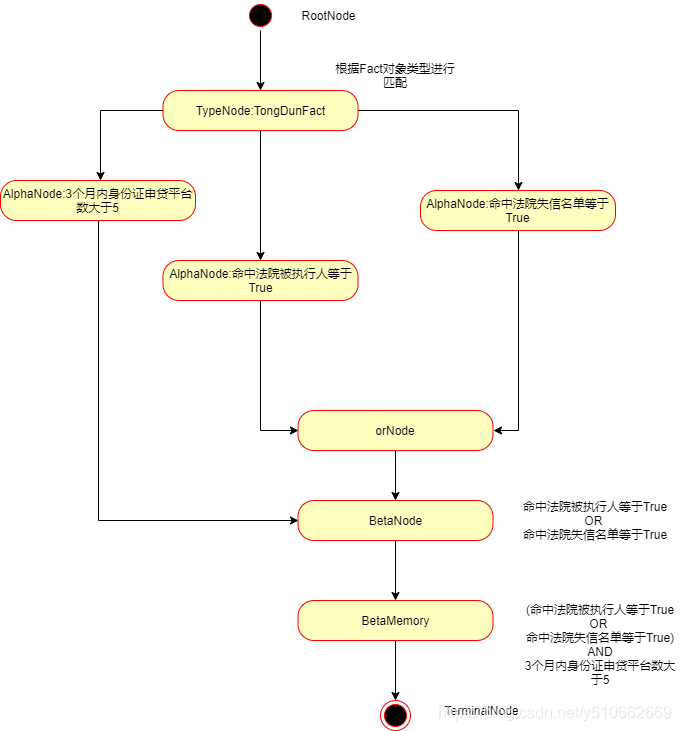
3.2 运行时执行
匹配过程如下:
1) 对于每个事实,通过 select 操作进行过滤,使事实沿着 rete 网达到合适的 alpha 节点。
2) 对于收到的每一个事实的 alpha 节点,用 Project( 投影操作 ) 将那些适当的变量绑定分离出来。使各个新的变量绑定集沿 rete 网到达适当的 bete 节点。
3) 对于收到新的变量绑定的 beta 节点,使用 Project 操作产生新的绑定集,使这些新的变量绑定沿 rete 网络至下一个 beta 节点以至最后的 Project。
4) 对于每条规则,用 project 操作将结论实例化所需的绑定分离出来。
如果把 rete 算法类比到关系型数据库操作,则事实集合就是一个关系,每条规则就是一个查询,再将每个事实绑定到每个模式上的操作看作一个 Select 操作,记一条规则为 P,规则中的模式为 c1,c2,…,ci, Select 操作的结果记为 r(ci), 则规则 P 的匹配即为 r(c1)◇r(c2)◇…◇(rci)。其中◇表示关系的连接(Join)操作。
Rete 网络的连接(Join)和投影 (Project) 和对数据库的操作形象对比,如图所示:
3.3 Rete算法的特点
优点:
a. Rete 算法是一种启发式算法,不同规则之间往往含有相同的模式,因此在 beta-network 中可以共享 BetaMemory 和 betanode。如果某个 betanode 被 N 条规则共享,则算法在此节点上效率会提高 N 倍。
b. Rete 算法由于采用 AlphaMemory 和 BetaMemory 来存储事实,当事实集合变化不大时,保存在 alpha 和 beta 节点中的状态不需要太多变化,避免了大量的重复计算,提高了匹配效率。
c. 从 Rete 网络可以看出,Rete 匹配速度与规则数目无关,这是因为事实只有满足本节点才会继续向下沿网络传递。
不足:
a. RETE 算法使用了β存储区存储已计算的中间结果, 以牺牲空间换取时间, 从而加快系统的速度。然而β存储区根据规则的条件与事实的数目而成指数级增长, 所以当规则与事实很多时, 会耗尽系统资源 。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









