







 本文介绍了在机器学习场景中处理ID类特征的几种常见方法:OneHot、Multi-OneHot、统计学方法及Embedding等,并详细解释了每种方法的应用场景和技术细节。
本文介绍了在机器学习场景中处理ID类特征的几种常见方法:OneHot、Multi-OneHot、统计学方法及Embedding等,并详细解释了每种方法的应用场景和技术细节。
在处理实际的机器学习问题的过程当中,常常会遇到id类特征的情况,例如推荐场景内的用户id,用户性别,商品id等。这里,将平时使用和学习到的常见解决思路进行一个总结。
1. OneHot
这种方式是最常见的id类特征处理方式,这种情况下,id类特征可枚举,每种取值情况占一位取1,其他位取0。例如性别分为男、女、未知。那么“男”表示为[1,0,0]。
2. Multi-OneHot
除了上述情况外,一种变量还可能同时具备有多种取值的情况。例如,在电商场景下,一个用户可能在历史行为中与多个商品发生交互,此时,描述用户交互物品的OneHot就存在大于1位为1的情况了,比如[1,0,0,1,0].
3. 统计学方法
使用统计学方法表示id类特征一般指的是对id特征在具备统计意义(出现频次,共现次数等)的维度上进行表示,较为常见的统计模型有词袋模型、TFIDF等。模型通过计算id序列内各id的相关统计值,组成新向量表示原来id序列。
4. Embedding
如果id特征维度取值范围过大,上述两种方式极易造成特征维度过大且样本稀疏的情况。其实如果你选用logistic regression来拟合样本数据的话,基本用不到embedding,因为LR非常适合用于大规模稀疏样本数据。但是如果你想尝试神经网络相关模型,这个时候就需要将稀疏的OneHot结果进行embedding,得到特征的稠密表示。Embedding是一个很大的技术范畴,下面介绍一些常用的方法。
4.1 Unsupervised Sequence Embedding
目前无监督embedding方法主要应用于序列化的特征或数据当中。其中较为经典的有word2vector,glove等。word2vec想法起源于NLP,但逐步应用于各类有序序列的场景中,其原理可以参考https://zhuanlan.zhihu.com/p/26306795。
word2vec的思路可以应用到很多场景。在商品推荐场景下,使用word2vector,结合用户历史购买序列,可以学习到item的向量化表示,即item2vec,另外还可以引申出song2vec(歌曲embedding),moive2vec(电影embedding)。
4.2 Graph Embedding
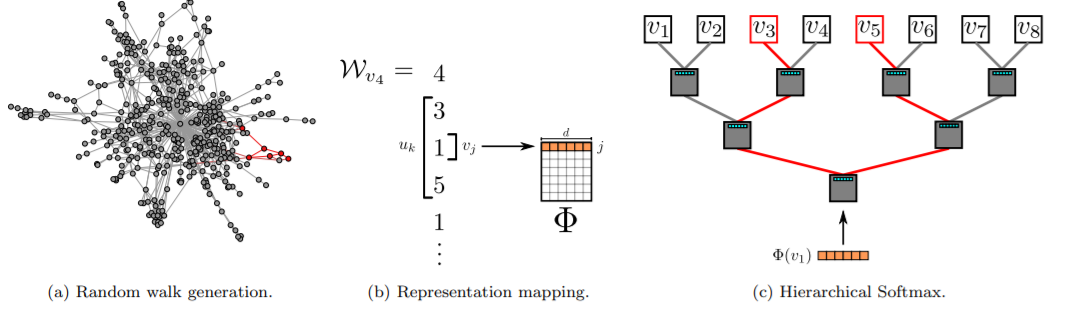
如果id类特征具备类似图状的联系,可采用基于图算法的模型学习特征的embedding表示,典型的如deepwalk,graph embedding等。类似于word2vec,deepwalk。先采用随机漫步的方式获得id序列,然后使用word2vec得到每个id的embedding结果。
4.3 DNN嵌入层
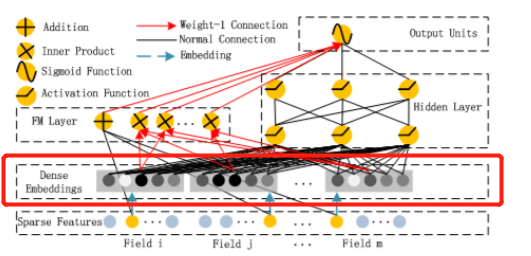
相比于无监督的embedding方法,在DNN中输入层后添加嵌入层,使id类型特征的embedding表示通过训练得到。大部分应用在推荐场景的主流推荐模型,如DeepFM/DIN,均采用这种embedding layer的方式对id类特征进行embedding后再接后续的操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









