







这一节主要讲如何评估和改善机器学习算法。
1. Evaluating a Learning Algorithm
1.1 Deciding what to do next
如果目前的机器学习算法在新的样本中出现了较大的误差,一般情况下,我们会选择:
- 找更多的训练样本
- 删除某些特征
- 增加某些特征
- 增加某些多项式特征
- 减小lambda值
- 增大lambda值
但是这些只是主观的解决办法,下面主要讲如何定量的对机器学习算法进行评估诊断和改善。

1.2 Evaluating a Hypothesis
如何评估假设函数的准确性?
(1)如果只含有一个特征,则可以通过画图观察假设函数是否有过拟合和欠拟合问题
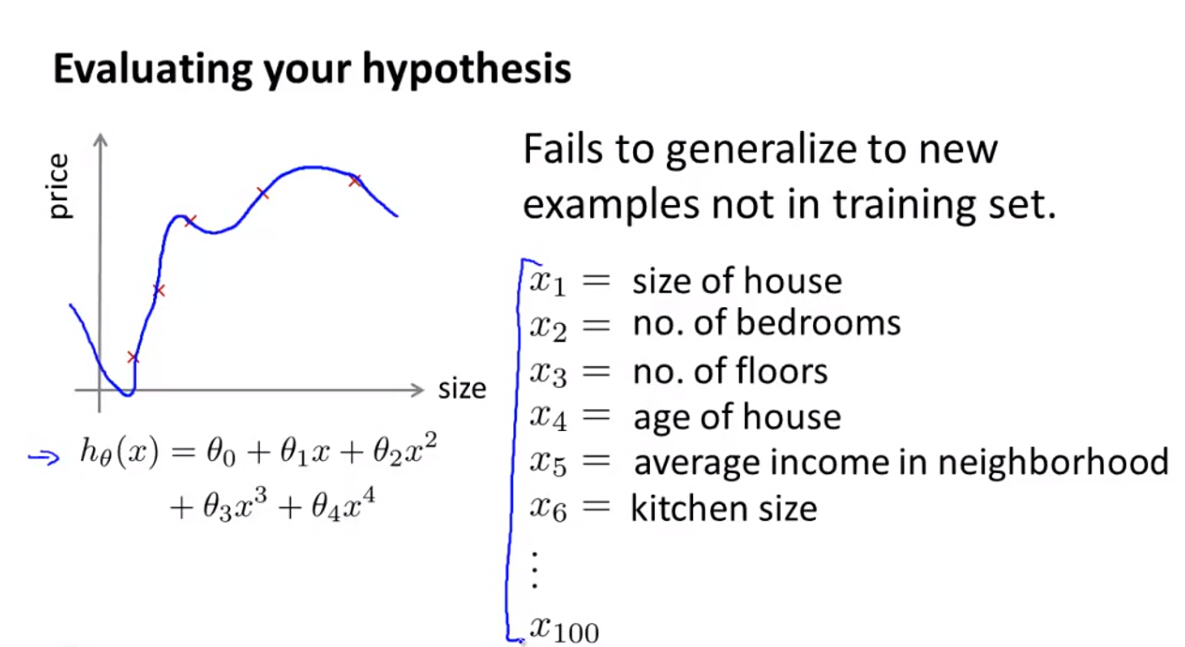
(2)如果含有多个特征向量,则无法通过画图进行观察评估,一般的做法是把训练数据集分成两部分:一个是训练数据集(70% of original training examples),一个是测试数据集(30% of original training examples)。
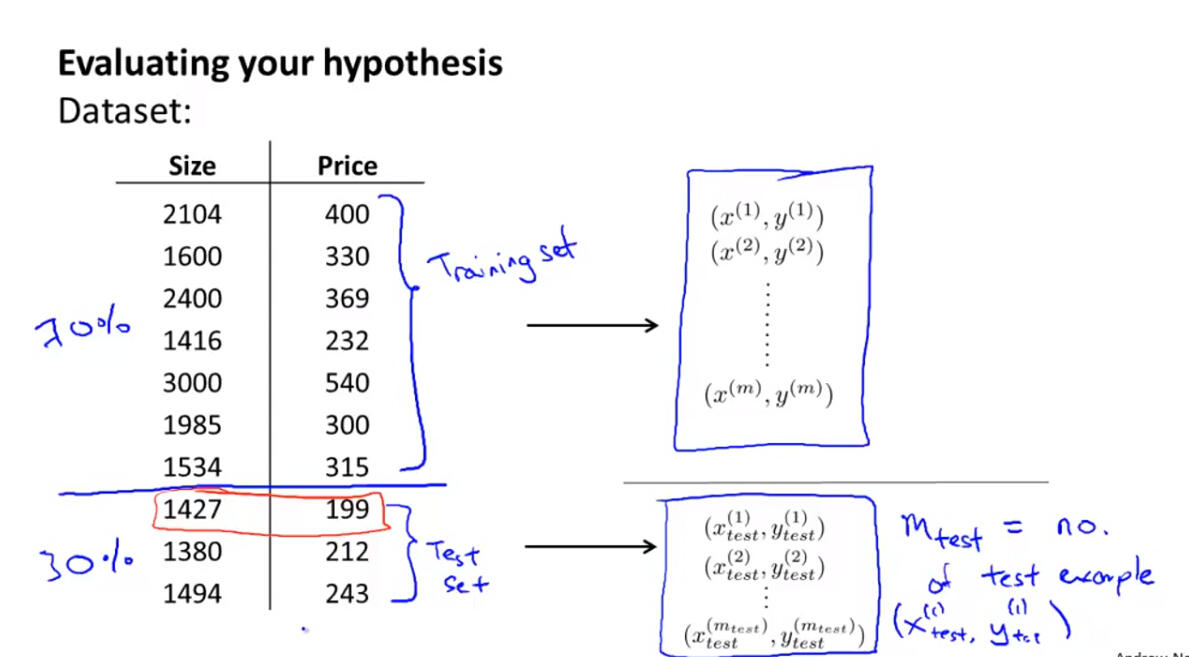
(3)利用训练数据集和测试数据集对线性回归模型的评估流程
- 利用训练样本得到假设函数的参数
- 利用测试数据集得到假设函数的误差平方和,即代价函数的值评估算法

(4)利用训练数据集和测试数据集对逻辑回归模型的评估流程
- 利用训练数据集得到假设函数的参数 θ
- 利用测试数据集得得到逻辑回归模型代价函数的值来评估算法或者计算分类错分率对算法进行评估。

1.3 Model Selection and Train/Validation/Test Sets
(1)上一节中知道了如何评估一个模型的误差,这节中主要讲针对不同的模型,如何选择?
如果只是用测试数据集来评估每个模型,然后选出最优模型,则该模型的泛化能力较差,

(2)为了模型选择,通常的做法是将数据集分为三个部分:训练集,交叉验证集和测试集。
- 利用训练集得到每个模型的参数 θ ,
- 利用交叉验证集得到每个模型的交叉误差 Jcv(θ)
- 根据交叉误差 Jcv(θ) 选出最佳模型
- 利用测试集对模型的泛化能力进行检验。



2. Bias vs. Variance
2.1 Diagnosing Bias vs. Variance
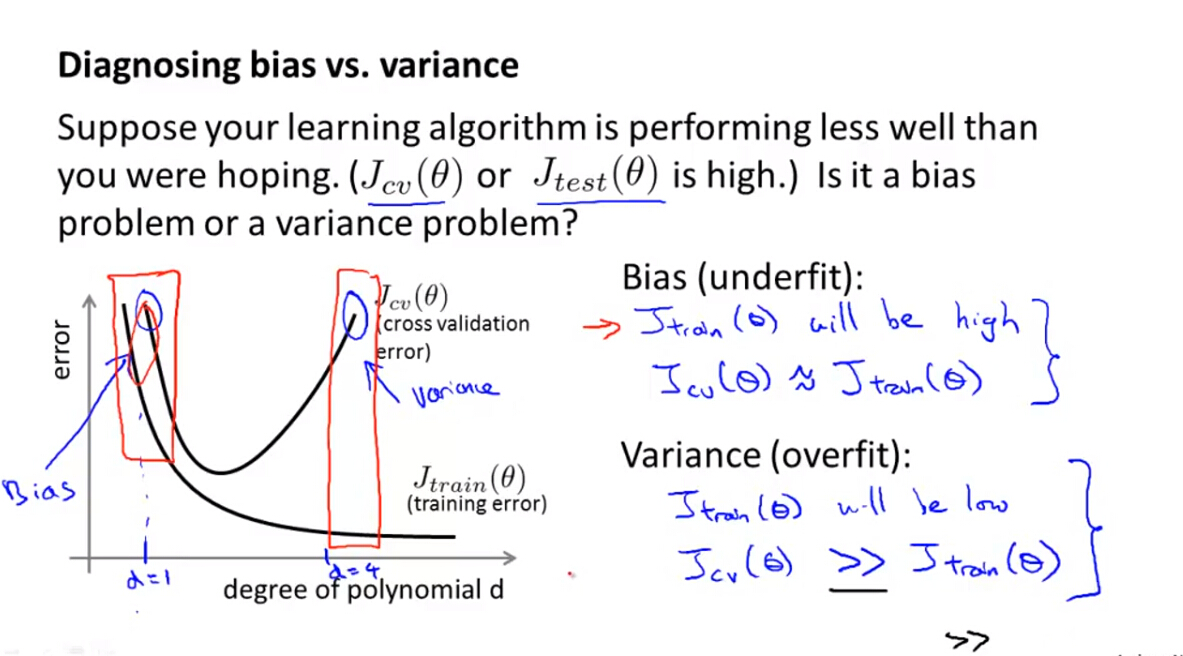
(1)高偏差和高方差是机器学习算法经常出现的问题,那么如何判断一个机器学习算法出现了哪种情况呢?
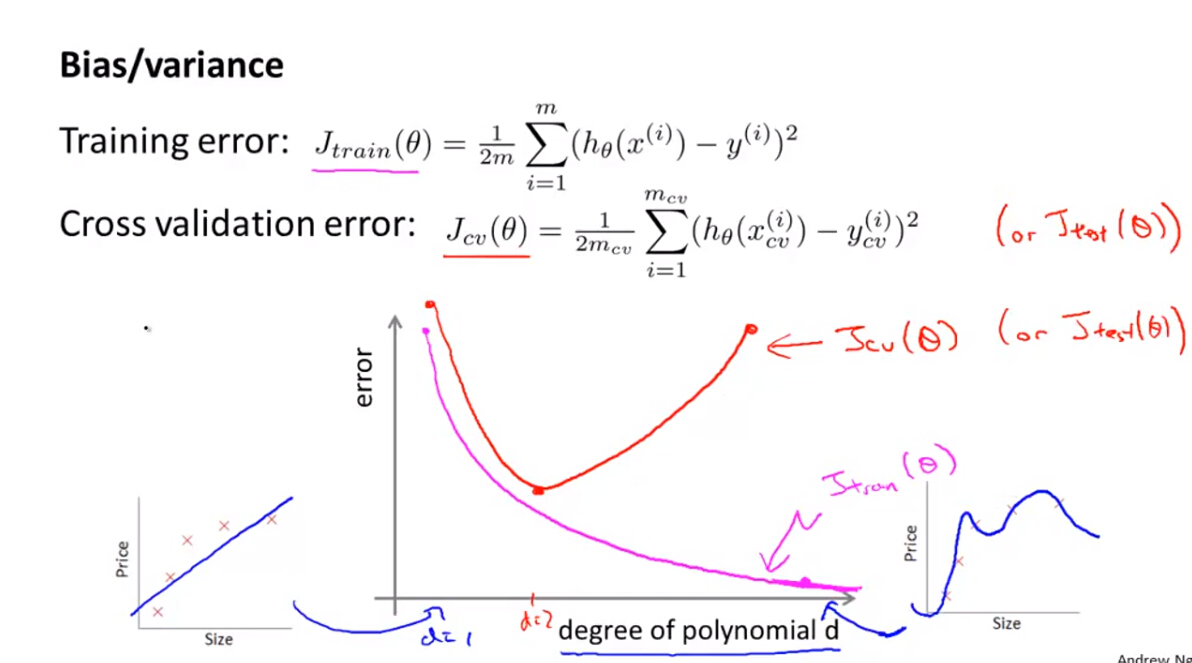
以线性拟合为例,通过绘画误差(训练误差,交叉验证误差)关于多项式次数的函数曲线,我们可以发现,高偏差和高方差具有以下特征:
- 高偏差High Bias
- 训练误差和交叉验证误差均比较高,而且大致相等
- 高方差 High Variance
- 训练误差比较小,但是交叉验证误差比较大
2.2 Regularization and Bias/Variance
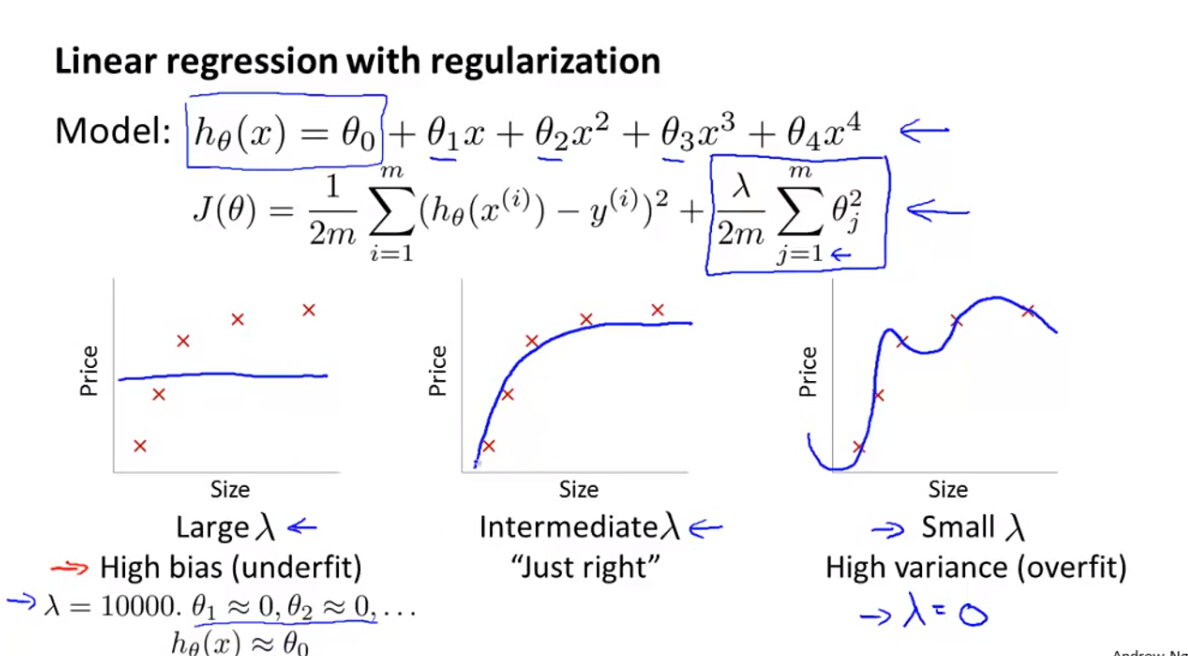
(1)引入正则化项可以有效的解决算法过度拟合的问题,以正则化线性回归模型为例,我们可以看到:
- 当 λ 很大时,模型会出现欠拟合问题
- 当 λ 很小时,模型会出现过度拟合问题
但是如何选择合适的正则化项值 λ 呢?
(2)我们定义不带正则化项的训练误差,交叉验证误差和测试误差用来选择最优的lamda得值
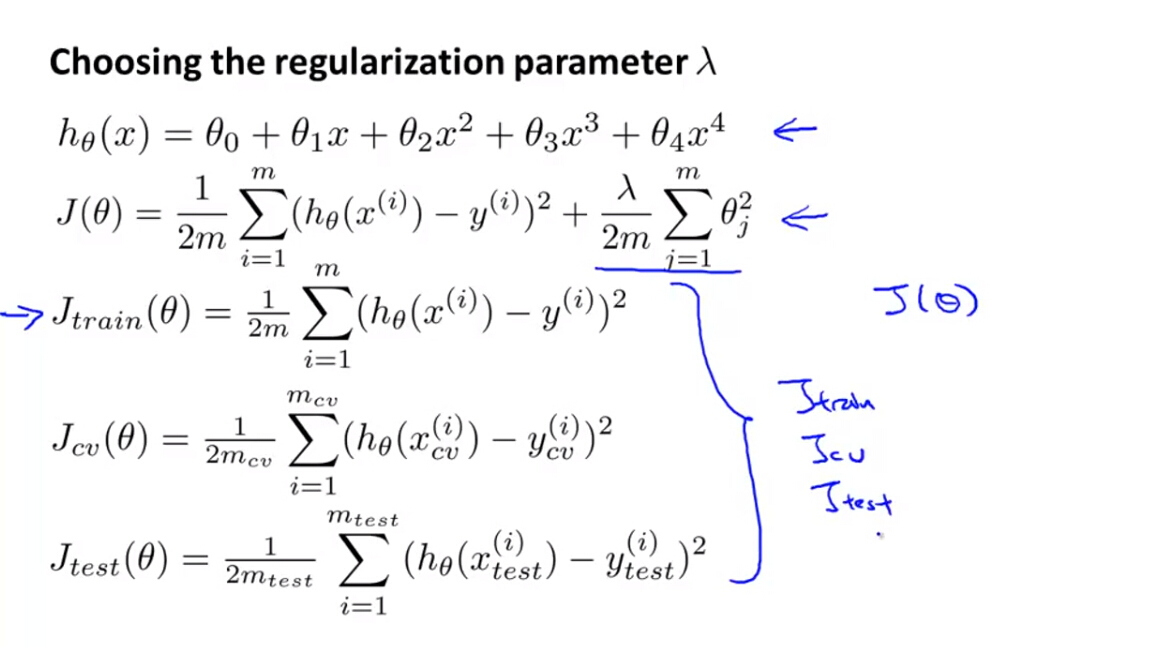
(3)假如有一系列的 λ 值,利用训练集最小化代价函数分别得到参数集,然后利用交叉验证集和无正则化的交叉验证误差公式算出每个 λ 对应的交叉验证误差,选择最优模型,然后选择测试集对最优模型的泛化能力进行验证。

(4)通过上面的例子,我们可以通过画出误差(不带正则项的训练误差和交叉验证误差)关于 λ 的变化曲线,我们可以发现(与之前的多项式分析结果一致):
- 高偏差High Bias
- 训练误差和交叉验证误差均比较高,而且大致相等
- 高方差 High Variance
- 训练误差比较小,但是交叉验证误差比较大

2.3 Learning Curves
(1)误差(不带正则项的训练误差和交叉验证误差)关于训练样本数量的变化曲线称为学习曲线,可以用于诊断一个机器学习算法(模型)是否处于高偏差和高方差的问题。通过绘图,我们可以发现,随着训练样本数量的增加,训练误差逐渐增大,交叉验证误差逐渐降低。
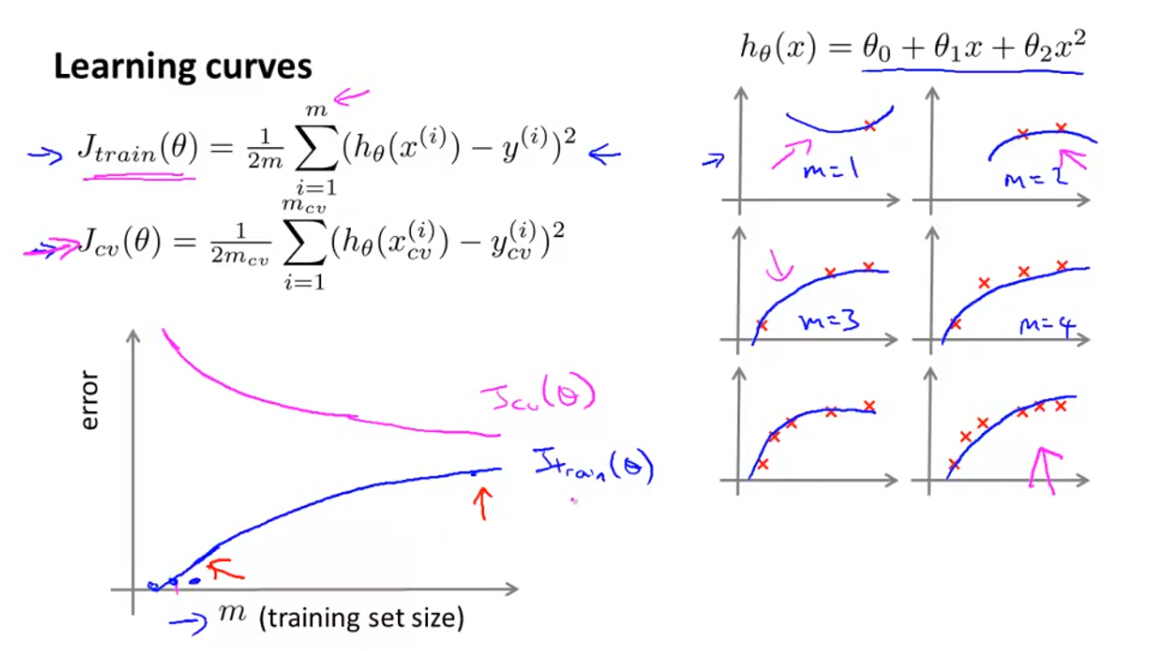
(2)High Bias
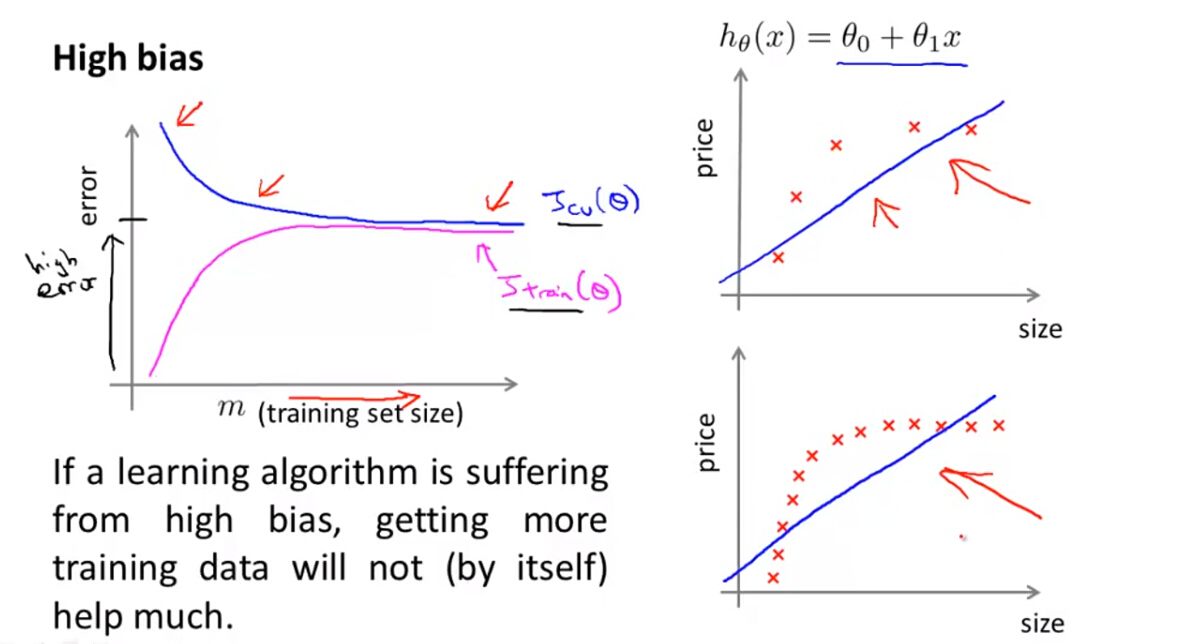
如果一个算法或模型的学习曲线出现以下特征,则说明该算法或模型出现了高偏差的问题:
- 随着样本数量的增加,交叉验证误差下降到某一值基本保持不变,训练误差上升到某一值基本保持不变
- 交叉验证误差和训练误差比较接近,基本重合
- 训练误差和交叉验证误差的值都很大
我们可以得出:如果一个模型正处于高偏差的问题,获得更多的样本对模型的改善帮助不大。
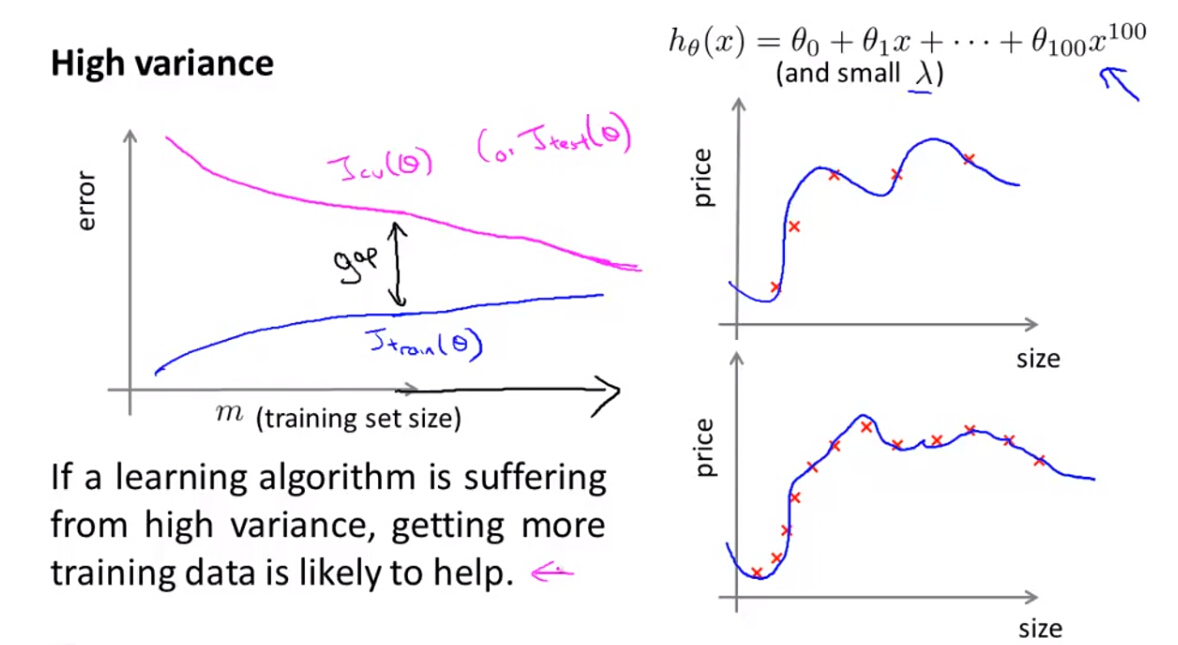
(3)High Variance
如果一个算法或模型的学习曲线出现以下特征,则说明该算法或模型出现了高方差的问题:
- 随着样本数量的增加,交叉验证误差迅速下降,训练误差逐渐升高,
- 但是交叉验证误差和训练误差相差较大,训练误差明显小于交叉验证误差
- 随着样本数量的继续增加,交叉验证误差和训练误差会重合得到一个最优值。
我们可以得出:如果一个模型正处于高方差的问题,获得更多的样本对模型的改善有一定的帮助。
2.4 Deciding What to Do Next Revisited
(1)当我们通过学习曲线,诊断出现在的模型或算法存在的高偏差和高方差问题,那么我们下一步该如何通过什么方法来解决高偏差和高方差问题呢?
| High Bias | High Variance |
|---|---|
| 获取更多的特征 | 获取更多的样本 |
| 获取更多的多项式特征 | 减小特征数量 |
| 减小 λ | 增大 λ |

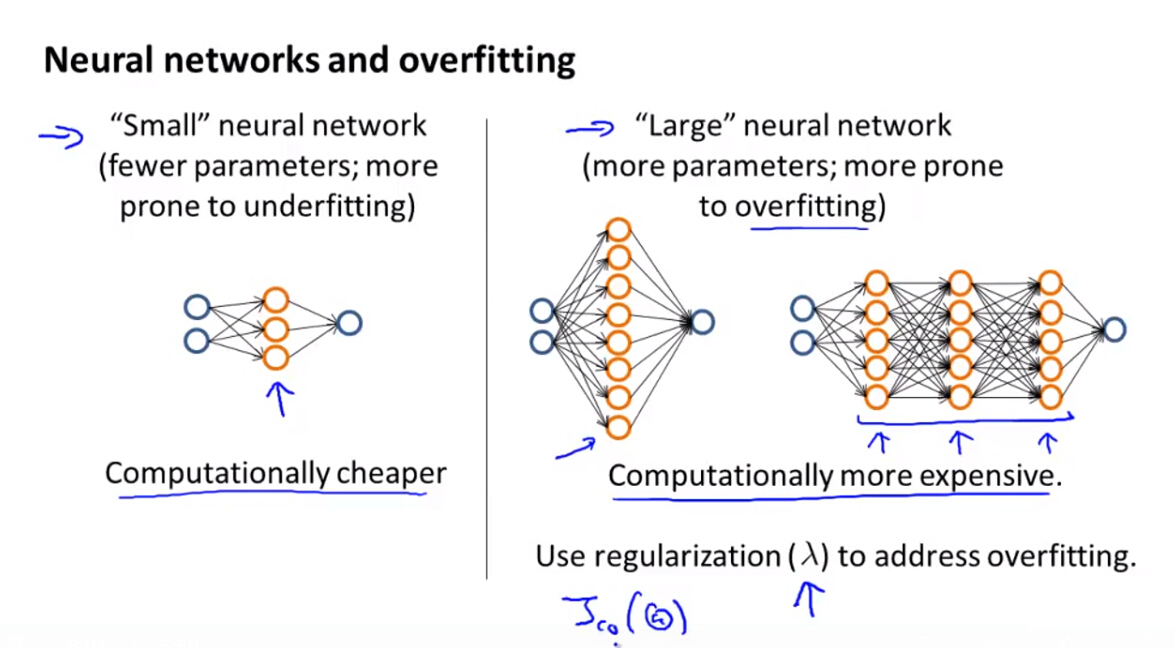
(2)对于神经网络,一般隐藏层越多,隐藏层中的神经元越多,模型越复杂,容易出现过拟合问题















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









