







这部分内容主要讲的是,在应用机器学习算法之后,如果我们发现训练集误差,交叉验证集或者测试集误差比较大的时候,算法在哪出现了问题?我们应该采取哪些措施?
我们先举2个例子
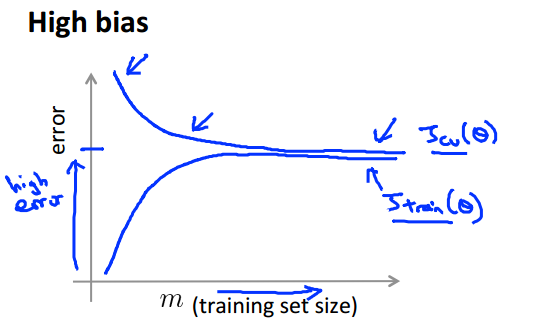
当我们的训练集已经比较大,然而验证误差和训练误差依然很大,而且二者相近,这个时候,我们说这种情况是高偏差的,对于这种情况,我们盲目地去增加训练集并没有卵用额,具体怎么做,请往下看。
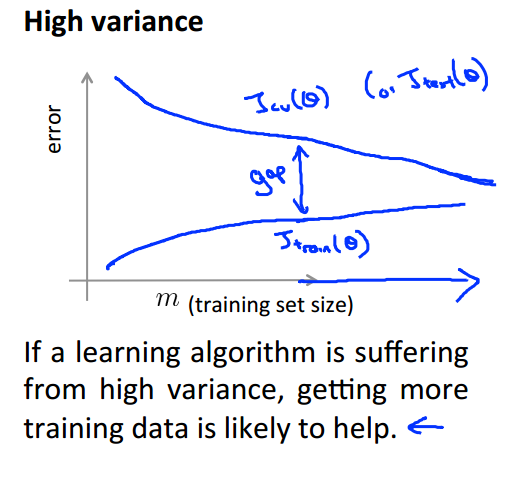
当我们的训练误差很小,而交叉验证集误差很大,但随着训练集变大,2者差距不断变小的时候,我们说这种情况是高方差的,对于这种情况,你再怎么增加特征值也不会有什么同的,具体咋做,还是往下看。
首先我们先看看偏差和方差的概念:
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
换句话说,高偏差(high bias)代表着欠拟合(underfit),高方差代表过度拟合(overfit).
什么时候会发生高方差(high variance)和高偏差(high bias)呢?
交叉验证(训练集,交叉验证集,测试集)中:
毫无疑问,无论是高方差,高偏差,测试集的误差都挺大的。
当我们发现训练集的误差很大,交叉验证集的误差也很大,那么,我们可以认为是当前算法是高偏差(欠拟合)的。
当我们发现训练集的误差很小,然而交叉验证集的误差却很大,那么,我们可以认为当前算法是高方差(过度拟合)的。
为什么会出现高方差和高偏差?
高方差(过度拟合)
我们选取的特征值,特征值组成的多项式比表示真实模型需要的参数还要多的多。
高偏差(欠拟合)
我们选取的特征值,特征值组成的多项式不足以表示真实模型。
当遇到高方差,高偏差,我们应该怎么做?
高方差(过度拟合)
- 获取更多的训练集(大家再看一下方差的概念就知道为什么要更多训练集了)
- 尝试减少一些特征值
- 在正则化的算法中,试着加大lambda的值
高偏差(欠拟合)
- 试着增加一些特征值
- 试着增加更多的多项式
- 在正则化的算法中,试着减小lambda的值















 4269
4269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









