







 本文详细介绍了Python中的函数特性,如位置参数、关键字参数、缺省参数、不定长传递,以及文件操作,包括打开、读取、写入和追加,同时涉及lambda匿名函数和文件编码。
本文详细介绍了Python中的函数特性,如位置参数、关键字参数、缺省参数、不定长传递,以及文件操作,包括打开、读取、写入和追加,同时涉及lambda匿名函数和文件编码。
第七章 函数
多个返回值

def test_return():
return 1, "hello", True
x,y,z = test_return()
print(x)
print(y)
print(z)1
hello
True传入的参数

位置参数
定义:调用函数时根据函数定义的参数位置来传递参数
要求:传递的参数和定义的参数的顺序及个数必须一致
def user_info(name, age, gender):
print(f"您的名字是{name},您的年龄是{age},您的性别是{gender}")
user_info("Tom", 20, "女")您的名字是Tom,您的年龄是20,您的性别是女关键字参数
定义:函数调用时通过“键=值”形式传递参数。
要求:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
def user_info(name, age, gender):
print(f"您的名字是{name},您的年龄是{age},您的性别是{gender}")
# 可以不按照固定顺序传参
user_info(gender = "女",age = 20, name = "Tom")
# 可以和位置参数混用,位置参数必须在前,且匹配参数顺序
user_info("Tom",gender = "女",age = 20)您的名字是Tom,您的年龄是20,您的性别是女
您的名字是Tom,您的年龄是20,您的性别是女缺省参数
定义:缺省参数也叫默认参数,为定义函数的参数提供默认值,调用函数时可不传该默认参数的值
要求:所有位置参数必须出现在默认参数前,包括函数定义和调用
作用:函数调用时,如果为缺省参数传值则修改默认参数值,否则使用这个默认值
def user_info(name, age, gender = "男"):
print(f"您的名字是{name},您的年龄是{age},您的性别是{gender}")
user_info("Tom", 20)
user_info("Rose", 18, "女")您的名字是Tom,您的年龄是20,您的性别是男
您的名字是Rose,您的年龄是18,您的性别是女报错的情况
def user_info(name = "小天", age, gender):
print(f"您的名字是{name},您的年龄是{age},您的性别是{gender}")
user_info("小黑", 20, "男")不定长传递
位置传递
定义

def user_info(*args):
print(f"args的类型是{type(args)},args的内容是{args}")
user_info("小黑")
user_info("男", 20, "Tom")args的类型是<class 'tuple'>,args的内容是('小黑',)
args的类型是<class 'tuple'>,args的内容是('男', 20, 'Tom')关键字传递
要求:

def user_info(**kwards):
print(f"kwards的类型是{type(kwards)},kwards的内容是{kwards}")
user_info(gender = "女",name = "Tom")kwards的类型是<class 'dict'>,kwards的内容是{'gender': '女', 'name': 'Tom'}函数作为参数传递
这是一种,计算逻辑的传递,而非数据的传递。
# 定义一个函数,接收另一个函数作为传入参数
def test_func(compete):
result = compete(1, 2)
print(result)
# 定义一个函数,准备作为传入参数传入另一个函数
def compete(x, y):
return x + y
# 调用,并传入函数
test_func(compete)3就像上述代码那样,不仅仅是相加,相见、相除等任何逻辑都可以自行定义并作为函数传入。
lambda匿名函数
说明

定义语法

def test_func(compete):
result = compete(1, 2)
print(result)
def compete(x, y):
return x + y
test_func(compete)
test_func(lambda x, y:x + y)3
3第八章 文件
文件编码
概念


文件读取
文件操作三步走
(1)打开文件
(2)读写文件
(3)关闭文件
操作

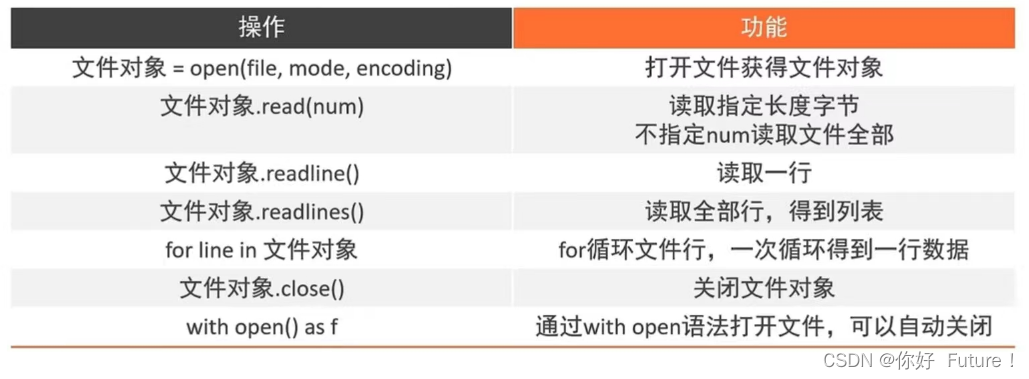
打开文件

f = open("C:/Users/18757/Desktop/love.txt","r", encoding = "UTF-8")
print(type(f))<class '_io.TextIOWrapper'>读文件
read()

f = open("C:/Users/18757/Desktop/love.txt","r", encoding = "UTF-8")
# 读取文件 - read()
print(f"读取10个字节的结果:{f.read(10)}")
print()
print(f"read方法读取全部字节的结果:{f.read()}")
print(f"read方法读取全部字节的结果:{type(f.read())}")读取10个字节的结果:记住,复试的本质不是
read方法读取全部字节的结果:一场考试,
而是一场自我展示!
你应该做的是,
在这短短的二十分钟时间内,
尽可能地展现出自己的优势,
让老师对你感兴趣!
read方法读取全部字节的结果:<class 'str'>readlines()

f = open("C:/Users/18757/Desktop/love.txt","r", encoding = "UTF-8")
# 读取文件 - readlines()
lines = f.readlines() # 读取文件的全部行,每一行作为一个元素,封装到列表中
print(f"lines对象的类型:{type(lines)}")
print(f"lines对象的内容:{lines}")
lines对象的类型:<class 'list'>
lines对象的内容:['记住,复试的本质不是一场考试,\n', '而是一场自我展示!\n', '你应该做的是,\n', '在这短短的二十分钟时间内,\n', '尽可能地展现出自己的优势,\n', '让老师对你感兴趣!']readline()

f = open("C:/Users/18757/Desktop/pythontext/love.txt","r", encoding = "UTF-8")
# 读取文件 - read()
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f"第一行数据是:{line1}")
print(f"第二行数据是:{line2}")
print(f"第三行数据是:{line3}")
print(f"第三行数据的格式是:{type(line3)}")第一行数据是:黑马程序员!!!学python最佳选择
第二行数据是:月薪过万
第三行数据是:
第三行数据的格式是:<class 'str'>for循环读取行
f = open("C:/Users/18757/Desktop/love.txt","r", encoding = "UTF-8")
# for循环读取行
for line in f:
print(f"每一行数据是:{line}--每行数据类型是{type(line)}")每一行数据是:记住,复试的本质不是一场考试,
--每行数据类型是<class 'str'>
每一行数据是:而是一场自我展示!
--每行数据类型是<class 'str'>
每一行数据是:你应该做的是,
--每行数据类型是<class 'str'>
每一行数据是:在这短短的二十分钟时间内,
--每行数据类型是<class 'str'>
每一行数据是:尽可能地展现出自己的优势,
--每行数据类型是<class 'str'>
每一行数据是:让老师对你感兴趣!--每行数据类型是<class 'str'>close()

f = open("C:/Users/18757/Desktop/love.txt","r", encoding = "UTF-8")
for line in f:
print(f"每一行数据是:{line}")
# 关闭文件
f.close()每一行数据是:记住,复试的本质不是一场考试,
每一行数据是:而是一场自我展示!
每一行数据是:你应该做的是,
每一行数据是:在这短短的二十分钟时间内,
每一行数据是:尽可能地展现出自己的优势,
每一行数据是:让老师对你感兴趣!另注:for循环结束后会自动关闭文件
import time
f = open("C:/Users/18757/Desktop/love.txt","r", encoding = "UTF-8")
# for循环结束后会自动关闭文件
for line in f:
print(f"每一行数据是:{line}")
time.sleep(1000)
在1000秒内可以打开文件不受影响,说明文本文档已经关闭了
课后练习

f = open("C:/Users/18757/Desktop/word.txt","r", encoding = "UTF-8")
# 方式1:读取全部内容,通过字符串count方法统计itheima单词数量
count = f.read().count("itheima")
print(f"itheima在文件中出现了;{count}次")itheima在文件中出现了;6次f = open("C:/Users/18757/Desktop/word.txt","r", encoding = "UTF-8")
# 方式2:一行一行读取,通过字符串count方法统计itheima单词数量
count = 0
for line in f:
count += line.count("itheima")
print(f"itheima在文件中出现了;{count}次")
itheima在文件中出现了;6次写文件


f = open("C:/Users/18757/Desktop/love.txt","w", encoding = "UTF-8")
f.write("Hello World!!!") # 内容写入到内存中
f.flush() # 将内存中积攒的内容,写入到硬盘的文件中
f.close() # close方法,内置了flush的功能的
f = open("C:/Users/18757/Desktop/love.txt","w", encoding = "UTF-8")
f.write("黑马程序员!!!") # 内容写入到内存中
f.close() # close方法,内置了flush的功能的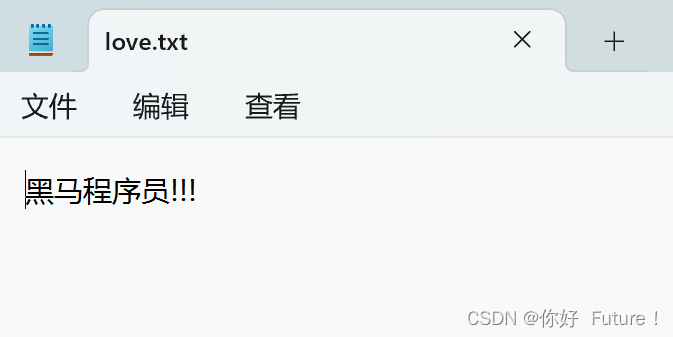
追加写入


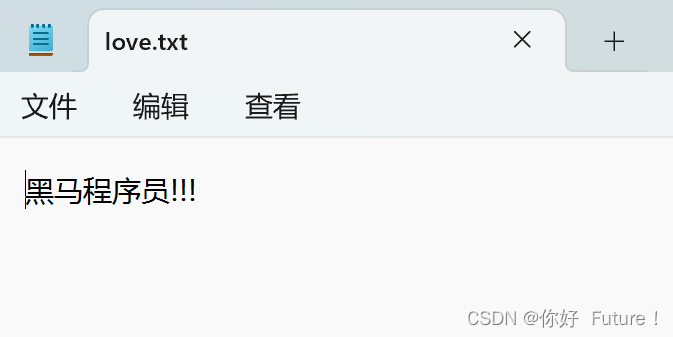
f = open("C:/Users/18757/Desktop/love.txt","a", encoding = "UTF-8")
f.write("学python最佳选择")
f.close()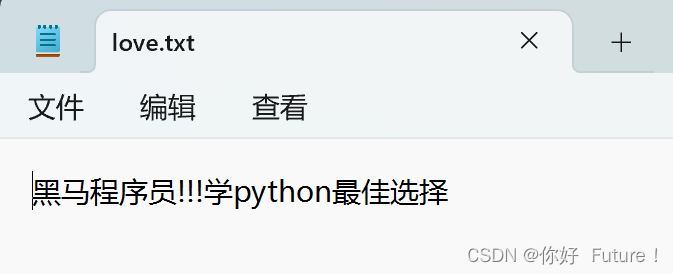
f = open("C:/Users/18757/Desktop/love.txt","a", encoding = "UTF-8")
f.write("\n月薪过万")
f.close()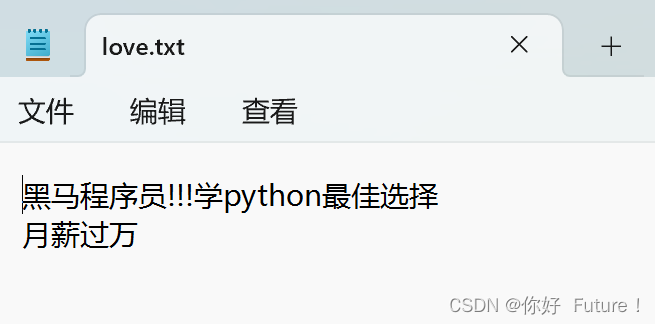
案例
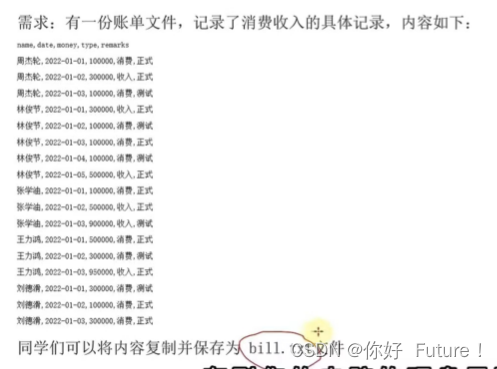
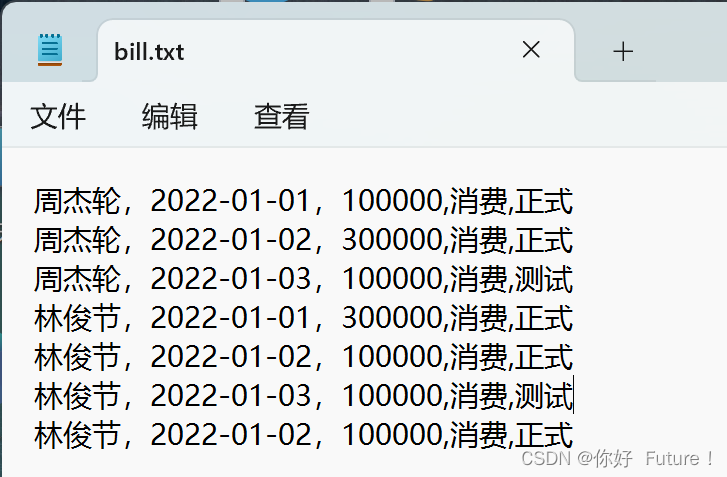
f = open("C:/Users/18757/Desktop/bill.txt","w", encoding = "UTF-8")
f.write("周杰轮,2022-01-01,100000,消费,正式\n周杰轮,2022-01-02,300000,消费,正式\n周杰轮,2022-01-03,100000,消费,测试\n")
f.close()
f = open("C:/Users/18757/Desktop/bill.txt","a", encoding = "UTF-8")
f.write("林俊节,2022-01-01,300000,消费,正式\n林俊节,2022-01-02,100000,消费,正式\n林俊节,2022-01-03,100000,消费,测试\n林俊节,2022-01-02,100000,消费,正式")
f.close()
(只写了部分内容,内容太多了)















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









