







1. Contribution
- 提出了一种通用的、原则性的参数选择共享方案,每个尺度的子网络具有独立和共享模块
- 为网络中的特征变换模块提出了一种嵌套跳跃连接结构,它对应于单个变换模块中的高阶残差学习
- 建立了一个更大、更高质量的数据集,其中包含5290个模糊/清晰图像对,以帮助网络训练。(同GoPro数据集构建的程序相同)
1.1 Parameter Selective Sharing
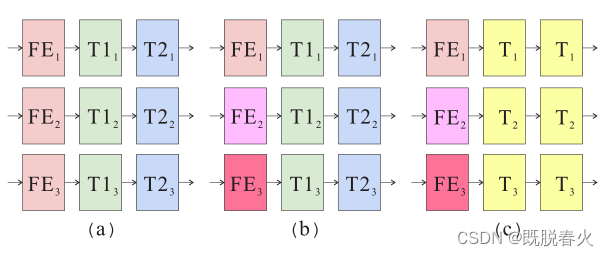
对于从粗到精式的去模糊网络,已有的网络结构参数共享与否大致有两种方式,首先是三个尺度参数独立;另一种就是三个尺度参数共享。
本文想要探究的就是参数如何共享的问题,具体考虑为两个问题:
- 什么样的参数可以共享
- 一个尺度内不同模块的参数是否可以共享
仔细考虑参数共享与否的问题,实际上就是考验一套参数能否处理不同尺度的问题。之前的一篇加入了循环模块的网络应该在这方面有优势,参数共享,循环模块可以记忆粗尺度的中间特征。但它仍然存在这样的问题。
本文经过分析,认为在原图模糊的情况下,其较低尺度的图片是相对尖锐,清晰的。锐利区域中的特征相似,因为下采样的锐利边缘仍然锐利。然而,模糊区域中的特征不同,因为模糊边缘在缩小后变得尖锐。如果特征提取模块跨尺度共享,则无法同时提取尖锐和模糊特征。当模型已经学会了从粗尺度中提取尖锐特征时,就不能提取细尺度中的模糊特征。
但根据scale-recurrent论文中提出的观点:尽管尺度不同,参数应该一致,因为解决的是同一个问题。
仔细考虑这个观点,这里说的参数一致更谨慎地来说应该是去模糊的过程是一致,而对特征提取这一块的参数应该没有特殊要求,特征提取模块能够适应不同尺度输入的图片,这无可厚非,因此,就出现了本文的参数选择性共享方案。
其具体实现的方式就是先用不共享参数的模块提取不同尺度的特征,然后运用共享参数的模块来对特征进行相同的从模糊到清晰的变换。受传统的迭代去模糊的启发,本文认为同一个变换模块内的参数应该共享。
1.2 Nested Skip Connections
这部分的依据是原文:“根据经验,拟合残差的残差比原始残差映射更容易。”
因此,提出了一种将残差递归扩展的方式,在视觉上类似于DenseNet,但有两点区别:
- 这里的跳跃连接是值求和而不是通道堆叠
- 跳跃方式稍有不同(DenseBlock是对所有的输出进行连接,这里也连接了输入)
1.3 Network Architecture
首先使用3 * 3卷积核,理论上两层3 * 3卷积层可以覆盖一个5 * 5的卷积层,但参数量减少四分之一。
网络架构类似于尺度递归网络,但也改变了许多。首先,不再存在中间的循环神经网络模块ConvLSTM;其次,不再存在ResBlock,这部分被本文提出的一个变换模块所代替。所谓的变换模块实际上是有四个处理单元,每个处理单元中有两个卷积层,因此一个变换模块有8个卷积层,每一阶段中有一个特征提取层,即一个卷积层,两个变换模块,共16层。
值得注意的是变换模块中,每个处理单元之间采用的是上述提出的嵌套跳跃连接。
2 Loss
L2范数。每一尺度求和。
Experiment
Dataset
GoPro数据集中的清晰图片有一系列的缺点:
- 严重的噪声
- 较大的平滑区域(较大的平滑区域的影响)
- 显著的图像模糊
为了提高性能,就按照构建GoPro数据集的方式建立了一个新的数据集。构建时,选取视频遵循三个准则: - 相机是稳定的,避免记录高速车辆或物体(为了确保在清晰图片中无物体运动或相机运动)
- 在白天录制室外视频,降低噪声水平
- 仅对具有足够细节的场景进行采样,避免大的平滑区域,如天空或恒定背景。
最后建成了一个有5290对模糊/清晰图片
Training time
4000 epochs
评价指标
- P S N R PSNR PSNR
- S S I M SSIM SSIM
- T i m e Time Time
相关方法
【From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur】CVPR 2017
【Deep multi-scale convolutional neural network for dynamic scene deblurring 】CVPR 2017
【Scale-recurrent network for deep image deblurring】 CVPR 2018
【Dynamic scene deblurring using spatially variant recurrent neural networks】CVPR 2018















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









