







一、实验目的
1、为初等函数运算语言构造LR语法分析器。
2、掌握LR语法分析器的方法,加深对自上而下语法分析原理的理解。
3、掌握设计、编制并调试LR语法分析程序的思想和方法。
二、实验内容
一、根据初等函数运算语言运算法则,将语法模式用上下文无关文法表达。(纸上作业)
1、注意运算的优先级问题,避免产生二义性文法。
二、将上述文法改写为SLR文法。(纸上作业)
三、根据SLR文法给出预测分析表。(纸上作业)
四、根据预测分析表,给出解析SLR文法的递归下降子程序或预测分析器程序。
五、本语法分析程序的输入是实验一生成的记号流;本程序需定义语法树的数据结构;语法分析的输出是一棵语法树。
六、当输入存在语法错误时,需给出语法错误的提示,指出语法错误发生的位置和错误类型。
三、上下文无关文法
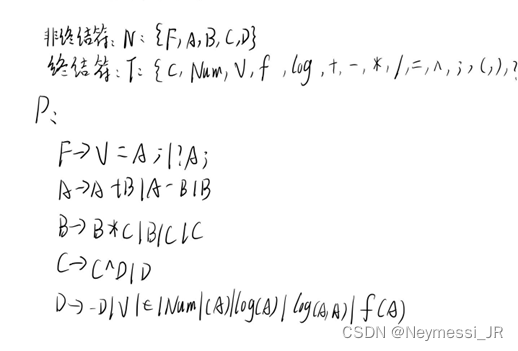
四、SLR扩广文法

五、移进规约分析表
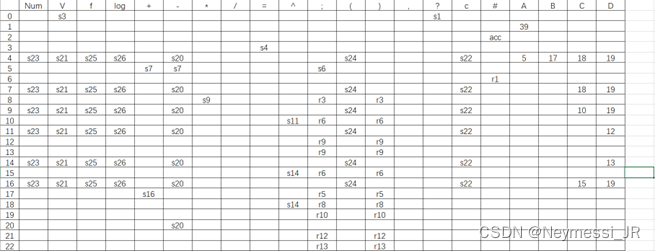
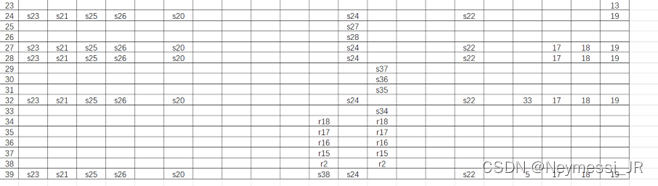
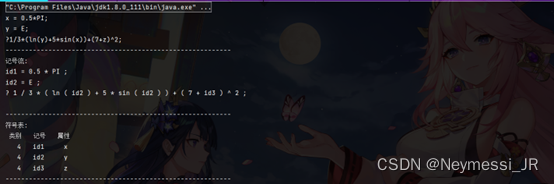
六、实验结果
程序运行结果如下:
(实验编写、运行平台为IDEA)





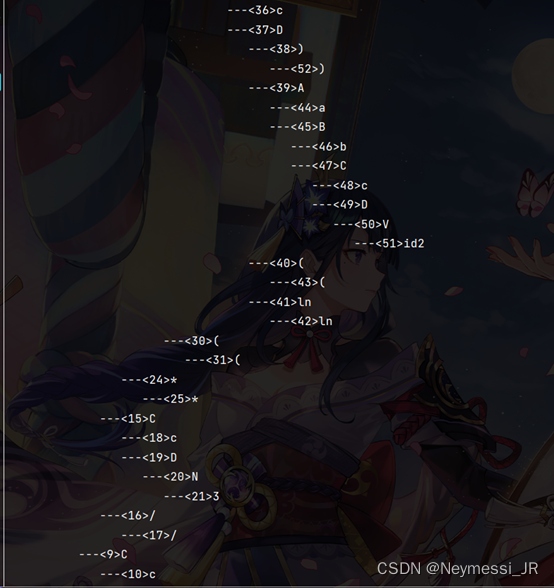
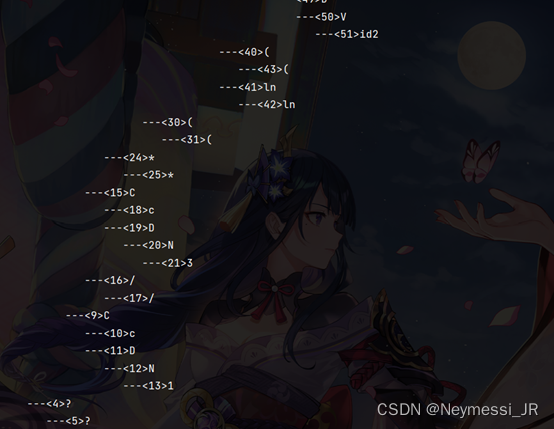
七、词法分析程序主要代码
源程序关键函数代码如下:
打印树结构的驱动器代码:
//驱动器
private static void drivers2(){
//语句切分
String []allSentence = outBuffer.split("\n");
for (int jj = 0;jj<allSentence.length;jj++){
System.out.println("记号流:"+ allSentence[jj]);
Stack<String> stack = new Stack<>();
//初始化栈
stack.push("#");
stack.push("0");
//当前输入记号流
String tempBuffer = allSentence[jj] + "#";
String[] tokenBuffer = tempBuffer.split(" ");
//初始化所有叶子
List<TreeNode> nodes = new ArrayList<TreeNode>();
int id = 0;
for(int i =0 ;i<tokenBuffer.length;i++){
TreeNode temp = new TreeNode(id,tokenBuffer[i]);
nodes.add(temp);
}
//初始化树
TreeUtils tree = new TreeUtils();
String topNode;
int ip = 0;
String[] tempSentence;
String current;
String nextSentence;
TreeNode startNode = new TreeNode(0,"F");
while (ip<tokenBuffer.length && !stack.empty()) {
current = tokenBuffer[ip];
if (names.contains(current)){
current = "V";
}
if(current.charAt(0)>='0'&¤t.charAt(0)<='9'){
current = "N";
}
if(current.charAt(0)=='-' && current.length()>1){
current = "N";
}
if(current=="PI"||current=="E"){
current = "k";
}
if (current == "sin"||current == "cos"||current == "tg"||current == "ctg"||current == "lg"||current == "ln"){
current = "t";
}
int status = Integer.parseInt(stack.pop());
String nextChar = tokenBuffer[ip];
int lie = symbolSet2.get(nextChar);
if(predictsheet2[status][lie].charAt(0)=='s') {
stack.push(tokenBuffer[ip]);
stack.push(predictsheet2[status][lie].substring(1));
}else if(predictsheet2[status][lie].charAt(0)=='r'){
int product = Integer.parseInt(predictsheet2[status][lie].substring(1));
int number = granum[product];
String replace = graleft[product];
List<TreeNode> tempNodes = new ArrayList<TreeNode>();
for(int i = 0;i<product;i++){
String currenceTop = stack.pop();
for(int j= 0;j<nodes.size();j++){
if(currenceTop==nodes.get(j).name){
tempNodes.add(nodes.get(j));
nodes.remove(nodes.get(j));
break;
}
}
}
TreeNode father = new TreeNode(id,replace);
father.sonList = tempNodes;
nodes.add(father);
stack.push(replace);
lie = symbolSet2.get(replace);
stack.push(predictsheet2[status][lie]);
}else if(predictsheet2[status][lie]=="acc"){
startNode = nodes.get(0);
}
else {
System.out.println(current + "erro");
break;
}
}
if(startNode!=null){
System.out.println("success");
System.out.println("其树结构为:");
System.out.println("---" //打印空格 和结点id,name
+"<"+startNode.id+">" + startNode.name);
tree.queryAll(startNode,1);
}
}
}
八、实验心得
在实验中消除了左递归,提取了公共左因子,构造了SLR文法,与LL(1)相比,SLR更简洁易懂,直接根据移进归约表进行选择即可,逻辑清晰。但从工作量上看,LL(1)文法比较简单,SLR在真正去用代码实现和分析的时候要耗费时间。
实验中要求打印语法树,对于此部分我并不是很了解,由于之前没有用过java来创建可视化语法树的做法,所以我上网查阅了Java树结构的相关资料和代码、项目,并且结合了C++的LR语法分析器打印树的过程,遇见了困难还咨询了学长,最终完成了打印语法树的目的,虽然语法树的结构还并不是很直观,但是可以很好地展现出语法结构。
构造移进规约分析表也是本次实验的重点之一。在转换ACTION动作表的过程中,不仅要考虑存储表的结构,还需要考虑到First集、Follow集等数据。而生成GOTO动作表的过程简单于ACTION表,只要根据输入的非终结符查看对应的转移状态即可。通过对这部分的学习的实践,我更加清楚了构造移进归约表的实现过程。
本次实验加深了我对语法分析整体流程的认识,并对其个中概念有了具象化的印象,且对其具体步骤产生了自己的思考,并融入在程序中。















 3082
3082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











