






先贴上np.max()的解释

对于大多数初学者来讲,最容易令人困惑的地方就是axis=0和axis=1的区别。

在实际应用中

这两种方法的结果是一样的,而一些人错误的直接认为axis=0意味着计算两个数组的每列最大值,实际上这是不准确的。确切地讲,axis=0代表的是“沿行操作”,在一些参考书中表达的是“沿着第一个轴操作“这里的第一个轴指的是行。
实际上在numpy中操作的过程大致是这样:
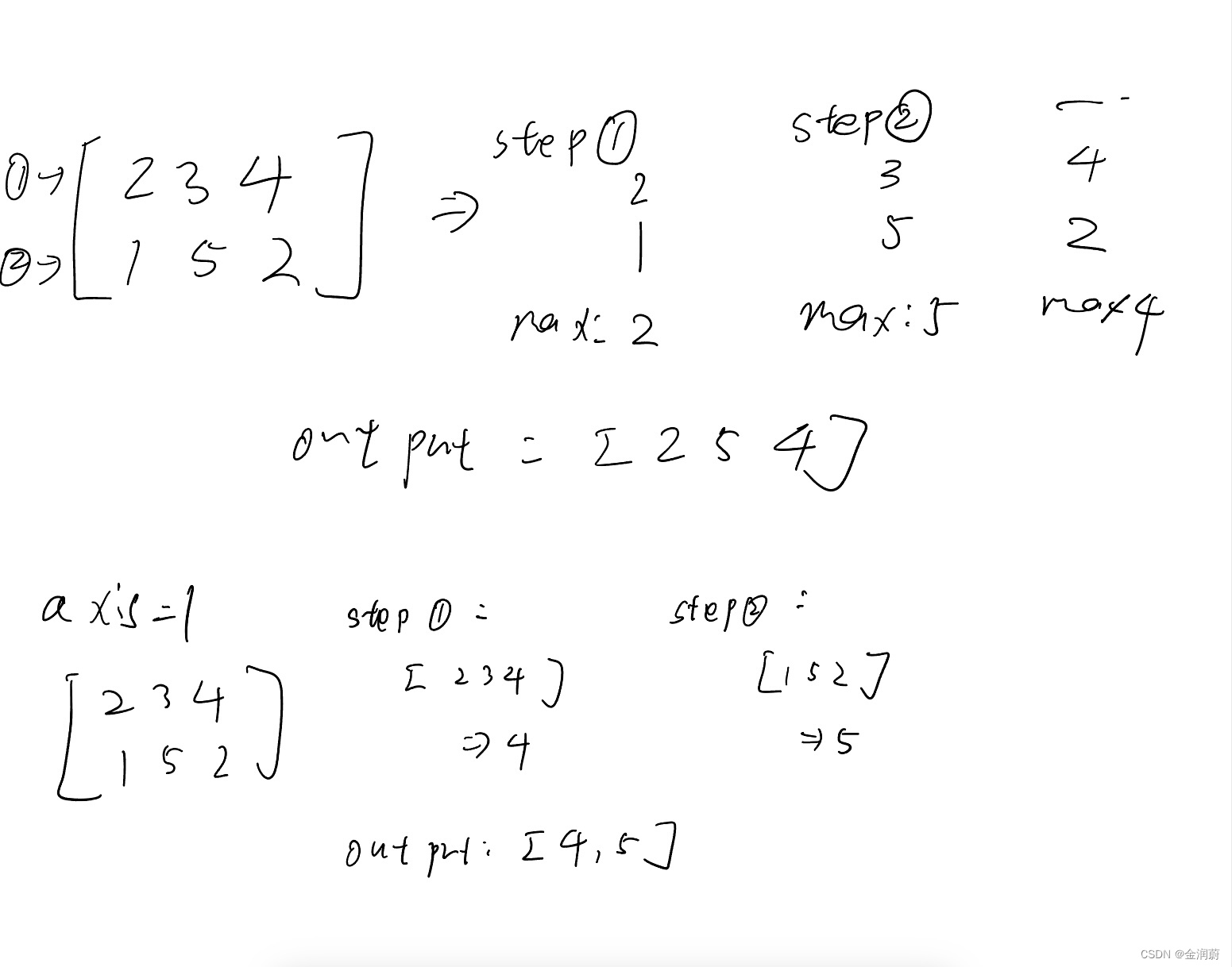
实际上step1和2是同时进行的,这也就是为什么axis = 1 得到的结果是每列的最大值,而axis=0得到的是每行的最大值。

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









