






目录
简介
支持向量机(Support Vector Machine,SVM)是一种基于统计学习理论的监督学习算法,主要用于分类和回归分析。SVM的核心目标是在不同类别的数据之间找到一个最优的分隔超平面,最大化两个类别之间的间隔,从而实现数据的分类。
SVM算法的基本思想是在高维空间中找到一个超平面,使得这个超平面能够最大化两个类别之间的间隔。在低维空间中,数据通常会呈现出一些噪声和异常值,因此需要通过一些方法将数据映射到高维空间中,使得数据更加线性可分。
在SVM算法中,关键的概念包括支持向量、间隔和核函数。支持向量是位于分隔超平面两侧,决定了超平面的位置和形状的点。间隔是分类超平面与支持向量之间的距离,用于衡量分类的准确性。而核函数则用于映射数据到高维空间,常见的核函数包括线性核、多项式核和径向基函数(RBF)等。
SVM算法可以通过对数据进行训练和测试,来评估模型的性能和准确性。在机器学习和人工智能领域中,SVM算法被广泛应用于图像分类、文本分类、生物信息学和金融风险评估等多个领域。SVM算法具有强大的泛化能力和鲁棒性,对噪声和异常值不敏感,可以处理大规模数据集。
一、前提
在介绍SVM之前,先解释几个概念。考虑下图共4个方框中的数据点分布,一个问题就是,能否画出一条直线将圆形点和方形点分开呢?
先考虑图A中的两组数据,它们之间已经分隔得足够开,因此很容易就可以在图中画出一条直线将两组数据点分开。在这种情况下,这组数据被称为线性可分(linearly separable)数据。
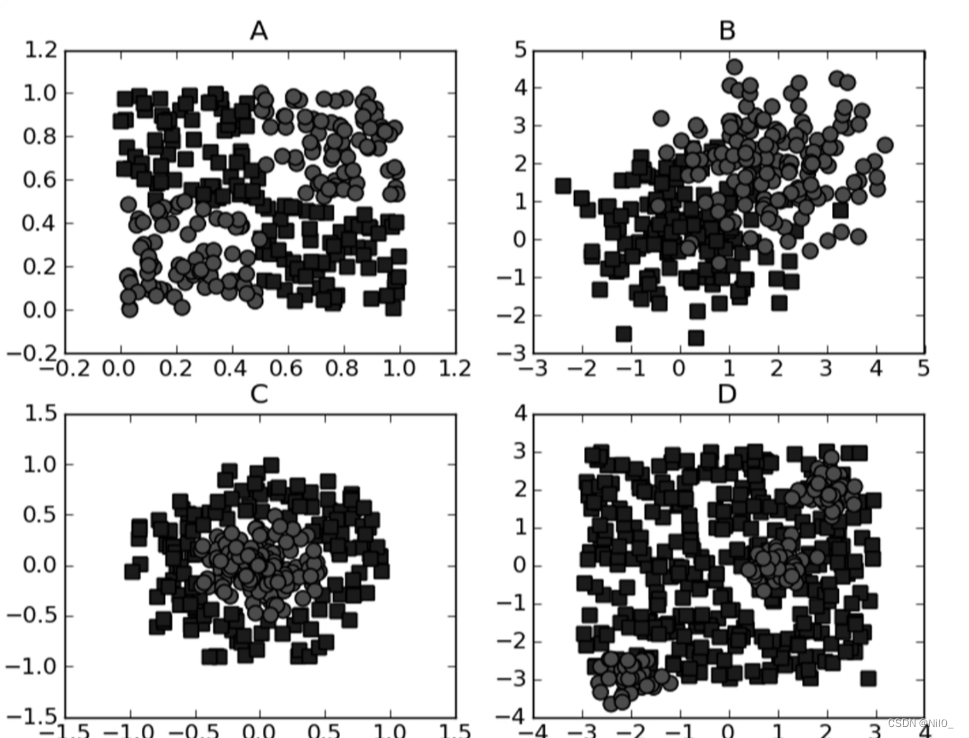
上述将数据集分隔开来的直线称为分隔超平面(separating hyperplane)。如果所给的数据集是三维的,那么此时用来分隔数据的就是一个平面。
显而易见,更高维的情况可以以此类推。如果数据集是N维的,那么就需要一个N-1维的某某对象来对数据进行分隔。这个对象就被称为超平面(hyperplane),也就是分类的决策边界。
支持向量(supp vector)就是距离分隔超平面最近的那些点。接下来要试着最大化支持向量到分隔面的距离,需要找到此问题的优化求解方法。
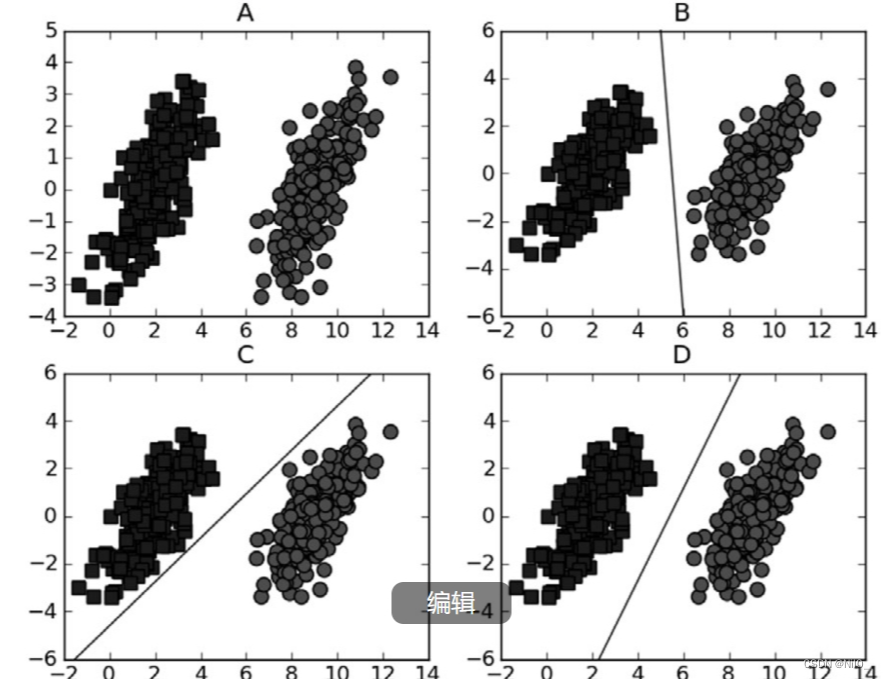
A框中给出了一个线性可分的数据集,B、C、D框中各自给出了一条可以将两类数据分开的直线,问题就是找出那条最优的直线。
二、SVM 的基本原理
1. 超平面:在二维空间中,超平面是一条直线;在三维空间中,它是一个平面;而在更高维度的空间中,它是一个超平面。SVM 的目标就是找到一个最佳的超平面,能够将不同类别的数据点分开
2. 最大间隔:SVM 试图找到一个超平面,使得该超平面到最近的数据点(支持向量)的距离(称为间隔)最大化。这样可以增加分类的鲁棒性和泛化性能
3. 核技巧:在处理非线性可分数据时,SVM 通过核技巧将数据映射到更高维的空间,以便在新的空间中找到一个更好的超平面来分类数据
4. 损失函数和最优化:SVM 通过最小化损失函数和引入正则化项来求解最优的超平面,以得到最佳的分类结果
5. 支持向量:在训练过程中,只有距离超平面最近的一些数据点(支持向量)对最终的超平面有影响,这些数据点决定了最终的分类结果
SVM 的原理涉及到凸优化、间隔最大化以及核技巧等概念,这使得 SVM 能够在实践中取得很好的分类效果。总的来说,SVM 以间隔最大化为目标,通过求解相应的优化问题来找到最佳的分类超平面。
三、寻找最大间隔
寻找最大间隔是支持向量机(SVM)中的一个重要步骤。最大间隔支持向量机(Maximal-Margin Support Vector Machine,MM-SVM)的目标是找到最优超平面,使得不同类别的数据点尽可能地分开,同时最大化两个类别之间的间隔。
在寻找最大间隔的过程中,SVM算法会通过优化一些参数,如正则化参数C和核函数的选择等,来找到最优的超平面。最优超平面的选择会使得支持向量的数量最多,同时最大化两个类别之间的间隔。
具体来说,SVM算法会通过迭代优化超平面的系数,直到找到一个超平面,使得该超平面能够最大化间隔。在每次迭代中,SVM算法会计算当前超平面下不同类别数据点的间隔,并选择其中最大的间隔作为当前的最大间隔。
寻找最大间隔的过程可以通过一些优化算法(如网格搜索、随机搜索等)来实现,也可以通过一些机器学习库(如scikit-learn)中的内置函数来简化实现过程。总之,寻找最大间隔是支持向量机算法中的重要步骤之一,对于提高分类准确性和泛化能力具有重要意义。
四、代码实现
from numpy import *
import matplotlib.pyplot as plt
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
def loadDataSet(filename): # 读取数据
dataMat = []
labelMat = []
data1 = []
data2 = []
data3 = []
data4 = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split(' ')
dataMat.append([float(lineArr[0]),float(lineArr[1])])
labelMat.append(float(lineArr[2]))
lineArr[0] = float(lineArr[0])
lineArr[1] = float(lineArr[1])
lineArr[2] = float(lineArr[2])
if lineArr[2] == 1:
data1.append((lineArr[0]))
data2.append((lineArr[1]))
else:
data3.append((lineArr[0]))
data4.append((lineArr[1]))
x_1 = data1
y_1 = data2
x_2 = data3
y_2 = data4
colors1 = '#00CED1'
colors2 = '#DC143C'
plt.scatter(x_1, y_1, c=colors1, label='有奖学金')
plt.scatter(x_2, y_2, c=colors2, label='无奖学金')
plt.legend()
plt.grid("on")
plt.show()
return dataMat, labelMat # 返回数据特征和数据类别
def selectJrand(i,m): #在0-m中随机选择一个不是i的整数
j=i
while (j==i):
j=int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L): #保证a在L和H范围内(L <= a <= H)
if aj>H:
aj=H
if L>aj:
aj=L
return aj
def kernelTrans(X, A, kTup): #核函数,输入参数,X:支持向量的特征树;A:某一行特征数据;kTup:('lin',k1)核函数的类型和参数
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': #线性函数
K = X * A.T
elif kTup[0]=='rbf': # 径向基函数(radial bias function)
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #返回生成的结果
else:
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
#定义类,方便存储数据
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # 存储各类参数
self.X = dataMatIn #数据特征
self.labelMat = classLabels #数据类别
self.C = C #软间隔参数C,参数越大,非线性拟合能力越强
self.tol = toler #停止阀值
self.m = shape(dataMatIn)[0] #数据行数
self.alphas = mat(zeros((self.m,1)))
self.b = 0 #初始设为0
self.eCache = mat(zeros((self.m,2))) #缓存
self.K = mat(zeros((self.m,self.m))) #核函数的计算结果
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k): #计算Ek(参考《统计学习方法》p127公式7.105)
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
#随机选取aj,并返回其E值
def selectJ(i, oS, Ei):
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0] #返回矩阵中的非零位置的行数
if (len(validEcacheList)) > 1:
for k in validEcacheList:
if k == i:
continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE): #返回步长最大的aj
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k): #更新os数据
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
#首先检验ai是否满足KKT条件,如果不满足,随机选择aj进行优化,更新ai,aj,b值
def innerL(i, oS): #输入参数i和所有参数数据
Ei = calcEk(oS, i) #计算E值
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)): #检验这行数据是否符合KKT条件 参考《统计学习方法》p128公式7.111-113
j,Ej = selectJ(i, oS, Ei) #随机选取aj,并返回其E值
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]): #以下代码的公式参考《统计学习方法》p126
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H:
print("L==H")
return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #参考《统计学习方法》p127公式7.107
if eta >= 0:
print("eta>=0")
return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta #参考《统计学习方法》p127公式7.106
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L) #参考《统计学习方法》p127公式7.108
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < oS.tol): #alpha变化大小阀值(自己设定)
print("j not moving enough")
return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#参考《统计学习方法》p127公式7.109
updateEk(oS, i) #更新数据
#以下求解b的过程,参考《统计学习方法》p129公式7.114-7.116
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]<oS.C):
oS.b = b1
elif (0 < oS.alphas[j]<oS.C):
oS.b = b2
else:
oS.b = (b1 + b2)/2.0
return 1
else:
return 0
#SMO函数,用于快速求解出alpha
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #输入参数:数据特征,数据类别,参数C,阀值toler,最大迭代次数,核函数(默认线性核)
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m): #遍历所有数据
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)) #显示第多少次迭代,那行特征数据使alpha发生了改变,这次改变了多少次alpha
iter += 1
else:
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs: #遍历非边界的数据
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas
def testRbf(data_train,data_test):
dataArr,labelArr = loadDataSet(data_train) #读取训练数据
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', 1.3)) #通过SMO算法得到b和alpha
datMat=mat(dataArr)
labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas)[0] #选取不为0数据的行数(也就是支持向量)
sVs=datMat[svInd] #支持向量的特征数据
labelSV = labelMat[svInd] #支持向量的类别(1或-1)
print("there are %d Support Vectors" % shape(sVs)[0]) #打印出共有多少的支持向量
m,n = shape(datMat) #训练数据的行列数
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', 1.3)) #将支持向量转化为核函数
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b #这一行的预测结果(代码来源于《统计学习方法》p133里面最后用于预测的公式)注意最后确定的分离平面只有那些支持向量决定。
if sign(predict)!=sign(labelArr[i]): #sign函数 -1 if x < 0, 0 if x==0, 1 if x > 0
errorCount += 1
print("the training error rate is: %f" % (float(errorCount)/m)) #打印出错误率
dataArr_test,labelArr_test = loadDataSet(data_test) #读取测试数据
errorCount_test = 0
datMat_test=mat(dataArr_test)
labelMat = mat(labelArr_test).transpose()
m,n = shape(datMat_test)
for i in range(m): #在测试数据上检验错误率
kernelEval = kernelTrans(sVs,datMat_test[i,:],('rbf', 1.3))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr_test[i]):
errorCount_test += 1
print("the test error rate is: %f" % (float(errorCount_test)/m))
if __name__=='__main__':
filename_traindata='./ch5/grade_train.txt'
filename_testdata='./ch5/grade_test.txt'
testRbf(filename_traindata,filename_testdata)五、总结
SVM算法的作用与优点
SVM算法主要用于解决分类和回归问题。具体来说,SVM的作用包括:
1. 分类问题:SVM可以用来将数据分为两个或多个类别。通过找到一个最佳的超平面,将不同类别的数据点分开,实现对数据的分类。SVM还可以使用核函数来处理非线性分类问题
2. 回归问题:SVM也可以用于解决回归问题。通过设置合适的参数和核函数,SVM能够拟合出非线性的回归曲线,对数据进行回归分析
3. 异常检测:SVM可以用于检测异常值和异常模式,从而在数据挖掘和异常检测方面有较好的应用 总之,SVM算法在解决数据分类、回归和异常检测等问题上具有广泛的应用。
其中, SVM算法的优点包括:
1. 适用性广泛:可以用于分类和回归分析
2. 非线性分类:SVM可以使用核函数对非线性数据进行分类
3. 支持向量:SVM找到的超平面只依赖于少数的支持向量,使得算法更加高效















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









