






介绍
决策树是一种常用的机器学习算法,用于分类和回归问题。它通过构建一棵树状结构来对数据进行分类或预测,树上的每个节点代表一个特征或属性,树枝则指向具有最佳属性的样本类别。决策树算法通过递归地将数据集划分为更小的子集来构建决策树,每个子集都使用相同的属性进行划分,直到满足停止条件,如子集中所有样本都属于同一类别或样本数量太少。
一、决策树是什么
决策树是一种常用的机器学习算法,用于分类和回归问题。它通过构建一棵树状结构来对数据进行分类或预测,树上的每个节点代表一个特征或属性,树枝则指向具有最佳属性的样本类别。决策树算法通过递归地将数据集划分为更小的子集来构建决策树,每个子集都使用相同的属性进行划分,直到满足停止条件,如子集中所有样本都属于同一类别或样本数量太少。
决策树的优点包括:
1. 易于理解和解释。
2. 对数据噪声和异常值不敏感。
3. 适合处理大规模数据集。
然而,决策树也存在一些缺点:
1. 容易过拟合,即模型在训练数据上表现良好,但在测试数据上表现不佳。
2. 决策树的剪枝需要人工干预,需要一定的专业知识。
常见的决策树算法包括ID3、C4.5和CART等。这些算法通过不同的方式来评估特征选择和划分标准,以提高决策树的性能和泛化能力。在构建决策树后,可以使用各种方法对树进行剪枝,如预剪枝和后剪枝等。剪枝后的决策树可以用于分类或回归任务,并可以与其他机器学习算法结合使用,以提高模型的性能和泛化能力。
1-1、决策树学习基本算法
决策树学习的目的是为了产生一颗泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide-and-conquer)策略,如下图所示:

1-2、特征选择
由"分而治之"算法可看出,决策树学习的关键是第8行,即如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高。
1-3、信息熵
“信息熵”(information entrop)是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为(k=1,2,3,...,|y|),则D的信息熵定义为:
![]()
Ent(D)的值越小,则D的纯度越高。
1-4、信息增益
一般而言,“信息增益”(information gain)越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。信息增益定义为:
![]()
著名的ID3决策树学习算法就是以信息增益为准则来选择划分属性。
二、决策树的构建
决策树的构建是一个递归的过程,通常包括以下步骤:
1. **特征选择**:选择一个最优的特征进行数据集的分割。特征选择的方法包括信息增益、信息增益率、基尼不纯度等。
2. **数据分割**:根据选择的特征将数据集划分为子集,每个子集使用相同的特征进行划分。
3. **递归构建决策树**:对每个子集递归地进行上述过程,直到满足停止条件(例如子集中所有样本都属于同一类别或样本数量太少)。
4. **剪枝**:为了防止过拟合,对决策树进行剪枝。可以通过预剪枝(在决策树构建过程中就减少树的生长)或后剪枝(在树完全生长后,通过删除那些不能提高测试数据集准确性的分支来减小模型复杂度)两种方式进行。
2-1、决策树模型构建
在决策树的构建过程中,选择的特征会影响到最终的分类结果和模型的泛化能力。因此,特征选择是决策树构建过程中的关键步骤。不同的特征选择方法可以用于优化决策树的性能,如考虑数据的分布、类别之间的差异性、连续特征的选择等。最终构建出的决策树应具有良好的泛化能力,能够在未见数据上得到准确的预测结果。
决策树的构建可以使用各种编程语言来实现,这里我提供一个使用Python和scikit-learn库的决策树构建示例:
#创建决策树
def createDecideTree(dataSet, featName):
#数据集的分类类别
classList = [dataVec[-1] for dataVec in dataSet]
#所有样本属于同一类时,停止划分,返回该类别
if len(classList) == classList.count(classList[0]):
return classList[0]
#所有特征已经遍历完,停止划分,返回样本数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
#选择最好的特征进行划分
bestFeat = chooseBestFeatToSplit(dataSet)
beatFestName = featName[bestFeat]
del featName[bestFeat]
#以字典形式表示树
DTree = {beatFestName:{}}
#根据选择的特征,遍历该特征的所有属性值,在每个划分子集上递归调用createDecideTree
featValue = [dataVec[bestFeat] for dataVec in dataSet]
featValue = set(featValue)
for value in featValue:
subFeatName = featName[:]
DTree[beatFestName][value] = createDecideTree(splitDataSet(dataSet,bestFeat,value), subFeatName)
return DTree
#print(createDecideTree(dataset,dataLabels))
这个示例使用了鸢尾花数据集(iris dataset),这是一个常用的多类分类问题数据集。我们首先加载数据集,然后将其划分为训练集和测试集。接下来,我们创建一个决策树分类器对象,并用训练集对其进行训练。最后,我们使用测试集进行预测,并计算准确率。
这只是一个基本的决策树构建示例,实际应用中可能需要对模型进行更复杂的优化和调整。例如,可以使用交叉验证来选择最佳的参数,或者使用更复杂的特征选择方法来提高模型的性能。
2-2、信息熵的计算
信息熵(Entropy)是衡量数据集纯度的物理量,它可以帮助我们选择最优的特征进行决策树的分割。信息熵的计算涉及到每个类别的概率和对数运算。 对于一个分类问题,假设有N个类别,记为C_1, C_2, ..., C_N,对应的概率分别为p_1, p_2, ..., p_N。则信息熵的计算公式为:
其中,$H(X)$表示数据集的熵。 以下是使用Python代码计算信息熵的示例:
#计算给定数据集的香农熵
def calcShannonEnt(dataSet):
#数据总个数
totalNum = len(dataSet)
#类别集合
labelSet = {}
#计算每个类别的样本个数
for dataVec in dataSet:
label = dataVec[-1]
if label not in labelSet.keys():
labelSet[label] = 0
labelSet[label] += 1
shannonEnt = 0
#计算熵值
for key in labelSet:
pi = float(labelSet[key])/totalNum
shannonEnt -= pi*math.log(pi,2)
return shannonEnt
#print(dataset,'\n')
#print(dataLabels,'\n')
#print(calcShannonEnt(dataset))
#按给定特征划分数据集:返回第featNum个特征其值为value的样本集合,且返回的样本数据中已经去除该特征
def splitDataSet(dataSet, featNum, featvalue):
retDataSet = []
#numpy数据类型转为python列表
if isinstance(dataSet,list) == False:
dataSet = dataSet.tolist()
for dataVec in dataSet:
if dataVec[featNum] == featvalue:
splitData = dataVec[:featNum]
splitData.extend(dataVec[featNum+1:])
retDataSet.append(splitData)
return retDataSet
#选择最好的特征划分数据集
def chooseBestFeatToSplit(dataSet):
featNum = len(dataSet[0]) - 1
maxInfoGain = 0
bestFeat = -1
#计算样本熵值,对应公式中:H(X)
baseShanno = calcShannonEnt(dataSet)
#以每一个特征进行分类,找出使信息增益最大的特征
for i in range(featNum):
featList = [dataVec[i] for dataVec in dataSet]
featList = set(featList)
newShanno = 0
#计算以第i个特征进行分类后的熵值,对应公式中:H(X|Y)
for featValue in featList:
subDataSet = splitDataSet(dataSet, i, featValue)
prob = len(subDataSet)/float(len(dataSet))
newShanno += prob*calcShannonEnt(subDataSet)
#ID3算法:计算信息增益,对应公式中:g(X,Y)=H(X)-H(X|Y)
infoGain = baseShanno - newShanno
#C4.5算法:计算信息增益比
#infoGain = (baseShanno - newShanno)/baseShanno
#找出最大的熵值以及其对应的特征
if infoGain > maxInfoGain:
maxInfoGain = infoGain
bestFeat = i
return bestFeat
# 如果决策树递归生成完毕,且叶子节点中样本不是属于同一类,则以少数服从多数原则确定该叶子节点类别
def majorityCnt(labelList):
labelSet = {}
# 统计每个类别的样本个数
for label in labelList:
if label not in labelSet.keys():
labelSet[label] = 0
labelSet[label] += 1
# iteritems:返回列表迭代器
# operator.itemgeter(1):获取对象第一个域的值
# True:降序
sortedLabelSet = sorted(labelSet.items(), key=operator.itemgetter(1), reverse=True)
return sortedLabelSet[0][0]在这个示例中,我们首先定义了一个名为entropy的函数,它接受一个标签的数组作为输入,并计算该数组的信息熵。函数中,我们首先使用np.unique()函数获取数组中的唯一标签和对应的计数。然后,我们计算每个标签的概率和对数,并使用np.sum()函数求和。最后返回信息熵的值。 我们使用示例数据来计算信息熵,并打印结果。根据示例数据计算的结果,可以得到Entropy的值为1.0。 请注意,信息熵的值介于0和log2(N)之间,其中N是类别的数量。当数据集的纯度更高时,信息熵的值更接近0。越小的信息熵表示数据越纯,越容易进行分类。
2-3、决策树模型构建
#创建决策树
def createDecideTree(dataSet, featName):
#数据集的分类类别
classList = [dataVec[-1] for dataVec in dataSet]
#所有样本属于同一类时,停止划分,返回该类别
if len(classList) == classList.count(classList[0]):
return classList[0]
#所有特征已经遍历完,停止划分,返回样本数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
#选择最好的特征进行划分
bestFeat = chooseBestFeatToSplit(dataSet)
beatFestName = featName[bestFeat]
del featName[bestFeat]
#以字典形式表示树
DTree = {beatFestName:{}}
#根据选择的特征,遍历该特征的所有属性值,在每个划分子集上递归调用createDecideTree
featValue = [dataVec[bestFeat] for dataVec in dataSet]
featValue = set(featValue)
for value in featValue:
subFeatName = featName[:]
DTree[beatFestName][value] = createDecideTree(splitDataSet(dataSet,bestFeat,value), subFeatName)
return DTree
#print(createDecideTree(dataset,dataLabels))输出打印构造的决策树,结果如下:
{'月平均花费': {1: {'家庭平均收入': {1: {'住宿费': {1: 1, 2: 1, 3: 1}}, 2: {'住宿费': {2: 1, 3: 1}}, 3: {'住宿费': {1: 1, 2: 1, 3: 1}}}}, 2: {'住宿费': {1: {'家庭平均收入': {2: 1, 3: 0}}, 2: {'家庭平均收入': {1: 1, 2: 1, 3: 1}}, 3: {'家庭平均收入': {1: 1, 2: 0}}}}, 3: 0}}
2-4、决策树可视化
#获取叶节点的数目和树的层数
def getNumLeafs(tree):
numLeafs = 0
#获取第一个节点的分类特征
firstFeat = list(tree.keys())[0]
#得到firstFeat特征下的决策树(以字典方式表示)
secondDict = tree[firstFeat]
#遍历firstFeat下的每个节点
for key in secondDict.keys():
#如果节点类型为字典,说明该节点下仍然是一棵树,此时递归调用getNumLeafs
if type(secondDict[key]).__name__== 'dict':
numLeafs += getNumLeafs(secondDict[key])
#否则该节点为叶节点
else:
numLeafs += 1
return numLeafs
#获取决策树深度
def getTreeDepth(tree):
maxDepth = 0
#获取第一个节点分类特征
firstFeat = list(tree.keys())[0]
#得到firstFeat特征下的决策树(以字典方式表示)
secondDict = tree[firstFeat]
#遍历firstFeat下的每个节点,返回子树中的最大深度
for key in secondDict.keys():
#如果节点类型为字典,说明该节点下仍然是一棵树,此时递归调用getTreeDepth,获取该子树深度
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#画出决策树
def createPlot(tree):
# 定义一块画布,背景为白色
fig = plt.figure(1, facecolor='white')
# 清空画布
fig.clf()
# 不显示x、y轴刻度
xyticks = dict(xticks=[], yticks=[])
# frameon:是否绘制坐标轴矩形
createPlot.pTree = plt.subplot(111, frameon=False, **xyticks)
# 计算决策树叶子节点个数
plotTree.totalW = float(getNumLeafs(tree))
# 计算决策树深度
plotTree.totalD = float(getTreeDepth(tree))
# 最近绘制的叶子节点的x坐标
plotTree.xOff = -0.5 / plotTree.totalW
# 当前绘制的深度:y坐标
plotTree.yOff = 1.0
# (0.5,1.0)为根节点坐标
plotTree(tree, (0.5, 1.0), '')
plt.show()
# nodeText:要显示的文本;centerPt:文本中心点,即箭头所在的点;parentPt:指向文本的点;nodeType:节点属性
# ha='center',va='center':水平、垂直方向中心对齐;bbox:方框属性
# arrowprops:箭头属性
# xycoords,textcoords选择坐标系;axes fraction-->0,0是轴域左下角,1,1是右上角
def plotNode(nodeText, centerPt, parentPt, nodeType):
createPlot.pTree.annotate(nodeText, xy=parentPt, xycoords="axes fraction",
xytext=centerPt, textcoords='axes fraction',
va='center', ha='center', bbox=nodeType, arrowprops=arrow_args)
def plotMidText(centerPt, parentPt, midText):
xMid = (parentPt[0] - centerPt[0]) / 2.0 + centerPt[0]
yMid = (parentPt[1] - centerPt[1]) / 2.0 + centerPt[1]
createPlot.pTree.text(xMid, yMid, midText)
def plotTree(tree, parentPt, nodeTxt):
#计算叶子节点个数
numLeafs = getNumLeafs(tree)
#获取第一个节点特征
firstFeat = list(tree.keys())[0]
#计算当前节点的x坐标
centerPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
#绘制当前节点
plotMidText(centerPt,parentPt,nodeTxt)
plotNode(firstFeat,centerPt,parentPt,decisionNode)
secondDict = tree[firstFeat]
#计算绘制深度
plotTree.yOff -= 1.0/plotTree.totalD
for key in secondDict.keys():
#如果当前节点的子节点不是叶子节点,则递归
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key],centerPt,str(key))
#如果当前节点的子节点是叶子节点,则绘制该叶节点
else:
#plotTree.xOff在绘制叶节点坐标的时候才会发生改变
plotTree.xOff += 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff,plotTree.yOff),centerPt,leafNode)
plotMidText((plotTree.xOff,plotTree.yOff),centerPt,str(key))
plotTree.yOff += 1.0/plotTree.totalD
#createPlot(createDecideTree(dataset,dataLabels))绘制结果: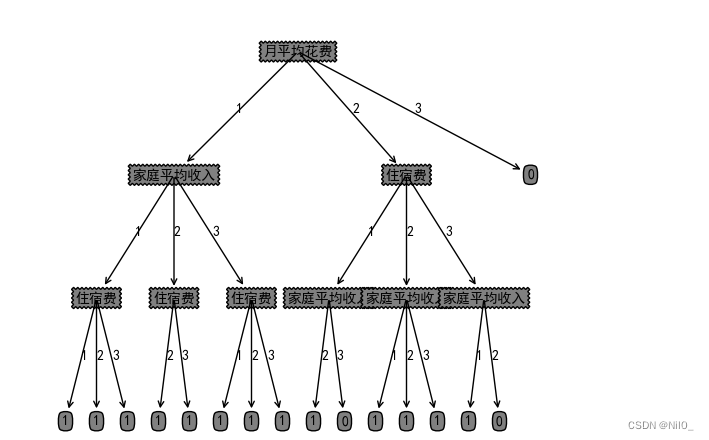
2-5、整体代码
import math #导入一系列数学函数和常量
import operator #比较两个列表, 数字或字符串等的大小关系的函数
import pandas as pd
import matplotlib.pyplot as plt
from pylab import *
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 定义决策节点以及叶子节点属性:boxstyle表示文本框类型,sawtooth:锯齿形;fc表示边框线粗细
decisionNode = dict(boxstyle="sawtooth", fc="0.5")
leafNode = dict(boxstyle="round4", fc="0.5")
# 定义箭头属性
arrow_args = dict(arrowstyle="<-")
data_path = r'data.xlsx'
#读取数据集
def read_excel(path):
raw_data = pd.read_excel(path,header=0)
data = raw_data.values[:,1:5]
return data
#数据离散化
def cut():
#通过read_excel读取excel中的数据
data = read_excel(data_path)
#print(data[:,0])
#print(data[:,1])
#print(data[:,2])
#使用pandas.cut实现对数据的离散化
data[:,0] = pd.cut(data[:,0],[0,300,800,1200,1400],labels=False)
data[:,1] = pd.cut(data[:,1],[0,1000,1300,1600,2000],labels=False)
data[:,2] = pd.cut(data[:,2],[0,5000,8000,10000,12000],labels=False)
#print(data)
return data
#生成数据集
def createDataSet():
dataSet = cut()
labels = ["住宿费","月平均花费","家庭平均收入"]
return dataSet,labels
dataset,dataLabels = createDataSet()
#计算给定数据集的香农熵
def calcShannonEnt(dataSet):
#数据总个数
totalNum = len(dataSet)
#类别集合
labelSet = {}
#计算每个类别的样本个数
for dataVec in dataSet:
label = dataVec[-1]
if label not in labelSet.keys():
labelSet[label] = 0
labelSet[label] += 1
shannonEnt = 0
#计算熵值
for key in labelSet:
pi = float(labelSet[key])/totalNum
shannonEnt -= pi*math.log(pi,2)
return shannonEnt
#print(dataset,'\n')
#print(dataLabels,'\n')
#print(calcShannonEnt(dataset))
#按给定特征划分数据集:返回第featNum个特征其值为value的样本集合,且返回的样本数据中已经去除该特征
def splitDataSet(dataSet, featNum, featvalue):
retDataSet = []
#numpy数据类型转为python列表
if isinstance(dataSet,list) == False:
dataSet = dataSet.tolist()
for dataVec in dataSet:
if dataVec[featNum] == featvalue:
splitData = dataVec[:featNum]
splitData.extend(dataVec[featNum+1:])
retDataSet.append(splitData)
return retDataSet
#选择最好的特征划分数据集
def chooseBestFeatToSplit(dataSet):
featNum = len(dataSet[0]) - 1
maxInfoGain = 0
bestFeat = -1
#计算样本熵值,对应公式中:H(X)
baseShanno = calcShannonEnt(dataSet)
#以每一个特征进行分类,找出使信息增益最大的特征
for i in range(featNum):
featList = [dataVec[i] for dataVec in dataSet]
featList = set(featList)
newShanno = 0
#计算以第i个特征进行分类后的熵值,对应公式中:H(X|Y)
for featValue in featList:
subDataSet = splitDataSet(dataSet, i, featValue)
prob = len(subDataSet)/float(len(dataSet))
newShanno += prob*calcShannonEnt(subDataSet)
#ID3算法:计算信息增益,对应公式中:g(X,Y)=H(X)-H(X|Y)
infoGain = baseShanno - newShanno
#C4.5算法:计算信息增益比
#infoGain = (baseShanno - newShanno)/baseShanno
#找出最大的熵值以及其对应的特征
if infoGain > maxInfoGain:
maxInfoGain = infoGain
bestFeat = i
return bestFeat
# 如果决策树递归生成完毕,且叶子节点中样本不是属于同一类,则以少数服从多数原则确定该叶子节点类别
def majorityCnt(labelList):
labelSet = {}
# 统计每个类别的样本个数
for label in labelList:
if label not in labelSet.keys():
labelSet[label] = 0
labelSet[label] += 1
# iteritems:返回列表迭代器
# operator.itemgeter(1):获取对象第一个域的值
# True:降序
sortedLabelSet = sorted(labelSet.items(), key=operator.itemgetter(1), reverse=True)
return sortedLabelSet[0][0]
'''
'''
#创建决策树
def createDecideTree(dataSet, featName):
#数据集的分类类别
classList = [dataVec[-1] for dataVec in dataSet]
#所有样本属于同一类时,停止划分,返回该类别
if len(classList) == classList.count(classList[0]):
return classList[0]
#所有特征已经遍历完,停止划分,返回样本数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
#选择最好的特征进行划分
bestFeat = chooseBestFeatToSplit(dataSet)
beatFestName = featName[bestFeat]
del featName[bestFeat]
#以字典形式表示树
DTree = {beatFestName:{}}
#根据选择的特征,遍历该特征的所有属性值,在每个划分子集上递归调用createDecideTree
featValue = [dataVec[bestFeat] for dataVec in dataSet]
featValue = set(featValue)
for value in featValue:
subFeatName = featName[:]
DTree[beatFestName][value] = createDecideTree(splitDataSet(dataSet,bestFeat,value), subFeatName)
return DTree
print(createDecideTree(dataset,dataLabels))
'''
'''
#获取叶节点的数目和树的层数
def getNumLeafs(tree):
numLeafs = 0
#获取第一个节点的分类特征
firstFeat = list(tree.keys())[0]
#得到firstFeat特征下的决策树(以字典方式表示)
secondDict = tree[firstFeat]
#遍历firstFeat下的每个节点
for key in secondDict.keys():
#如果节点类型为字典,说明该节点下仍然是一棵树,此时递归调用getNumLeafs
if type(secondDict[key]).__name__== 'dict':
numLeafs += getNumLeafs(secondDict[key])
#否则该节点为叶节点
else:
numLeafs += 1
return numLeafs
#获取决策树深度
def getTreeDepth(tree):
maxDepth = 0
#获取第一个节点分类特征
firstFeat = list(tree.keys())[0]
#得到firstFeat特征下的决策树(以字典方式表示)
secondDict = tree[firstFeat]
#遍历firstFeat下的每个节点,返回子树中的最大深度
for key in secondDict.keys():
#如果节点类型为字典,说明该节点下仍然是一棵树,此时递归调用getTreeDepth,获取该子树深度
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#画出决策树
def createPlot(tree):
# 定义一块画布,背景为白色
fig = plt.figure(1, facecolor='white')
# 清空画布
fig.clf()
# 不显示x、y轴刻度
xyticks = dict(xticks=[], yticks=[])
# frameon:是否绘制坐标轴矩形
createPlot.pTree = plt.subplot(111, frameon=False, **xyticks)
# 计算决策树叶子节点个数
plotTree.totalW = float(getNumLeafs(tree))
# 计算决策树深度
plotTree.totalD = float(getTreeDepth(tree))
# 最近绘制的叶子节点的x坐标
plotTree.xOff = -0.5 / plotTree.totalW
# 当前绘制的深度:y坐标
plotTree.yOff = 1.0
# (0.5,1.0)为根节点坐标
plotTree(tree, (0.5, 1.0), '')
plt.show()
# nodeText:要显示的文本;centerPt:文本中心点,即箭头所在的点;parentPt:指向文本的点;nodeType:节点属性
# ha='center',va='center':水平、垂直方向中心对齐;bbox:方框属性
# arrowprops:箭头属性
# xycoords,textcoords选择坐标系;axes fraction-->0,0是轴域左下角,1,1是右上角
def plotNode(nodeText, centerPt, parentPt, nodeType):
createPlot.pTree.annotate(nodeText, xy=parentPt, xycoords="axes fraction",
xytext=centerPt, textcoords='axes fraction',
va='center', ha='center', bbox=nodeType, arrowprops=arrow_args)
def plotMidText(centerPt, parentPt, midText):
xMid = (parentPt[0] - centerPt[0]) / 2.0 + centerPt[0]
yMid = (parentPt[1] - centerPt[1]) / 2.0 + centerPt[1]
createPlot.pTree.text(xMid, yMid, midText)
def plotTree(tree, parentPt, nodeTxt):
#计算叶子节点个数
numLeafs = getNumLeafs(tree)
#获取第一个节点特征
firstFeat = list(tree.keys())[0]
#计算当前节点的x坐标
centerPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
#绘制当前节点
plotMidText(centerPt,parentPt,nodeTxt)
plotNode(firstFeat,centerPt,parentPt,decisionNode)
secondDict = tree[firstFeat]
#计算绘制深度
plotTree.yOff -= 1.0/plotTree.totalD
for key in secondDict.keys():
#如果当前节点的子节点不是叶子节点,则递归
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key],centerPt,str(key))
#如果当前节点的子节点是叶子节点,则绘制该叶节点
else:
#plotTree.xOff在绘制叶节点坐标的时候才会发生改变
plotTree.xOff += 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff,plotTree.yOff),centerPt,leafNode)
plotMidText((plotTree.xOff,plotTree.yOff),centerPt,str(key))
plotTree.yOff += 1.0/plotTree.totalD
createPlot(createDecideTree(dataset,dataLabels))















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









